




Commerzpunk
Members
-
Joined
-
Last visited
-
I found this on a german website: https://www.thomas-krenn.com/de/wiki/PCIe_link_lost It says as a solution to use this command in some startup configuration. sed -i '$ s/$/ pcie_aspm.policy=performance/' /etc/kernel/cmdline Is it possible to use it in Unraid? If so, where can i add it?
-
That was the solution for me! Go to the top menu, tools, system devices, unbind the igpu. Reboot, and the plugin works. No, its not. As soon as I bind the igpu again after reboot its not working again. Same as in the screenshots above. Always 0. Who can help please? I relly like to use my igpu in my VMs.
-
Hello, since i changed my harware to a Asus B760I AORUS PRO DDR4 (rev. 1.x) I cant connect to my unraid randomly. Sometimes its fine for 2 weeks, sometimes it cuts out twice a day. I found the following in the logs: Feb 3 01:09:14 unraid-27 kernel: igc 0000:03:00.0 eth0: PCIe link lost, device now detached Feb 3 01:09:14 unraid-27 kernel: ------------[ cut here ]------------ Feb 3 01:09:14 unraid-27 kernel: igc: Failed to read reg 0xc030! Feb 3 01:09:14 unraid-27 kernel: WARNING: CPU: 5 PID: 47 at drivers/net/ethernet/intel/igc/igc_main.c:6482 igc_rd32+0x76/0x8b [igc] Feb 3 01:09:14 unraid-27 kernel: Modules linked in: xt_CHECKSUM ipt_REJECT nf_reject_ipv4 ip6table_mangle ip6table_nat iptable_mangle vhost_net tun vhost vhost_iotlb tap veth xt_nat xt_tcpudp xt_conntrack xt_MASQUERADE nf_conntrack_netlink nfnetlink xfrm_user xfrm_algo iptable_nat nf_nat nf_conntrack nf_defrag_ipv6 nf_defrag_ipv4 xt_addrtype br_netfilter xfs md_mod tcp_diag inet_diag ipmi_devintf i915(O) drm_buddy i2c_algo_bit ttm drm_display_helper drm_kms_helper drm intel_gtt agpgart syscopyarea sysfillrect sysimgblt fb_sys_fops nct6775_core hwmon_vid ip6table_filter ip6_tables iptable_filter ip_tables x_tables efivarfs af_packet 8021q garp mrp bridge stp llc bonding tls zfs(PO) intel_rapl_msr intel_rapl_common iosf_mbi x86_pkg_temp_thermal intel_powerclamp coretemp kvm_intel zunicode(PO) zzstd(O) kvm zlua(O) btusb btrtl btbcm btintel zavl(PO) icp(PO) bluetooth crct10dif_pclmul crc32_pclmul crc32c_intel ghash_clmulni_intel sha512_ssse3 sha256_ssse3 sha1_ssse3 aesni_intel joydev crypto_simd zcommon(PO) Feb 3 01:09:14 unraid-27 kernel: input_leds ecdh_generic cryptd led_class ecc znvpair(PO) i2c_i801 rapl spl(O) mei_hdcp mei_pxp gigabyte_wmi wmi_bmof intel_cstate intel_uncore nvme i2c_smbus ahci mei_me igc nvme_core i2c_core mei libahci thermal fan video tpm_crb tpm_tis tpm_tis_core wmi tpm backlight intel_pmc_core acpi_pad acpi_tad button unix Feb 3 01:09:14 unraid-27 kernel: CPU: 5 PID: 47 Comm: kworker/5:0 Tainted: P U O 6.1.64-Unraid #1 Feb 3 01:09:14 unraid-27 kernel: Hardware name: Gigabyte Technology Co., Ltd. B760I