




AGuyInTheWrongRoom
Members
-
Joined
-
Last visited
Everything posted by AGuyInTheWrongRoom
-
Hi everyone, I have recently added a new HDD to the array and happened to update the OS to 6.1.1.5 (and more recently to 6.12.1). At the same time, I started having problems with high CPU usage: after some minutes of uptime, CPU usage would spike to high 90%s and eventually reach 100% and become unresponsive. Docker apps stopped working, GUI unreachable, just had to shut down server manually and power it back on. I checked netdata and apparently IOWAIT is constantly consuming the most resources. When running htop command in terminal I saw... well, I have no idea what I was looking iat. But I'm attaching the pictures and diagnostics. My CPU is an Intel® Core™ i7-4770K CPU @ 3.50GHz. I'm completely at a loss here. Could someone help me solve this problem? mushu-diagnostics-20230624-1310.zip
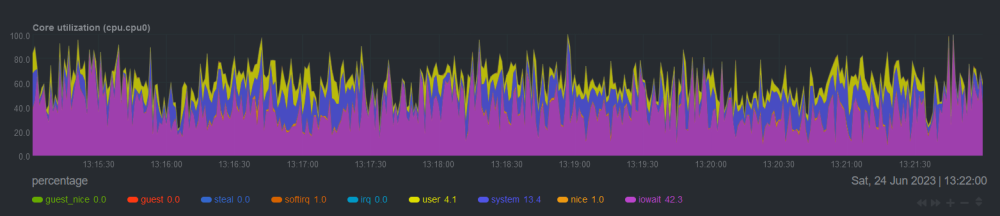
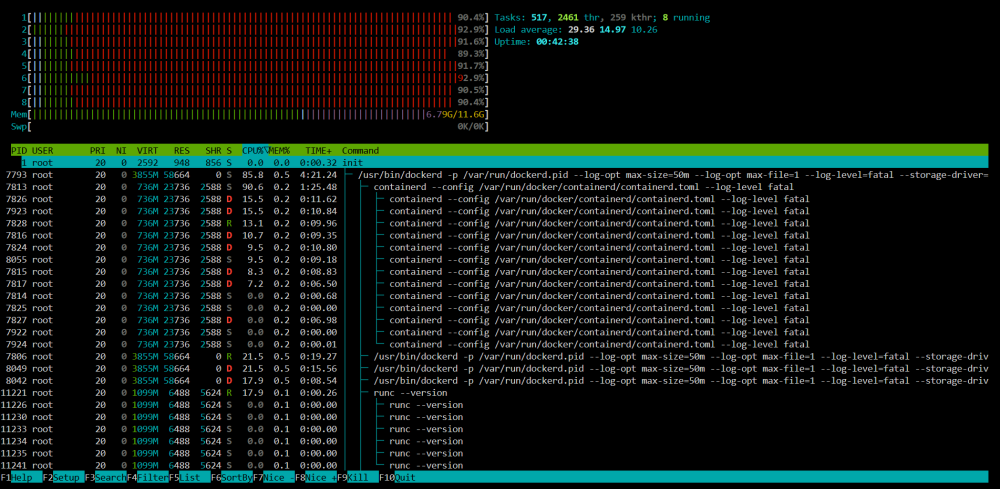
-
Hi, I'm desperate by now and have nowhere to turn. I was trying to replace 2 cache drives with 2 new ones but I must have done something wrong because not only I couldn't move all files to the array but I also managed to end up with all my docker containers missing. I stopped all containers and disabled docker. I have no VMs and VM Manager was disabled. I computed all shares to see how much space they were taking in each disk, checked to confirm all my shares had cache usage set to "yes" and then ran mover. This is when things stopped going according to plan: from the initial 600+ GBs of date in my cache, I still had 400+ GBs when mover was done. I ran mover a few more times but nothing happened. I had no idea what was behind this but decided I would move the files manually. So that's when I enabled docker so I could start Krusader. Went into Docker but my container folders were all empty. Tried rebooting but that didn't do much. I have an Immich compose running and that was still there, but when opening the WebUI I was greeted with a Welcome Page, as if this was the first time running it. Edit: my appdata folder still seems to have all my containers and all disks seem to have kept the data. Diagnostics below, can someone save me? Please? mushu-diagnostics-20230311-1342.zip
-
Thank you so much, that's a relief. Should I be at all worried with #1 Raw Read Error Rate which has a mention of pre-fail under type? Also, shouldn't my Datacache pool have more space than just 750GB? My Datacache 2 drive which is the newly added Sata 3 SSD drive doesn't seem to be used. Is that normal?
