




REllU
Members
-
Joined
-
Last visited
Everything posted by REllU
-
I'm in a middle of a backup right now (doing a server upgrade), but yeah. I realized after posting, that there's an option to reboot the LuckyBackup after it's done it's cron-job, which should do the same effect. I'll try that later.
-
Hey, again! I think I stumbled upon a solution by accident for the (LuckyBackup) cron-job not working with the snapshot files! I created a new profile, that I wanted to run every hour or so (for our security cameras, to backup their video footage remotely) While I was doing this, I noticed that the snapshot files were updated successfully! Here's basically the step-by-step on how to get it to work: 1. You need another profile. 2. Set up your cron-jobs the way you want (either within the LuckyBackup itself, or with User Scripts.) 3. Let the cron-job run as it should. 4. Before checking the "manage backup" button within LB, change the profile, and then go back to the profile you're using 5. Check the "manage backup" button, and ta-dah! The snapshot should be updated correctly! Somewhat useless rambling.
-
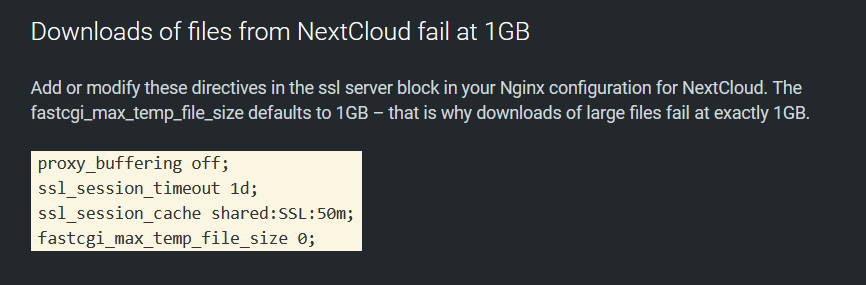
This one slipped through the cracks, just bumping it up EDIT: I think I found the solution, but unsure on how to apply it.. I'm using Nginx Proxy Manager on UnRaid, if that makes any difference. The solution I was able to find from here: https://autoize.com/nextcloud-performance-troubleshooting/ If someone could point me into the right direction, that'd be great!
-
I did try deleting some task's, and creating new ones, resulting in same behavior. Don't know if it's related, and I couldn't really test it, but with previous versions creating new task's wasn't an issue. Could you try creating a 16th task, and see if that works for you or not?
-
I originally had only one profile, and I had 7 task's on it. I tried to add a new one, and the app crashed. I then duplicated the default profile, to try this on another profile, and the crash happened again. On this duplicate profile, I then tried to remove one of the task's, and add a new one. Adding the 7th task went OK (though, once I saved the profile, the app crashed) After this, I tried to add an 8th task into the new profile, and a crash happened again.
-
Hey, It seems that LuckyBackup crashes when I'm adding a new task to a profile after 7 task's. I'm trying to add a remote destination task, not sure if that has anything to do with it or not. Validate and okay- buttons both crash the application.
-
Right, in that case, I might just swap the SSD's entirely, and start the cache from scratch (as again, nothing important was lost with this. I really just wanted to learn how to handle issues like this, should they occur to the main server. But seems that this is a rather rare situation) Just tossing a (probably stupid) idea. Since the SSD is constantly complaining about the missing device 2, would it affect anything if we tried to add in the failing SSD in there, so that the configuration was as it was originally, and then try to do recovery things? (though, that's what we did in the first place, I guess..) Since both of the SSD's were already used, and pretty low-end consumer grade ones, my guess is that both of them were failing, but on a different level. 🤷♂️
-
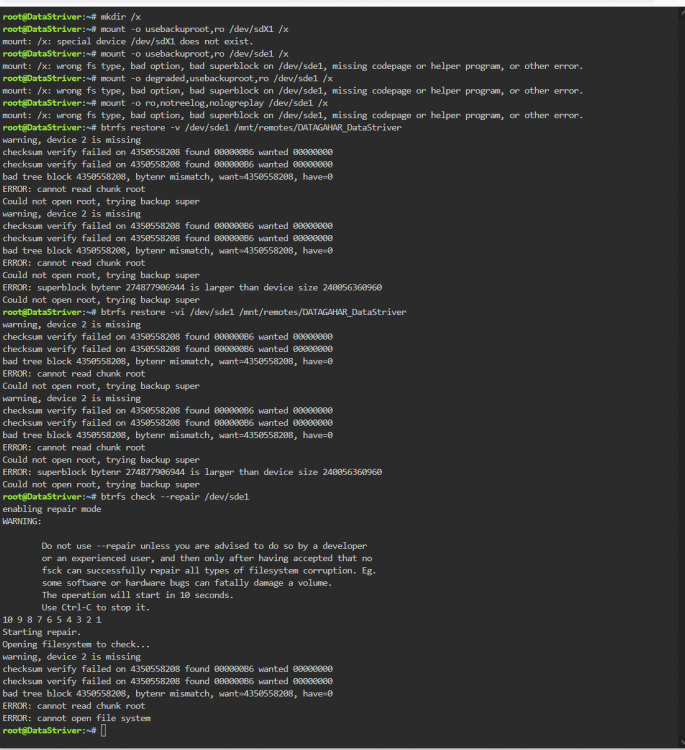
Hey again, took me a while. Moved to a new place after our chat, so things have been a bit hectic. Anyhow! I went through the steps in the thread you showed, and here's the results: I have both of my servers in the same network right now, and I created a new share in to the main server (called "DataStriver") and mounted a remote share on the backup server to it. I mounted the remote share, and then tried to do the backup from SSD to the remote share. I'll throw the diagnostics for you. datastriver-diagnostics-20210901-1528.zip
-
Interesting.. I'll give these a go tomorrow. In the meanwhile, would you have any ideas as of what actually happened here? And if I manage to recover the data from the SSD, should I replace this SSD as well, or would I be able to continue to use it after a format? I am planning to replace both SSD's in the near-ish future with WD Red 500gig ones, that are coming off from the main server, once I've replaced them with 1tb ones. Thanks for all the help so far, and hats off to you with your replying times!
