




thefarelkid
Members
-
Joined
-
Last visited
Everything posted by thefarelkid
-
I can't figure it out. I downgraded to .13 and had the same issues. It's probably not Unraid that's causing my issues. Though again, other servers on the same vlan work fine. I wound up just flattening the network. Everything's working now. Thank's for your help @Vr2Io
-
Yeah, I'm not really sure what happened. I'm running OPNsense with Unifi APs. I set it up years ago and haven't had this kind of issue before. The default for VLANs on OPNsense is to allow traffic between VLANs unless specified to block. I get issues sometimes with mdns, but never resolving a local IP on a different VLAN. I may just flatten the network though. Pretty annoying to do, but it would simplify things.
-
Yes. VLAN on wire is .1 while wifi is .10. So from my laptop connected by Ethernet form 192.168.1.207 or something: works just fine. On wifi 192.168.10.207: that will fail.
-
For clarity, everything is accessible from a wired connection. I can move my laptop on and off of wired and access will bounce between fully accessible to not. Interestingly, the GUI, Docker, and SMB are all affected, while my 1 VM is not. I CAN access my VM on my wifi VLAN.
-
I believe it was after a recent update of Unraid to 6.12.14 I am unable to access anything on my Unraid server from my WLAN vlan. I have wifi and wired set up on separate vlans and haven't had any issues up until recently. I've tried restarting Unraid and several pieces of network infrastructure. I've also tried accessing other web services not on Unraid that are also on the wired vlan and have had no issues connecting to them. I do believe it's something in my Unraid server specifically. gemini-diagnostics-20241224-1607.zip
-
OK, great! I hope that means we're only building for a day and a half and not 3. Yeah. parity1 is 12TB as well. Thank you for your help.
-
I've been having a great time with my unraid array. Long story short, I needed to pull all the drives out and when I plugged them all back in 2 drives wouldn't come back online. 1 is a Parity disk, and the other is just a disk in the array. I have 3 new drives on their way, but wanted to know what drive should I replace and rebuild first, the 2nd Parity, or the Disk? Or is it fine to do both at the same time? They are both 12TB disks, so this is a more than 1 day process at minimum.
-
I think I solved it. I remembered that I have Veeam running on a Windows PC that backs up every night at 12:30. Looks like last night was a rather large job. The target for that backup is a share that utilizes the cache for speed, and then the mover moves it off the cache. But since it's an overnight backup, I will move the target to a new share that doesn't touch the cache at all. Thanks for helping me discover my other issues though. I definitely need to sort out my zfs issues.
-
That was my thought. And you're right about other issues too. This morning the cache pool had returned to normal, but I couldn't get the docker service to start without initiating a full restart. Maybe I could have if I knew hot to do it from the command line. But back when this was a little more regular, the GUI would crash as well. The only thing that I can think that would do that much writing to the cache would be something like SABnzbd. But that hadn't had any activity since 11 last night. Could it be running a backup of my HomeAssistant VM? Those backups are only ~400MB though. No. They don't start running until 2:00am. I'm stumped for now. Is there a way to log the disk utilization by service?
-
That's what I see for disk utilization normally. But overnight I'll get notifications that read: Unraid Cache disk disk utilization Alert [GEMINI] - Cache disk is low on space (100%) Description PCIe_SSD_21010751200007 (nvme1n1) Priority alert. I got that at 1:11am. That was the last one I got. The first one started at 12:41am at 71% and went up from there. I will attempt to restore the sanoid.conf file and run a memtest to be sure. I'm trying to research what a sharecachefloor means, but not getting far.
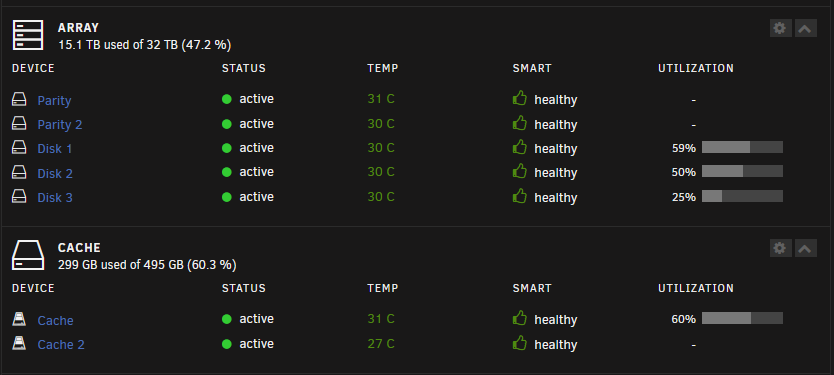
-
Thanks for your help Jorge. Both the main pool and cache don't seem to be too full usually. Main Pool is around 47% and cache is 60%. Also I just noticed I don't have a scrub schedule for my cache pool. Oops. root@Gemini:~# zpool status -v pool: cache state: ONLINE status: One or more devices has experienced an error resulting in data corruption. Applications may be affected. action: Restore the file in question if possible. Otherwise restore the entire pool from backup. see: https://openzfs.github.io/openzfs-docs/msg/ZFS-8000-8A config: NAME STATE READ WRITE CKSUM cache ONLINE 0 0 0 mirror-0 ONLINE 0 0 0 nvme1n1p1 ONLINE 0 0 0 nvme2n1p1 ONLINE 0 0 0 errors: Permanent errors have been detected in the following files: /mnt/cache/system/sanoid/cache_appdata/sanoid.conf
-
This started happening almost a year ago, but hasn't happened for a long while now. I do get docker.img warnings above 70% when I do updates to my dockers, but that is temporary and goes back to normal after updates are complete. But cache disks utilization at 100% is very confusing though as my cache disk is usually about 60%. Diagnostics attached. Thank you for anyone who can help. gemini-diagnostics-20240506-0540.zip
-
Hi all. I have a maybe unique question. How would I go about migrating my existing docker instance of Nextcloud (current image from linuxserver.io) to Unraid? It's currently set up on docker-compose in Proxmox. Search results return tones of tutorials in how to set up a new instance in Docker, and how to transfer from the oldschool install to docker. But nothing that I've found to transfer from 1 docker instance to a new docker instance (this time in Unraid.) Any guidance would be appreciated.

