




m-a-x
Members
-
Joined
-
Last visited
-
Should I change the Pool settings > Primary Storage from Array to datapool manually then? Or leave it as Array even though this is an incorrect info?
-
If I disable the "Enable user share assignment" for a pool, does it mean that I won't be able to create shares on the pool even manually? Complete disable? Also regarding the STORAGE info - why am I seeing that the shares are located on the Array (i.e. Primary storage), not the zfs pool?
-
I've created two ZFS pools and a top level folder in each: 1backup and 2backup. Immediately I notice that the 2 folders appeared listed as Shares. If I create more folders in those pools, they all end up listed as shares in GUI and present in the /mnt/user/. Is that normal? Another thing I noticed in GUI > Shares is the "Storage info" for these 2 shares (that reside in my two ZFS pools). It says that their Primary location is "Array", not my ZFS pools. What??!! Can anyone clarify this? Am I missing something?


-
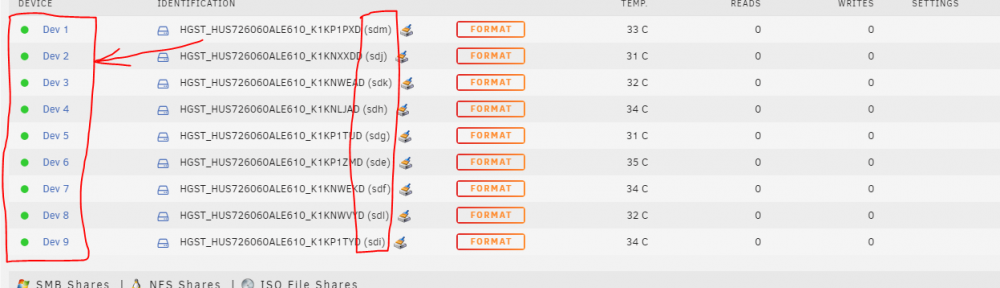
Dev 1 through 9 are the source of suffering. sdX have direct correlation with physical SAS connectors on my 24 bay SAS expander, so I know which drive is which sdX. But the Dev [#] that I don't even know what it is, gets assigned randomly. If I remove say half the drives, the Dev [#] would get rearranged, there would be still Dev 1-4, but as soon as I introduce all the drives back, the Dev [#] assignment goes back to this specific arrangement. So it obviously uses some HDD info to map it in this particular way.
-
Not sure if you mean the plug-in thread, but the dev # assignment is random even without the plug-in installed. The "native" unassigned devices does the same thing.
-
Yes, I know, it doesn't affect functionality. But it just drives my OCD insane!! I am trying to understand how those Dev # are assigned? I have 9 drives: sde/f/g/h/i/j/k/l/m and their dev # are completely out of order in GUI and they are scattered all over the place under the "unassigned device" list. I plan to zpool-1 (raidz2) the first six sde/f/g/h/i/j (they're sitting next to each other in the server too), then zpool-2 (mirror) the other two sdk/sdl, and then use the last drive as a hot spare for zpool-1. My eyes are bleeding when I see the two pools' members all mixed up in the list. I tried powering the server on and adding the drives one by one - sde, sdf, sdg, etc etc. At first they're showing up as dev 1, dev 2, but then as I add more drives to the server they start exchanging dev numbers between each other ending up completely shuffled. I'm in pain. Can I control this behavior?
-
I want to deploy a Win10 VM with BlueIris. As far as I remember the software writes to destination in continuous/looped fashion. Each camera generates its own filestream, cut into whatever time segments you choose. You also define a max cap for all the recordings. Once it's reached, the oldest files get deleted as new data flows in. I have 2x6TB data drives + 1x6TB parity drive. Total available space 12TB. In BlueIris I configure the max recording cap of 10TB. Time to configure the destination. What's are the best practices configuring destinations for continuous recordings, which are always full at capacity and the files just get overwritten in a loop? Should I configure a standard UNRAID share? What do I do with the allocation method if the space is technically always full? Do I even bother configuring UNRAID shares? Will ZFS work better? Cache Pool?