-
So we are getting somewhere I suppose, that's good. Running the code in terminal threw out an error, in attachments. syslog.txt

-
Mount button pretty much just flashes with UD, and it's throwing out errors in log. syslog.txt
-
Still no dice. datastriver-diagnostics-20210823-1858.zip
-
Still unmountable. Diagnostics as attachment. Just to double-check, I did - Stop the array - Un-assign the SSD - Start the array - Stop the array - Assign the working SSD - Start the array once more after I took the diagnostics. Result's being the same. datastriver-diagnostics-20210823-1847.zip
-
Sorry, first time doing this. Here's the (hopefully) correct file(s) datastriver-diagnostics-20210823-1841.zip
-
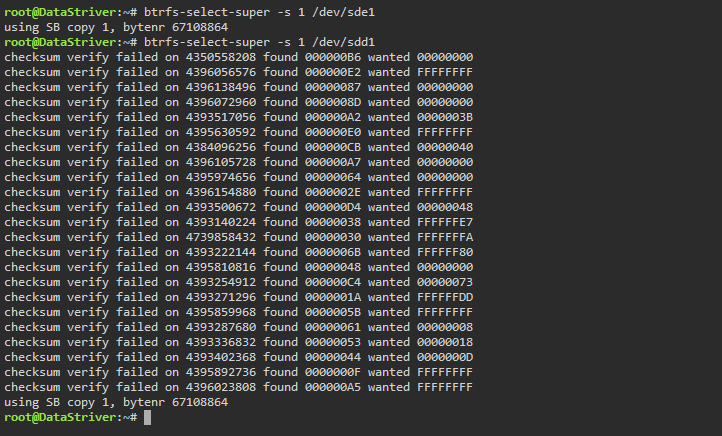
- Stopped the array - While the SSD's were un-assigned, I ran the command above on both SSD's - Only the known-good SSD seemed to be fine with it, the dying one threw some errors (I'll throw a pic of the terminal in attachments) - Rebooted the system (with auto-start disabled), grabbed the diags Both SSD's look like they can be mounted with Un-Assigned Devices- plugin. So that's a good sign.
-
Hey again, so I did what you asked here, and here's the log file. The dying SSD is on Cache 2, the sdd one (Kingston_SV) (EDIT: Removed the log file, in case there was anything sensitive)
-
In that case, only thing I can think of, is that the new SSD was already formatted, and filled with (old) data. Like I said in the original post, UnRaid seemed to be OK after I replaced the SSD. Everything was green, and the new SSD was part of the cache pool just fine. Is there anything else you could think of, why this would've happened?
-
Ah, sorry, I missed a step while I was writing the message. I did un-assign the dying SSD, started the array, and then shut down the server. I guess the oopsie here, was that I didn't change the cache pool to be the size of 1 when I started the array again? If so, that might be worth it to be added on the work-around message, or maybe do a "official" work-around post somewhere?
-
I saw a workaround here Which I wanted to test. This system is our backup server, and there's not a-lot of data in the cache drives, so it's not a huge issue if the data is gone. But as stated in the original message, I just want to learn how to deal with situations like this. I'm also planning to upgrade our main server with bigger SSD cache (from 500gigs to 1tb), so I want to test and see what works and what doesn't with the backup server, before I do anything that cannot be fixed. The bug also seemed to be out there for quite a while, despite how serious it seems. I feel like I've read this exact message somewhere already haha Anyway, I'll do this once I get back home. That'll be in 6-8 hours or so. Appreciate the help. EDIT: Oh also, out of curiosity. What _should_ I do, if a disk / SSD dies on a pool? I have 2 SSD's on both of my servers, as well as a parity drive for the HDD's. Has there been any word from LimeTech about this whole issue? Just seems rather weird to me.
-
EDIT:´As you probably noticed from my original message, I am aware that the 6.9.x has issues with pool device replacements, and that I am willing to post diagnostics, as soon as I know what to do before I download the diagnostics log. As of right now, the server is shut down, and the cache pool doesn't exists, so downloading any diagnostics right now wouldn't really help much I don't think.