-
Hi everyone, I had 2 cache drives and had a cache drive fail the other day. I took it out and added a new 500GB SATA 3 drive and now it's looking like this: But now I'm seeing an error in my other previous SSD: I ran a Smart Extended Test and it said everything was OK (log attached) but looking at the Attributes section I think I saw something worrying: The thing is, I have no idea what this means. So I guess my questions are: What is this? How do I fix this/What should I do? Could anybody help me, please? Thank you so much. More context below: I was using two cache pools: One 500GB NVMe SSD for Appdata and the Docker image. This would use the cache only (I'll call it Appdata Cache). One 1TB Sata III SSD for storing data from qBitorrent and some other stuff. This would be written to cache and later moved to the array when it was full or close to full (I'll call it Data Cache) The idea was to have the docker image and the appdata in the faster drive - the Appdata Cache - and for the qBitorrent stuff I would use a different ssd for cache which would be moved to the array later. I also had the CA Backup plugin making backups to the array everyday. I was having some critical temperature warnings in my Appdata Cache - the nvme ssd - and eventually it had some sort of error. Stupid as I was, I didn't save any logs and rebooted the system. After getting nowhere trying to detect what it could be, I stopped the array, shut the system down, took out the nvme disk and added one 500gb sata ssd I had laying around. Upon rebooting I eliminated the Appdata Cache Pool and stuck to only 1 pool, the Data Cache pool, with two diferent sized Sata III SSDs (1TB and 500GB). I moved the Docker image path to the Data Cache Directory and ran the CA Backup Restore. Rebooted the Device and reinstalled the previously installed apps. This last part seemingly worked well and I retrieved almost everything, with exception of Nextcloud which now shows an internal error (likely some sort of database issue, I don't know I haven't looked into it yet) and Immich which was essentially reset. Now I noticed this in the pictures above. mushu-smart-20221203-1003.zip

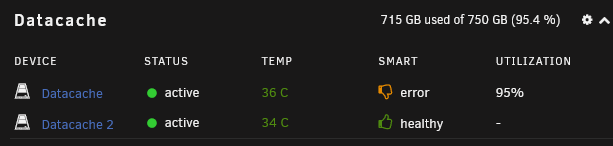
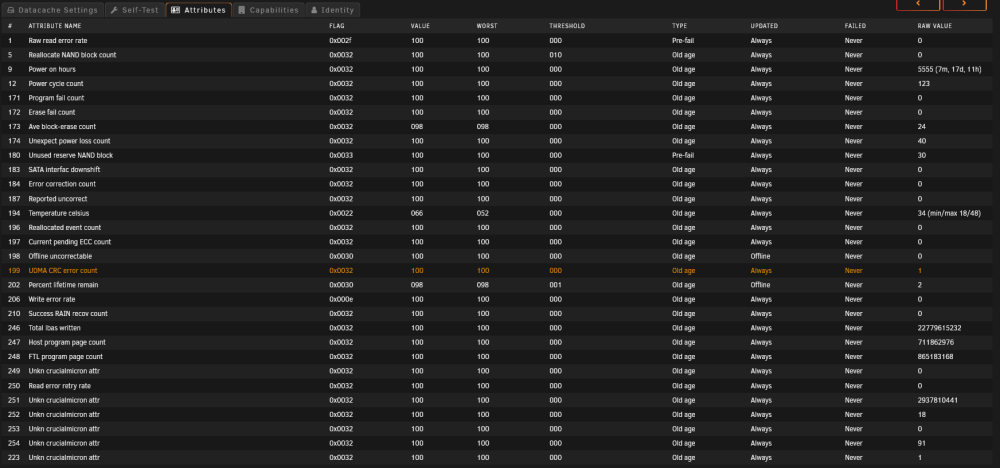
-
Hi My binhex-prowlarr container keeps stopping for no apparent reason. The logs show this: 2022-09-12 03:00:11,095 WARN received SIGTERM indicating exit request 2022-09-12 03:00:11,095 DEBG killing start-script (pid 65) with signal SIGTERM 2022-09-12 03:00:11,095 INFO waiting for start-script to die 2022-09-12 03:00:11,230 DEBG 'start-script' stdout output: [Info] ConsoleApp: Exiting main. 2022-09-12 03:00:11,231 DEBG fd 8 closed, stopped monitoring <POutputDispatcher at 23285748612304 for <Subprocess at 23285748610336 with name start-script in state STOPPING> (stdout)> 2022-09-12 03:00:11,231 DEBG fd 10 closed, stopped monitoring <POutputDispatcher at 23285749057616 for <Subprocess at 23285748610336 with name start-script in state STOPPING> (stderr)> 2022-09-12 03:00:11,231 INFO stopped: start-script (exit status 143) 2022-09-12 03:00:11,231 DEBG received SIGCHLD indicating a child quit Does anybody have any idea what this could be? Thanks.