AORUS PRO DDR4/B760I AORUS PRO DDR4, BIOS F9 12/15/2023 Feb 3 01:09:14 unraid-27 kernel: Workqueue: events igc_watchdog_task [igc] Feb 3 01:09:14 unraid-27 kernel: RIP: 0010:igc_rd32+0x76/0x8b [igc] Feb 3 01:09:14 unraid-27 kernel: Code: 8b bb 28 ff ff ff e8 a0 0d 0d e1 84 c0 75 0d 83 c8 ff eb 1a 8b 02 ff c0 75 f5 eb bf 89 ee 48 c7 c7 73 c0 3d a0 e8 2c f9 c9 e0 <0f> 0b eb e1 5b 5d 41 5c c3 cc cc cc cc 83 c8 ff c3 cc cc cc cc 0f Feb 3 01:09:14 unraid-27 kernel: RSP: 0000:ffffc900002cfe00 EFLAGS: 00010286 Feb 3 01:09:14 unraid-27 kernel: RAX: 0000000000000000 RBX: ffff888105078ba8 RCX: 0000000000000027 Feb 3 01:09:14 unraid-27 kernel: RDX: 0000000000000003 RSI: ffffffff820d7e01 RDI: 00000000ffffffff Feb 3 01:09:14 unraid-27 kernel: RBP: 000000000000c030 R08: 0000000000000000 R09: ffffffff82245f10 Feb 3 01:09:14 unraid-27 kernel: R10: 00007fffffffffff R11: ffffffff82966fd6 R12: ffff888105078000 Feb 3 01:09:14 unraid-27 kernel: R13: 000000000000c030 R14: ffff8881018fdc80 R15: 0000000000000000 Feb 3 01:09:14 unraid-27 kernel: FS: 0000000000000000(0000) GS:ffff88889fb40000(0000) knlGS:0000000000000000 Feb 3 01:09:14 unraid-27 kernel: CS: 0010 DS: 0000 ES: 0000 CR0: 0000000080050033 Feb 3 01:09:14 unraid-27 kernel: CR2: 0000154535a05000 CR3: 0000000336152000 CR4: 0000000000752ee0 Feb 3 01:09:14 unraid-27 kernel: PKRU: 55555554 Feb 3 01:09:14 unraid-27 kernel: Call Trace: Feb 3 01:09:14 unraid-27 kernel: <TASK> Feb 3 01:09:14 unraid-27 kernel: ? __warn+0xab/0x122 Feb 3 01:09:14 unraid-27 kernel: ? report_bug+0x109/0x17e Feb 3 01:09:14 unraid-27 kernel: ? igc_rd32+0x76/0x8b [igc] Feb 3 01:09:14 unraid-27 kernel: ? handle_bug+0x41/0x6f Feb 3 01:09:14 unraid-27 kernel: ? exc_invalid_op+0x13/0x60 Feb 3 01:09:14 unraid-27 kernel: ? asm_exc_invalid_op+0x16/0x20 Feb 3 01:09:14 unraid-27 kernel: ? igc_rd32+0x76/0x8b [igc] Feb 3 01:09:14 unraid-27 kernel: igc_update_stats+0x70/0x6ae [igc] Feb 3 01:09:14 unraid-27 kernel: igc_watchdog_task+0x308/0x435 [igc] Feb 3 01:09:14 unraid-27 kernel: process_one_work+0x1a8/0x295 Feb 3 01:09:14 unraid-27 kernel: worker_thread+0x18b/0x244 Feb 3 01:09:14 unraid-27 kernel: ? rescuer_thread+0x281/0x281 Feb 3 01:09:14 unraid-27 kernel: kthread+0xe4/0xef Feb 3 01:09:14 unraid-27 kernel: ? kthread_complete_and_exit+0x1b/0x1b Feb 3 01:09:14 unraid-27 kernel: ret_from_fork+0x1f/0x30 Feb 3 01:09:14 unraid-27 kernel: </TASK> Feb 3 01:09:14 unraid-27 kernel: ---[ end trace 0000000000000000 ]--- What can I do to keep it running reliable? Thank you
-
