

arch1mede
-
Posts
21 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by arch1mede
-
-
Hi all,
I actually went to linuxserver.io channel, they said to come here, then when I mentioned what was said to come back here, they made mention to using the #other-support where no one else responded.
Just wanted to provide a small update. I still do not have this working. Some kind soul took pity on me and as a test found that he too was having the same issue BUT he was able to resolve his issue, I tried his fix and this did not fix my issue.
I tried the reset pass method that someone else pointed to with no effect. I was told the issue was the fact that some of the dockers in the container were resetting all of the time, right now the kasm.api docker is resetting 1 time a min.
I tried to redeploy using /mnt/user/appdata/kasmdata path, then was told that was a fuse mount issue to try /mnt/cache/appdata/kasmdata, this also did not work.
I tried to deploy using /mnt/disk2/kasm, same behavior
I tried PUID 99 and PGUID 100, same behavior
In all cases the kasm.api docker keeps resetting
Executing /usr/bin/kasm_server.so Received config /opt/kasm/current/conf/app/api.app.config.yaml Using parameters --enable-admin-api --enable-client-api --enable-public-api cheroot/__init__.py:13: UserWarning: Module cheroot was already imported from /tmp/_MEIjFKZpX/cheroot/__init__.pyc, but /tmp/_MEIjFKZpX/cheroot-8.6.0-py3.8.egg is being added to sys.path cheroot/__init__.py:13: UserWarning: Module more_itertools was already imported from /tmp/_MEIjFKZpX/more_itertools/__init__.pyc, but /tmp/_MEIjFKZpX/more_itertools-8.12.0-py3.8.egg is being added to sys.path cherrypy/__init__.py:112: UserWarning: Module cherrypy was already imported from /tmp/_MEIjFKZpX/cherrypy/__init__.pyc, but /tmp/_MEIjFKZpX/CherryPy-18.1.1-py3.8.egg is being added to sys.path cherrypy/__init__.py:112: UserWarning: Module portend was already imported from /tmp/_MEIjFKZpX/portend.pyc, but /tmp/_MEIjFKZpX/portend-2.6-py3.8.egg is being added to sys.path cherrypy/__init__.py:112: UserWarning: Module tempora was already imported from /tmp/_MEIjFKZpX/tempora/__init__.pyc, but /tmp/_MEIjFKZpX/tempora-5.0.1-py3.8.egg is being added to sys.path 2022-10-28 13:00:48,054 [INFO] root: Performing Database Connectivity Test 2022-10-28 13:00:48,578 [INFO] root: Added Log Handler 2022-10-28 13:00:53,442 [INFO] admin_api_server: AdminApi initialized 2022-10-28 13:00:53,500 [DEBUG] admin_api_server: Provider Manager Initialized 2022-10-28 13:00:53,525 [DEBUG] client_api_server: Provider Manager Initialized TerminatedIn each case I get login failed and can never access kasm. I cannot get any help from anyone so I have lost hope.
I don't have anything special on my unraid, its almost default except with some addons for the gui, it is running 6.10.0 though as I cannot get the latest version to actually run correctly, so I rolled it back to this version.
-
I would post this in the container sub-section but I am unable to find it.
Has anyone installed this docker container? I have it installed but cannot log into it as none of the credentials work.
I have tried '[email protected]' and '[email protected]' with a password during the install wizard but I am getting invalid login.
Does anyone else have any suggestions?
-
Anyways, have there been any other reports of Unraid locking up?
-
1 minute ago, trurl said:
You mean the terminal in the Unraid webUI?
Ahhhhh ok, I see now. Thank you.
-
1 minute ago, trurl said:
Are you running that on the attached monitor and keyboard or from telnet/ssh?
Using this from the webterm, this system has no monitor but has an IPMI. I can see that the screen is blanked due to when I rolled this back to a known working version, 6.10.0.
