




banangineer
Members
-
Joined
-
Last visited
-
Hi all, I've spent a few days Googling between the UnRAID forums and Reddit but haven't found anyone who's replicated this issue yet. This started six days ago when I was notified that "Plex was unavailable." When I checked my server, I found that my CPU (10700k), RAM (64GB), and SSD Cache (2 2TB WD SATA) were all pinned to 100% utilization. I recently moved some processes away from Docker and into dedicated VMs, and thought it was related to that, and shut down them down. This resolved my CPU pinning issue, but my RAM utilization was still abnormally high. I checked the Docker tab and found that the Plex (at the time, the official) container was utilizing 48GB of RAM, and climbing. The logs from the Docker container appeared to be a series of "No Data Written" messages. Attached is what I was able to capture the first time this happened: FWIW, my VMs that I shut down were using ~16GB of RAM for game servers and other processes. So Plex was no longer pinning the CPU, but it was still ballooning in RAM usage. This seems to start during the middle of the night but I don't notice it until I'm awake. If I restart the docker container, this issue seemed to go away. I tried to run the analysis on each library from the Plex GUI and saw 20GB+ usage, but never anything like the picture above. I decided to try the linuxserver.io container as I've seen several users say that the official container usually has problems. The first night I did this, I didn't have issues. The second night (last night) I had the same problem as the official container. Screenshot below to show the logs + messages. The LSIO logo shows up from when I restarted the container. I'm led to believe that this is either an issue with Plex itself, a bad video file, or a corrupted database. However, I haven't been able to find this message anywhere clearly online. Does anyone have an idea of where I can start troubleshooting? It's getting obnoxious having to restart the container every day or risk other issues popping up.