Hi, I am not familiar with Linux, but I did put the command to the unraids terminal. That's the result: (just like the last page of a lot more messages) [ 346.110367] eth0: renamed from veth610d776 [ 346.136447] IPv6: ADDRCONF(NETDEV_CHANGE): veth8b3bbd4: link becomes ready [ 346.136494] docker0: port 15(veth8b3bbd4) entered blocking state [ 346.136498] docker0: port 15(veth8b3bbd4) entered forwarding state [ 347.767559] docker0: port 16(veth84f9567) entered blocking state [ 347.767565] docker0: port 16(veth84f9567) entered disabled state [ 347.770528] device veth84f9567 entered promiscuous mode [ 348.392266] eth0: renamed from vethf32abb2 [ 348.403357] IPv6: ADDRCONF(NETDEV_CHANGE): veth84f9567: link becomes ready [ 348.403404] docker0: port 16(veth84f9567) entered blocking state [ 348.403408] docker0: port 16(veth84f9567) entered forwarding state [ 393.796257] vethf32abb2: renamed from eth0 [ 393.817391] docker0: port 16(veth84f9567) entered disabled state [ 393.847800] docker0: port 16(veth84f9567) entered disabled state [ 393.848529] device veth84f9567 left promiscuous mode [ 393.848533] docker0: port 16(veth84f9567) entered disabled state [ 1429.196177] hrtimer: interrupt took 27267 ns
-
Hello, i got the same in my Unraid 6.12.6 Got a 12th Gen Intel® Core™ i3-12100 What ever i try, every combination, several restarts, its sticking to 0 and "enable now". Who has an idea how to use this plugin?
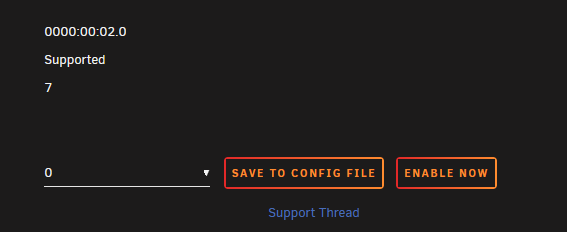
-
Hallo, ich habe nun auch ein B760i Aorus Pro DDR 4 bestellt und testweise laufen. Alles ist wirklich gut, neu, leise und verbrauchsarm soweit. Läuft im Test ohne Platten und NVME mit 10 - 12 Watt. Allerdings auch nach den BIOS Tipps, soweit ich die umsetzen konnte, und powertop --auto-tune auch nur max mit C8. Ich finde nirgends die Option die Geschwindigkeit vom LAN umzustellen, nur um mal zu testen, ob es das sein kann. - Wer kann mir den Tipp geben? Ich finde auch nicht die Option, um die bunten LEDs am Mainboard auszustellen. - Wer kann mir den Tipp geben? Mittlerweile habe ich das neueste F9 BIOS drauf, da heißen einige Optionen anders. Hat schon jemand sein B760i Aorus Pro DDR 4 mit F9 BIOS und guten Energiespareinstellungen als "Vorlage"? Danke!
-
Es ändern sich, sofern ich das mit meinen begrenzten Mitteln rausfinden konnte, die Zeitstempel der Dateien mit . vornedran. Sind das Temp Dateien? Die haben auch alle so seltsame Buchstaben am Ende .5t9HlO usw. Ich habe den Befehl ls -a -l in einem Unterverzeichnis genutzt in dem große Backup-HDD Images reinlaufen sollten. Eine Datei, die keinen Punkt hat, aber von lsof angezeigt wird, zeigt aber z. B. keine Änderung des Zeitstempels. Was sagt mir das nun? Warum kopiert (verschiebt) es so extrem lahm?
-
Hallo, ich kenne mich mit Linux und den Befehlen nur wenig aus, ich hoffe, ich habe es richtig gemacht: Es sind auf jeden Fall die 9 rsync Prozesse am Werk, aber die Dateien sind, wie man trotz Verpixelung wohl sehen kann, alle unterschiedlich. Im Ergebnis sind die Übertragungsraten dadurch halt übelst langsam.