-
On 6/13/2022 at 8:35 AM, JorgeB said:
To disable that add 'setterm -blank 0' to /boot/config/go
setterm --blank 0
setterm: terminal xterm-256color does not support ---blank -
Ever since going to the latest version, Unraid has become unresponsive, IPMI shows nothing on the screen and I have to reboot it to show anything. Anyone else have this same behavior?
it seems that the screen is/was blanked, anyone know how to disable this? setterm does not support --blank
-
On 7/6/2021 at 8:17 PM, freakytoad1 said:
What would 'process_name' be in this case? nginx?
Honestly, no idea. I couldn't tell.
-
2 hours ago, jonathanm said:
Only major issues when the drive is unmountable or disabled (two separate issues with two separate indicators) show up on the main GUI. File system corruption minor enough that the drive still mounts don't show up there currently.
I'm probably going to submit a feature request, it may or may not ever get any attention.
For me md1 was mounting but showing up like: d?????????????? so it would have been good to know that there was an issue with the mount point.
-
19 hours ago, jonathanm said:
The green status indicators means the drive hasn't returned any write errors. Nothing to do with the validity of any filesystem on the drive.
Yes I realize that but not sure how I am supposed to know there is an issue if I have to check multiple places.
-
I just wanted to report, this is still present in the latest 6.9.2
Jul 5 09:47:41 UnRaid-Mini-NAS nginx: 2021/07/05 09:47:41 [alert] 8435#8435: worker process 18731 exited on signal 6 Jul 5 09:47:43 UnRaid-Mini-NAS nginx: 2021/07/05 09:47:43 [alert] 8435#8435: worker process 18756 exited on signal 6 Jul 5 09:47:45 UnRaid-Mini-NAS nginx: 2021/07/05 09:47:45 [alert] 8435#8435: worker process 18801 exited on signal 6 Jul 5 09:47:47 UnRaid-Mini-NAS nginx: 2021/07/05 09:47:47 [alert] 8435#8435: worker process 18828 exited on signal 6I was checking on my parity check and noticed my logs filled with this. I only had 2 windows open, main one and a systems log.
Ran the following:
killall --quiet --older-than 1w process_nameThis seemed to have solved the issue.
-
21 hours ago, arch1mede said:
In my experience the VM solution is slower, besides I have this configured to use its own IP so there shouldn't be any port conflicts. This worked before the most recent update.
I actually figured out the issue, unknown to me, md1 was spitting out xfs errors even though the main page/dashboard showed everything green. As it happens, the lancache-bundle docker has a user setting that pointed to md1 which was really not accessible so wouldn't start. Rebooted the unraid box resolved the issue but not really happy with that solution as I shouldn't have needed to reboot it. As a result, md1 had a xfs error on it so I had to run a parity check on the whole array to resolve the issue, I may still have to put the array into maintenance mode and do a repair but thought id share how this was resolved.
-
On 7/3/2021 at 9:03 AM, xPliZit_xs said:
Hey Guys,
for people with issues with lancache...
I did some research on the original Lancache website and they mention Lancache does not like when certain ports are shared with Lancache e.g.53,80 and 443. This is likely the issue here when running on Unraid assuming you run other containers using any of these ports.
A workaround is to create a VM e.g. ubuntu and install Lancache on that VM. Within that VM Lancache has exclusive access to these ports.
I am currently checking this myself and it looks promising!! My issues went away but still testing more.
A video guide here:
a written guide here:
https://lurkingforgames.com/lancache
I am happy with this and still testing! Also within the lancache folder you can do a "nano .env" and you can see most of the parameters from the Unraid Lancache docker settings. Change them exactly like you had it before.
In my experience the VM solution is slower, besides I have this configured to use its own IP so there shouldn't be any port conflicts. This worked before the most recent update.
-
Recently the docker updated but now refuses to run, all I see now is just an error, anyone have any ideas how to get this running again?
-
OK so I finally found the solution for this
consoleblank=0
cat /sys/module/kernel/parameters/consoleblank should now reflect 0
-
anyone know how to disable the console screen blanking out, I have already tried setterm --blank 0, cat /sys/module/kernel/parameters/consoleblank and its not 0, still saying 900.
