




leodavinci
Members
-
Joined
-
Last visited
-
Well, look at that. Thanks a ton. I don't think i would have ever found that. The container started, now I just hope I can get the stupid game to connect.
-
So i did all of this and i get an error message that says " /usr/bin/docker: Error response from daemon: Requested CPUs are not available - requested 2,13,18,29, available: 0-1". From my admittedly brief research it looks like a setting that is done when the docker is created. Any suggestions on how I can get around this or fix it?
-
Hey all. Great work on this docker. I've been using it for quite a while with two raspberry pi 2s. Keeping everything in sync and updated. Everything was working fine and I decided to do another pi project. Since then the pi3 had come out and I decided to upgrade my HTPCs to pi3s and repurpose the pi2s. I use OSMC on the pis and their release for the pi3s is v16. So I changed the VERSION variable in the docker to 16, (it wasn't set before) and installed the pis and everything almost just worked. My problem is some of my media is missing from the library. I.e. I have all episodes of a show. They showed up in the TV Shows category on Isengard, but in Jarvis, some of the episodes are missing. I can browse to them in files. The files are there, just not in the library. I tried library update but it didn't do anything. Any suggestions?
-
I have the exact same issue as ScotlandThomas. One more thing. Reading through the thread i saw where you advised someone to rename their err files. So i tried to do that. I went into the container and this is what I got. It looks like the databases folder doesn't exist in the config folder, but when I browse to it from outside the container it is there with some files. root@1d4faab77f3a:/# ps -ef | grep mysql root 18 1 0 23:40 ? 00:00:00 grep --color=auto mysql root@1d4faab77f3a:/# cd /config root@1d4faab77f3a:/config# ls root@1d4faab77f3a:/config# cd /config/databases bash: cd: /config/databases: No such file or directory root@1d4faab77f3a:/config# mysql -u root -p Enter password: ERROR 2002 (HY000): Can't connect to local MySQL server through socket '/var/run/mysqld/mysqld.sock' (2 "No such file or directory") root@1d4faab77f3a:/config# It looks like for some reason the docker isnt seeing the database folder? It exists in the appdata folder where it is supposed to be. I'm pulling my hair out. My appdata is cache only. EDIT: So, I tried the linuxserver mysql docker and Needo's MariaDB docker and they both behave the exact same way with the exact same error message. And all of the log files stop at this line: Starting MariaDB... 151226 20:13:26 mysqld_safe Logging to '/db/mysql_safe.log'. 151226 20:13:26 mysqld_safe Starting mysqld daemon with databases from /db EDIT2: Ok, so after much head scratching and experimenting, I finally have something working. So apparently you cant run the mysql -u root -p command from inside the docker. I had to download MySql Workbench to my desktop, create the xbmc user, give it the permissions and then things started working with the MySql docker.
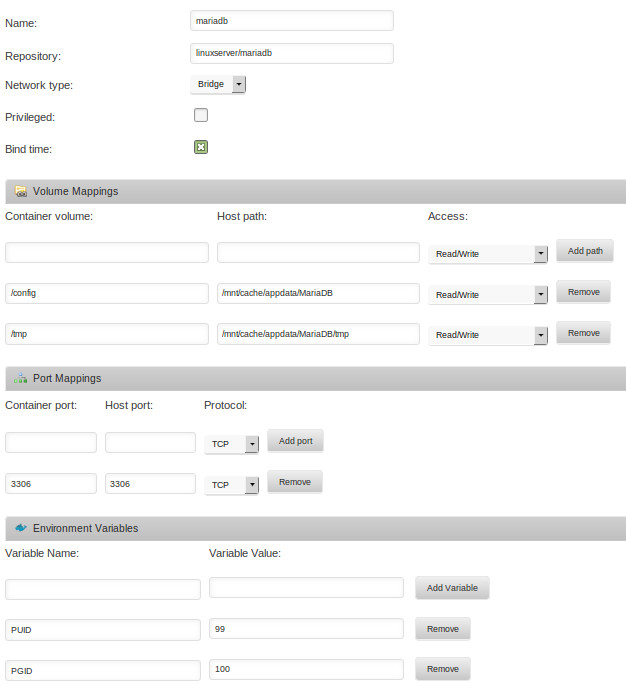
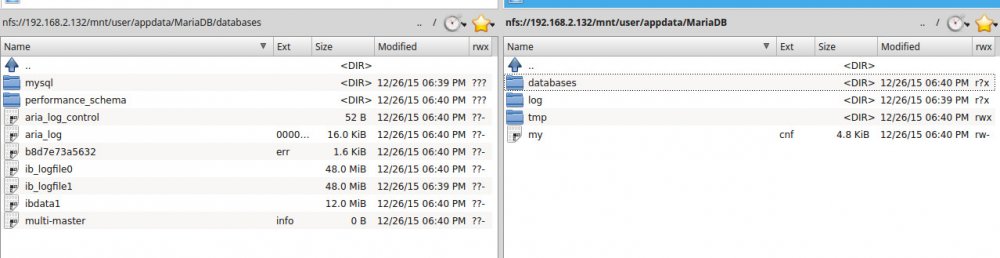
-
Is there any way to get the MineOS docker to update the WebUI so I can use the newer features? I have tried about everything I can think of. I tried the commands inside the container from http://minecraft.codeemo.com/mineoswiki/index.php?title=Updating_the_Webui_%28python%29: both: cd /usr/games/minecraft git fetch git merge origin/master and cd /usr/games/minecraft git fetch git reset --hard origin/master chmod +x server.py mineos_console.py All that does is make my WebUI stop responding and on the rare instance where I got it to briefly work, it didn't seem to change anything. I started down the path of making my own docker, but I've pretty much stalled out. You can see the thread I started for that at http://discourse.codeemo.com/t/creating-mineos-node-in-a-docker/896. Any help anybody can provide with that would be appreciated too, even if I get hernandito's docker working, I want to finish my own for my own education.