-
Ich denke, es gibt doch eine andere Erklärung: Es könnte ein Bug in dem eingebauten Filemanager sein. Ich habe bisher die 3 großen Verzeichnisse mit z. B. Filmen oder ISOs jeweils einzeln verschoben, das ging schön schnell. Jetzt hatte ich mehrere Verzeichnisse mit vielen kleinen Dateien drin, Fotos, Dokumente und so - diese habe ich alle in einem Rutsch ausgewählt und verschoben: Das sind jetzt 8 Verzeichnisse. Die Geschwindigkeit ist wieder extrem bescheiden, ich habe mal mit htop nachgeschaut und nach rsync gefiltert: Für mich sieht das so aus, als ob der Filemanager je Verzeichnis einen eigenen Befehl absetzt, in dem auch je alle Verzeichnisse enthalten sind. (+ 1 für das Ziel = 9 Prozesse für 8 Quellen und 1 Ziel). Wenn man nach rechts scrollt sieht man das, es ist exakt der gleiche Befehl der jeweils alle im oben Screenshot gewählten Verzeichnisse in einer Reihe hat, und dann als letztes Argument nochmal das Ziel (/mnt/disk1/). Das bedeutet doch, dass die Befehle praktisch gegeneinander kämpfen und die Sache immer langsamer machen, oder?
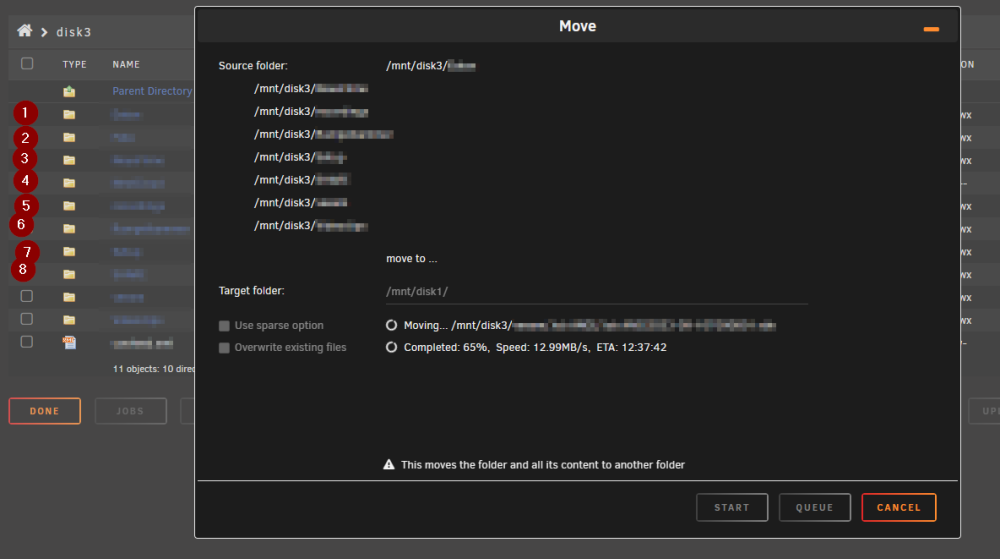

-
Ja, wenn man meine Worte und die aus dem Artikel auf die Goldwaage legt, ist das keine Empfehlung, das stimmt. Die Formulierung "This strategy combines Unraid's array flexibility, allowing for easy capacity expansion, and ZFS's advanced features" klingt halt sehr positiv. Vielleicht liegt es an meinem System, es ist aber ein potenter i5 der 8. Generation mit 32 GB RAM und 3 je 3 Jahre alten SATA Platten. Aber ich habe das Chaos nun durch und es hat ~14 Tage gedauert die 10 TB zu verschieben. Das ist so unterirdisch schlecht, dass ich eine deutlichere Warnung bei den Contras erwarte! Das zurück Verschieben auf die neu formatierte XFS Platte geht nun mit normaler Geschwindigkeit, ca. 3 TB je 24h.