-
Hi, Sorry for this but I've been experiencing this stupid error that I can't get around no matter how much I try, I've tried reading about this but got nowhere. Right now I'm having errors in a lot of other docker containers and I'm just so frustrated. So, Nextcloud: I access the WebUI, either from the internal address or the reverse proxy, enter my credentials, and get this error - Internal server error, The server was unable to complete your request. If this happens again, please send the technical details below to the server administrator. More details can be found in the server log. I got the unraid log from the diagnostics tool. Attached here. I found this in syslog file: Aug 14 14:20:41 Mushu emhttpd: shcmd (39577): cp '/boot/config/shares/nextcloud.cfg' '/boot/config/shares/Nextcloud.cfg' Aug 14 14:20:41 Mushu root: cp: '/boot/config/shares/nextcloud.cfg' and '/boot/config/shares/Nextcloud.cfg' are the same file Aug 14 14:20:41 Mushu emhttpd: shcmd (39577): exit status: 1 Aug 14 14:20:41 Mushu emhttpd: shcmd (39578): mv '/mnt/user/nextcloud' '/mnt/user/Nextcloud' Aug 14 14:20:41 Mushu emhttpd: shcmd (39579): rm '/boot/config/shares/nextcloud.cfg' Aug 14 14:20:42 Mushu emhttpd: Starting services... Aug 14 14:20:42 Mushu emhttpd: shcmd (39581): /etc/rc.d/rc.samba restart Aug 14 14:20:42 Mushu wsdd2[5314]: 'Terminated' signal received. Aug 14 14:20:42 Mushu nmbd[5304]: [2022/08/14 14:20:42.127989, 0] ../../source3/nmbd/nmbd.c:59(terminate) Aug 14 14:20:42 Mushu nmbd[5304]: Got SIGTERM: going down... Aug 14 14:20:42 Mushu winbindd[5317]: [2022/08/14 14:20:42.128008, 0] ../../source3/winbindd/winbindd.c:247(winbindd_sig_term_handler) Aug 14 14:20:42 Mushu winbindd[5317]: Got sig[15] terminate (is_parent=1) Aug 14 14:20:42 Mushu winbindd[5319]: [2022/08/14 14:20:42.128024, 0] ../../source3/winbindd/winbindd.c:247(winbindd_sig_term_handler) Aug 14 14:20:42 Mushu winbindd[5319]: Got sig[15] terminate (is_parent=0) Aug 14 14:20:42 Mushu wsdd2[5314]: terminating. Aug 14 14:20:42 Mushu winbindd[18485]: [2022/08/14 14:20:42.128692, 0] ../../source3/winbindd/winbindd.c:247(winbindd_sig_term_handler) Aug 14 14:20:42 Mushu winbindd[18485]: Got sig[15] terminate (is_parent=0) Aug 14 14:20:42 Mushu smbd[13366]: [2022/08/14 14:20:42.130740, 0] ../../source3/smbd/service.c:168(chdir_current_service) Aug 14 14:20:42 Mushu smbd[13366]: chdir_current_service: vfs_ChDir(/mnt/user/nextcloud) failed: No such file or directory. Current token: uid=1000, gid=100, 4 groups: 100 3003 3004 3005 Aug 14 14:20:42 Mushu smbd[13366]: [2022/08/14 14:20:42.130792, 0] ../../source3/smbd/smbXsrv_tcon.c:911(smbXsrv_tcon_disconnect) Aug 14 14:20:42 Mushu smbd[13366]: smbXsrv_tcon_disconnect(0x08cd2566, 'nextcloud'): chdir_current_service() failed: NT_STATUS_INTERNAL_ERROR Aug 14 14:20:42 Mushu smbd[13366]: [2022/08/14 14:20:42.130829, 0] ../../source3/smbd/smbXsrv_tcon.c:1023(smbXsrv_tcon_disconnect_all) Aug 14 14:20:42 Mushu smbd[13366]: smbXsrv_tcon_disconnect_all: count[3] errors[1] first[NT_STATUS_INTERNAL_ERROR] Aug 14 14:20:42 Mushu smbd[13366]: [2022/08/14 14:20:42.130849, 0] ../../source3/smbd/smbXsrv_session.c:1822(smbXsrv_session_logoff) Aug 14 14:20:42 Mushu smbd[13366]: smbXsrv_session_logoff(0x80d0eb50): smb2srv_tcon_disconnect_all() failed: NT_STATUS_INTERNAL_ERROR Aug 14 14:20:42 Mushu smbd[13366]: [2022/08/14 14:20:42.130883, 0] ../../source3/smbd/smbXsrv_session.c:1928(smbXsrv_session_logoff_all) Aug 14 14:20:42 Mushu smbd[13366]: smbXsrv_session_logoff_all: count[1] errors[1] first[NT_STATUS_INTERNAL_ERROR] Aug 14 14:20:42 Mushu smbd[13366]: [2022/08/14 14:20:42.130908, 0] ../../source3/smbd/server_exit.c:170(exit_server_common) Aug 14 14:20:42 Mushu smbd[13366]: Server exit (termination signal) Aug 14 14:20:42 Mushu smbd[13366]: [2022/08/14 14:20:42.130927, 0] ../../source3/smbd/server_exit.c:172(exit_server_common) Aug 14 14:20:42 Mushu smbd[13366]: exit_server_common: smbXsrv_session_logoff_all() failed (NT_STATUS_INTERNAL_ERROR) - triggering cleanup Aug 14 14:20:44 Mushu root: Starting Samba: /usr/sbin/smbd -D Aug 14 14:20:44 Mushu smbd[26039]: [2022/08/14 14:20:44.302733, 0] ../../source3/smbd/server.c:1734(main) Aug 14 14:20:44 Mushu smbd[26039]: smbd version 4.15.7 started. Problem is, I have no clue what it means. Could anyone help me? Thank you so much, kind strangers. mushu-diagnostics-20220814-1424.zip
-
I'm now trying to set up transcoding with my Nvidia GPU running the latest version dated Sep, 2021. Is GPU transcoding not available on this package? Do I have to change to the Linuxservers' package?