-
Hey all, I'll try to keep this one as short and informative as possible. The problem - Cannot mount cache SSD (Unmountable: not mounted) The cause - Replaced a dying Kingston SSD, by un-assigning the SSD from the pool (didn't change the pool size to 1) The system - UnRaid 6.9.2 - Two-ish months old Kingston SE9 USB 2 flash drive - Two old Kingston 240gb SSD's (btrfs, since these were both mounted at the same time) - Non-ecc RAM, 8gigs, tested for 48 hours with MemTest before deployment - DuckDNS installed in Docker. - New, replacement WD Blue SSD, that wasn't formatted after previous use What I did - Un-assigned the dying SSD from the cache pool - Started the array (without changing the cache pool size to 1) - Shut down the server from GUI - Replaced the dying SSD with a new one (from an updated computer, that no-longer needed the SSD) - Started the server, and assigned the new SSD to the Cache 2 slot, where the old SSD was - UnRaid seemed to be happy with this, but the Cache 1 SSD was throwing an error about not finding the old SSD - I trimmed the SSD, and then I tried to perform a full balance - Restarted the server, and noticed the Cache 1 SSD was still throwing the error about the old SSD - I un-assigned the Cache 1 SSD from the pool, because I wanted to make sure everything worked, or not - At this point, UnRaid wasn't able to mount the new SSD anymore. I tried to change the cache pool size to 1, and assigning the new SSD there - Didn't work. Un-assigned the new SSD, removed the cache pool - With un-assigned devices- plugin, I was able to peek into the new SSD, finding that it was still full with Windows 10 stuff from the previous PC - Shut-down the server, removed the new SSD, and put the old one back. - Power on, and try to assign the original SSD's to their original slots, but UnRaid couldn't mount them anymore. What I want - I'd like to restore the original SSD Cache pool, so that I'd be able to replace the cache "the right way" (moving everything away from cache, and then back to the new cache pool) - As far as I know, the data isn't gone. Raid 1 information is just missing, and the SSD's are unmountable Misc info and rambling - I've done a bit of an oopsie when I was building my first UnRaid server, so I knew _not to_ format the SSD's at any point. - This is a backup server for our main server, so it's not a huge loss if the data is gone. But with that said, I want to learn how to handle this. - I really thought that the point of having the RAID 1 cache pool, was that my data would be safe, even if one of the SSD's dies. Now, I'm a little worried about the whole situation, and how UnRaid is handling the whole thing. I'm aware that the 6.9.X version is having issues with replacing the Cache drives, but still. - The server is currently offline, as I didn't want to risk anything weird happening to it, as it is connected with our main server for automatic backups. - I can post a diagnostics log file later today, when I get back home, if it's of any use. However, right now, the server is set up without cache pool, so if you want any meaningful information from the log, please tell me what to do before I download the log and post it here. I hope I didn't miss anything. I tried to look for something similar through the forums for a few hours, and the closest I was able to find, was someone going "oops, I formatted the SSD, now the data is gone" after trying to troubleshoot the issue. Any help would be appreciated, thank you.
-
Seems like quite a few are having issues currently. Probably best if I don't update my NextCloud right now haha! Anyway, I'm having an issue too. Downloading files larger than around 1gb always seem to fail from my NextCloud. I'm using a Ubiquiti USG as my router, I have NextCloud 21.0.1 up and running on UnRaid 6.9.2. PHP Version is currently 7.4.15 Everything else (from what I can tell) is working just fine, and has been for months. To me, this seems like some sort of a setting / limitation somewhere, since the download always seems to stop at that 1gb mark. Any help would be appreciated!
-
Oh, I thought you found out a way to get around it somehow, and pinged me because of that. If that's the case, this really doesn't fix anything for me, since the user-scripts were already doing the same thing, kind of 😅
-
I remember reading about having to run the job when you launch the GUI, so that the cron jobs work, so I've been doing that (y) I force updated now, and so far, it doesn't seem to be working. Might need to nuke the whole thing, and re-install the docker. I should be able to backup the profile file somewhere though, and restore it after the re-install? Setting up the profiles would be a pain in the ass to do >.< EDIT! Waaaaait! I just checked the log files from the AppData folder. It looks like the cron-jobs are working _just_ like the external script was. So, the job indeed does run through (by the looks of it) but the file that stores the snapshots is _not_ updated. EDIT2 Just checked the .luckyBackup / snaps / - folder, and the snapshot files seem to be there, as they should. So the file pointing to the snapshot files (which, if I remember correctly, was the initial issue we were having with the user-scripts as well)
-
I currently have two sets of each schedule-job, one with the console mode, and one without. Neither of them is working. I updated the container two days ago, that's the update where I got the new GUI. (Just in case, checked if there was any more updates left, and no, I'm currently at the latest version) With the latest version, I was finally able to create the cron-jobs, as previously they weren't even created succesfully. Only option left would be to start everything all over again I guess.