-
Ja, ich lerne da auch gern dazu, Unraid muss man ja auch irgendwie bisschen kennenlernen. @alturismo Ich verstehe nicht, was du mit konstruktiv / nicht konstruktiv meinst, ehrlich gesagt. Wo ich den Kram zu ZFS gelesen habe, war hier: https://unraid.net/blog/zfs-guide Zitat / Auszug: Klingt für mich tatsächlich nach einer Empfehlung, natürlich kommen da noch Contra Punkte, aber abgeraten wird keinesfalls. Und weil das ein offizieller Unraid Artikel ist, dachte mir natürlich das PRO, die Flexibilität des Arrays und die Erweiterten Funktionen von ZFS, nehme ich!
-
Okay, ich glaube dann verstehen wir uns die ganze Zeit irgendwie falsch. Ich benutzt ja gar kein Unbalance, ich wollte, aber es ging ja nicht. Meine aktuellen Verschiebe-Prozesse, siehe oben, sind über den Dynamix File Manager gestartet, und zwar von Disk1 zu Disk3. Wahrscheinlich hatte ich mir mal was falsch im Kopf abgespeichert, ich dachte immer man soll Unraid keinesfalls auf den Platten rumpfuschen, weil das beim Speichern und Ändern von Dateien im Laufenden System das Array durcheinander bringt, weil Unraid ja ne eigenen Logik hat. Ergo, ich könnte die Docker und VMs einfach hochfahren und lasse es weiter kopieren? Wenn ich dann wieder auf xfs umsteige, kann ich das dann ebenso im Hintergrund von disk zu disk kopieren, mit mc, krusader oder sonst was? Wäre wesentlich entspannter als ich das abgespeichert hatte.
-
Okay, danke. Könntest du, oder jemand anderes, etwas konkreter werden? Ich habe immer noch die offene Frage: 1. Muss ich jetzt alles (die Docker und VM) runtergefahren lassen und die x Tage abwarten? 2. Wie ist denn eine konkrete Empfehlung, wenn ich im laufenden Betrieb Daten von Platte 1 auf Platte 2 im Array verlagern möchte? Also praktisch die Verteilung auf den physischen Platten ändern, während in den virtuellen Shares alles gleiche bleibt? Danke euch
-
Okay, vielen Dank für die Antworten, ich werde dann irgendwann wieder auf xfs wechseln. Folgende Fragen sind noch offen: 1. Muss ich jetzt alles runtergefahren lassen und die x Tage abwarten? 2. Krusader finde ich auch gut, hatte aber immer gedacht alles was sich außerhalb der /user/user Shares liegt, also was sich außerhalb der Array Logik abspielt, halt direkt Disk auf Disk, sollte man eben nicht machen? Wie ist denn hier die Empfehlung?
-
Okay, krass, vielen Dank! Unverständlich, warum bei Unraid in den Blogs und in Videos, die ich gesehen habe, die ZFS Implementierung als der nächste riesige Fortschritt propagiert wird. Ich hatte sogar mal einen Beitrag gelesen, der das klassische Array und einen ZFS Pool gegenüber gestellt hat. Ergebnis war: ZFS Pool ist genial super, hat aber den Nachteil, dass immer alle Platten laufen (oder nicht), es auf jeden Fall keinen Spindown einzelner Platten gibt. Als Tipp wurde da gegeben, ein klassisches Array mit ZFS formatierten Platten zu nutzen - das war dann wohl doch nicht so schlau. 🙃 Gut, noch eine Frage: Unbalance erfordert ja in den Voraussetzungen alle Docker und VMs sowie den Mover zu stoppen. Aus Unsicherheit habe ich das nun auch für den Move Prozess gemacht. Mittlerweile nervt mich aber, dass ich keine Dienste und so mehr hab. Kann ich die starten? Oder was ist hier eine gute Empfehlung? Wenn der Transfer erst mal durch ist, kann ich gut mit den langsamen Raten leben, ist ja eher ein typisches Daten- / Medien Archiv. Dann warte ich eher, bis nochmal ein Plattenwechsel ansteht oder so.