-
OK I did that now. The docker image path was "/mnt/user/system/docker/docker.img" so after deleting it I moved the path to "mnt/cache/docker.img" as you suggested. I reactivated the Docker service and rebooted the system, but still nothing. I noticed that the cache disk was full. I only have one cache disk which is a 120GB SSD, and it's being used to save incomplete torrent downloads. Now that I think about it, it has been full or close to full almost always. So I after recreating the docker image and rebooting the system without results, I ran the mover which cleared space on the cache disk and then rebooted the system. This time it worked and the docker service was enabled. I'm now redownloading my applications. So I guess that's it, it's solved? Thank you for the help. I guess I still have some reading to do regarding the use of the cache and how to keep it from being used at full capacity.
-
Hi, @Squid, I'm sorry, I thought the log was what would be needed. After your message I tried posting it but I had a 1 post/day limit. Since then I haven't managed to come to the forum. The server has actually been functioning on and off this last week and a half. After my initial post, it somehow "fixed" itself temporarily and the Docker Service started working again without me doing anything, then broke down a couple more times and came back on. Right now the Docker Service can't be started. This is the diagnostics I ran a few minutes ago. I also had this error message in the docker tab: Warning: stream_socket_client(): unable to connect to unix:///var/run/docker.sock (Connection refused) in /usr/local/emhttp/plugins/dynamix.docker.manager/include/DockerClient.php on line 682 Couldn't create socket: [111] Connection refused Warning: Invalid argument supplied for foreach() in /usr/local/emhttp/plugins/dynamix.docker.manager/include/DockerClient.php on line 866 Warning: stream_socket_client(): unable to connect to unix:///var/run/docker.sock (Connection refused) in /usr/local/emhttp/plugins/dynamix.docker.manager/include/DockerClient.php on line 682 Couldn't create socket: [111] Connection refused Warning: Invalid argument supplied for foreach() in /usr/local/emhttp/plugins/dynamix.docker.manager/include/DockerClient.php on line 932 No Docker containers installed tnt-diagnostics-20211030-1122.zip
-
Hi everyone, I don't know where else to ask and seeing as I'm quite new to this I'm completely lost: I recently updated to Unraid 6.9.2. After completing the updated, I kept working on the server for a few more minutes and after that decided to restart the array for the changes to take effect. After restarting I had this problem - Docker Service Failed to Start. I have no idea why and I don't know what the contents of the log mean. Did a parity check and everything looks good. I ran and downloaded the diagnostics, and the docker log file reads as follows: time="2021-10-13T19:16:01.590161186-07:00" level=error msg="garbage collection failed" error="input/output error" panic: runtime error: invalid memory address or nil pointer dereference [signal SIGSEGV: segmentation violation code=0x1 addr=0x10 pc=0x9fa7e5] goroutine 29 [running]: github.com/containerd/containerd/gc/scheduler.(*gcScheduler).run(0xc000084ba0, 0x1da1380, 0xc000040060) /tmp/tmp.nEFLvHBBrz/src/github.com/containerd/containerd/gc/scheduler/scheduler.go:316 +0x765 created by github.com/containerd/containerd/gc/scheduler.init.0.func1 /tmp/tmp.nEFLvHBBrz/src/github.com/containerd/containerd/gc/scheduler/scheduler.go:132 +0x429 time="2021-10-13T19:16:01.593961674-07:00" level=error msg="containerd did not exit successfully" error="exit status 2" module=libcontainerd failed to start daemon: input/output error Could someone give me a hand and tell me what I have to do to get the Docker Service running again?