-
Thanks! Totally agree.
-
Would it make sense to do a quick check for disk signature before the message? Something like: "the disk seems to have been already precleared by 3rd party tool. If you trust the tool and wish to add the drive and skip the clear check [x] I trust this tool and understand the consequences. Otherwise leave unchecked and UNRAID will clear the disk again. Thanks everyone for the input! I totally understand the technical side, I get it. It'd just be nice if the message was less confusing for users who don't know. At least a simple note: [*if the disk has been precleared, then Unraid will skip it].
-
Emulated disk was brought up in this conversation in a different context, specifically a scenario of data corruption on the emulated disk in case of bit flip on a precleared disk that had been added to the array at some point and a subsequent failure of a disk. Anyway, that's beyond this topic. The real question is - if UNRAID trusts that the new disk is clean based on the signature, why then GUI would still throw a message that the drive will be cleared again. One can't argue that this is a result of UNRAID not trusting Preclear/3rd party plugin. Because the drive signature is provided by Preclear too, and UNRAID happily trusts that signature i.e. Preclear's clearing job.
-
This is sort of what meant, I just worded it poorly. By saying "emulated disk is in reference to the disk that has been added to the array", I meant the disk that was going to be added to the array as a replacement to the failed one, which is the 1:1 copy of the emulated disk. But yes, I do realize that emulated disk is not even the replacement disk, it's not physical, it's a result of XOR in the RAM (I assume). Thanks for amazing explanation!
-
This makes total sense, thanks for the detailed explanation. I assume that the term "emulated disk" is in reference to the disk that has been added to the array? Also, I assume "flipping bits" refers to a procedure that bypasses traditional write access, otherwise the clear signature would have been destroyed, correct? I also understand that the result of mismatching parity is correction of the parity data, not the flipped bits? About the disk failure remark - this is exactly the scenario I had in mind when I said "risking the integrity of the entire array" in my original comment. I found confusing that, I quote, "preclear is not a standard part of Unraid but a 3rd party utility so the GUI does not take account of the fact that a Clear had been done outside the control of Unraid". Here's why: The OP tried to add a precleared drive to the array and Unraid was stating that it wanted to clear the drive again. So on one hand UNRAID uses the signature as a proof that that drive is zeroed, and on the other hand the GUI still throws a misleading message that the disk cleaning was going to happen again. It's worth noting that the drive was certainly clean and untampered with: as per OP follow up he OKed the prompt for one more clearing, only to realize that nothing really happened and the drive was added to the array instantly. What's in bold seems to me contradictory. Not trying to be annoying, just trying to understand how it all works. UNRAID is awesome.
-
I'll try to explain but correct me if I am wrong at any point. The statement above implies that UNRAID has no knowledge if disk clearing has been performed outside own native functionality, hence the message that the disk will be cleared. At the same time, as we see later, UNRAID trusts the signature that is issued by the same plug-in from "outside", assumes that the new disk has been zeroed and adds it to the array without own native clearing process. My confusion is why UNRAID has no knowledge of outside clearing, if in fact it can validate it via Preclear signature? Am I missing something? Thanks!
-
I am new and just learning UNRAID, but can you please elaborate on the following: If UNRAID "does not take account of the fact that a Clear has been done outside", then how does it make a decision to add the drive to the array without the subsequent clear procedure? Doesn't it still rely on the signature issued by Preclear, technically risking the integrity of the entire array?
-
My perception might be completely off, due to some things that I could be missing entirely. But if we forget about SAS3 and DataBolt for a moment (I found this info too while waiting for comments here) and consider an older SAS2 end-to-end connection but SATA2/SAS1 drives - what actually happens there? I just can't understand how the speed of the drive can reduce the bandwidth of the link between the expander and HBA. Which hardware instance decides to drop the speeds to 3Gbps per lane when it detects SATA2 drives? What happens if I have a mix of SATA2 HDD and SATA3 SSD capable of 6Gbps?