The instructions I found were for 6.8.3 so something must have changes for 6.9.0
-
7 hours ago, John_M said:
If it really is the same issue, and you're getting the same error message, then my advice is the same as I gave to @t-mac_003 :
I am using the default paths
-
1 hour ago, juan11perez said:
thank you so much for sharing this info. This has been really irritating. I've run this unraid box for 2 years without any problems, exept the self-inflicted ones
")
I have experienced the same problems as you since installing this docker.
Not sure whats the best way to warn others?
I have no idea...and i'm not sure why others haven't run into this same issue. I went to the support github and there was nothing in issues and I was starting to suspect that 6.9 is the cause. Maybe its a combination of that docker and version?
If it happens again, I will need to downgrade to 6.8.3.
-
2 minutes ago, juan11perez said:
thank you for taking the time. It appears to be this docker
https://github.com/testdasi/grafana-unraid-stack
I installed it about a week ago and trouble seemed to start then. Have you used it?
I had this VERY same docker installed and then all of a sudden, my unraid server started acting weird. First time it locked up was a week ago, just became unresponsive, 2nd time it started to degrade, dashboard stopped displaying anything, docker page stopped displaying anything, stop/start nginx did not resolve anything and the web terminal started saying bad proxy so I just removed that docker.
I have been running dockers for YEARS and have never had a docker effect a server like this.
-
On 3/3/2021 at 4:36 PM, t-mac_003 said:
I followed all the directions up until running the "1_macinabox_helper" script. It gives the following error message.
Does anyone know how I can fix this error?
Many Thanks!

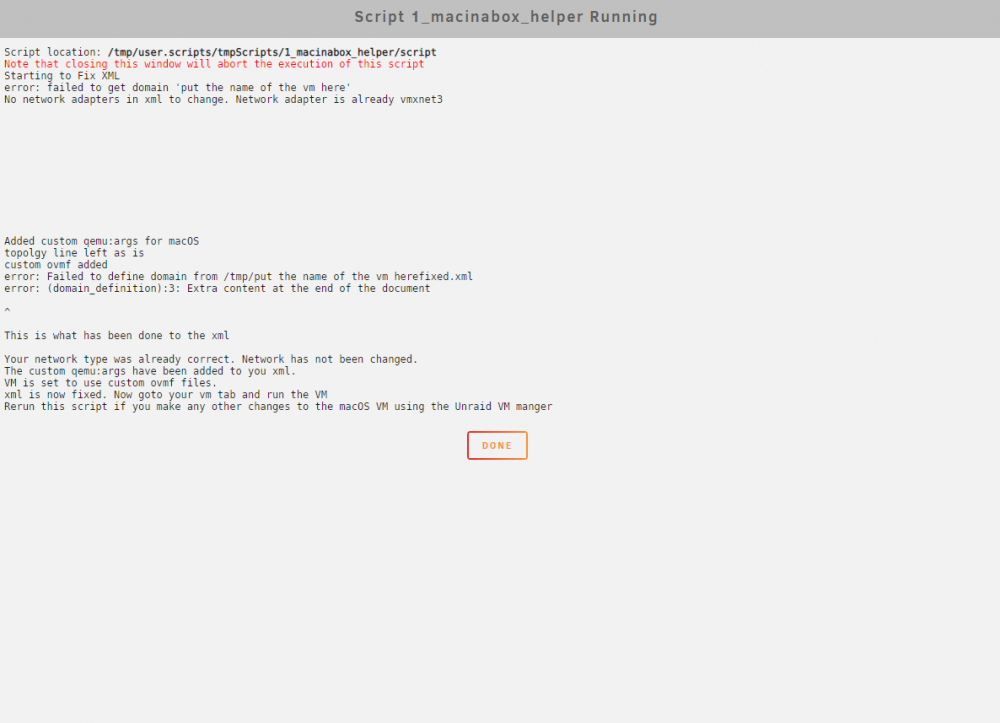
Same issue here, installed macinthebox docker, while following the vid, pressed the notifier and it immediately told me to run the helper script, Pressed it and it said to run the VM and it wasn't there. This is a brand new 6.9.0 install.



KASM Docker help
in General Support
Posted
I tried this, it did not work for me. Sadly.