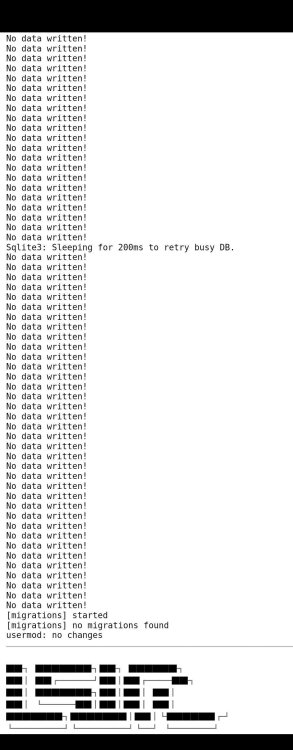
-
I pulled the failing drive, ironically it was a drive I got back from Seagate RMA, and replaced it with my cold spare. Currently running a parity sync, should be up and good now. I think I'm just tired and overthinking it. It's not the first time I've had to replace drives. I may be paranoid from the last time when I lost two drives in a day. Idk. Thanks again for your help as well as Jorge.
-
I want to clarify this statement. My cold spare is another 10TB Seagate drive. I just wanted to confirm I didn't have to move my data drives before replacing a parity drive.
-
I had not checked that section before. I didn't realize you could run extended SMART tests. Now I know. I don't think it finished. I specified that the drives shouldn't spin down, but they may have anyway. This may have been an error on my end. zawarudo-diagnostics-20220215-2249.zip Posted. It still shows a SMART short test of PASSED, but as I read more into the results I see the same pre-failure warnings. Yes That sounds about right to me. I'll go ahead and replace the drive with my cold spare. Do I have to do anything special since the drive I'm replacing is a parity drive?
-
The report looks like it finished. Below are some of the rows that Unraid highlighted. The drive is barely three months old, so I doubt it's old age, and I even pre-cleared it this time. I'm guessing it's better to go ahead and pull it, replace with the cold spare, and RMA the drive?
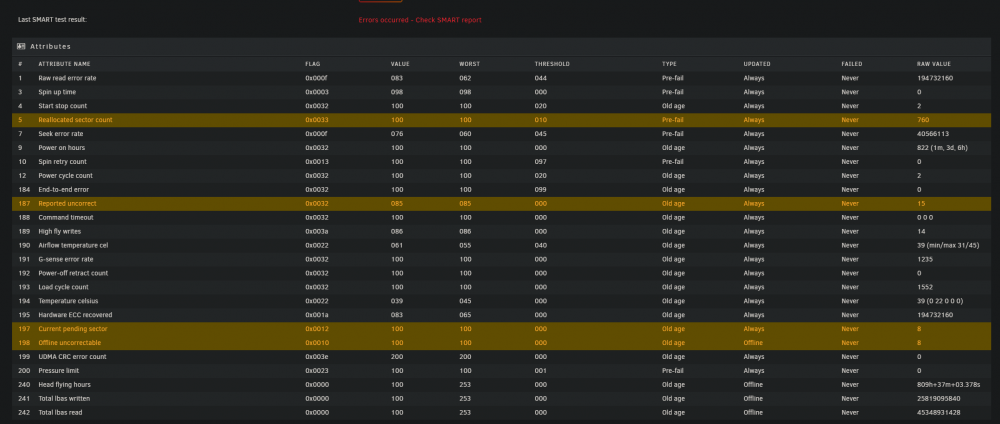
-
I appreciate it. Hopefully someone else reading this thread in the future will find it useful. I'm running an extended SMART test now after turning off disk spin down. I'll follow up in this thread later when the test is complete.
-
This may be a stupid question, but I can't find the answer from Google. How do I run an extended SMART test and not the base tests that are shared from diagnostics?
-
zawarudo-diagnostics-20220215-1221.zip My diagnostics are attached below, the title sums up the TLDR. I'll provide more details below for context. I started a parity check last night, and didn't notice that one of my two parity disks is currently seeing write errors. Specifically 29****. As of writing it's at 1685. I've read from the forums that one reallocated sector is fine, but it appears to have reallocated sectors in the 400+ range. I have dual parity so I'm not as worried, but the drive reporting errors is a parity drive. I'm not sure if this is going to be an issue or not. I have a cold (identical) spare that I can chuck-in and rebuild but I want to be sure that I have to. So far it's not slowing down my parity speed, but it is a drive I got back from RMA from Seagate. Should I chuck in my cold spare and rebuild, and RMA the drive? Is it on it's way to disk failure? Should I be careful since it's one of two parity disks? Or am I overthinking it? Side note: If this drive is getting replaced, it would be the third Seagate drive I've had to RMA. I only built my Unraid server back in July of 2021.
-
I think that may be what I have to do for the time being. I don't really want to drop more cash on drives until after I've RMA'd the two failing ones. Assuming that the new config only affects the array, I will probably go ahead remove the second failed drive for RMA, and build a new config using my three (hopefully) working drives. Once the others are back from RMA, I'll add a second parity disk and just keep building to the array from there. Is this the recommended approach?
-
That's fine with me. If I went with a new config for my array, does that reset my cache drives? They're pooled, and even though I've backed up the most important parts, can I assume since they're detached from the array they're unaffected if I rebuild the array from scratch?
-
At this point was I was able to gather and collect everything I needed from the failing drive, albeit slowly. It didn't kill the share completely so I was lucky it could move the data somewhat. At this point both drives are essentially dead to me. If I can keep my cache drives so I at least have my Docker and VM data, I'll be fine with nuking the array. What are next steps? Can I remove the second failed drive, create a new config with the three drives remaining and add back the other drives when they're back from RMA?
-
I'm updating this again to include the diagnostics. Even though the SMART check passed on Disk1, the seek error rate seems extremely high. I can also confirm that I have begun losing files while the disk was rebuilding and the disk was erroring. In case anyone would like to hear it for themselves: https://imgur.com/a/QUrhx7z zawarudo-diagnostics-20211214-2302.zip
-
Just to update the situation. Bought an Iron Wolf NAS drive and replaced it. Everything seemed fine. Up until the 19% mark of the rebuild, and I started getting tons of errors on my disk1 (one of the drives that was working). I had started it and went out to get food, several hours later I came back to the attached image and tons of chirping from what is disk1. Can I assume I have a second failed drive as well? My parity and disk3 are still fine. But disk1 has several errors and they keep climbing. I was able to grab most of what I needed from it, albeit slowly.


-
No, you could move any data form emulated disk2 to other disk(s) and then do a new config and re-sync parity. You make a good point. In the meantime I'm going to replace the drive with another similar spec drive and hope for the best. I'll avoid shrinking the array and causing further issues. Thanks, I'll do some research to get a better idea, I appreciate the direction. I remember seeing #187 being a warning in UnRAID so that checks out. I'll go ahead and get a replacement drive in ASAP and ship off my dud for an RMA. I'll update this thread when the new drive is in and the bad drive has been replaced.
-
Yes, that is the one that is currently failing. Hopefully I can still RMA it with Seagate since it was purchased earlier this year. In the meantime, I have another drive that is registered in the array, but is still listed as disk3 in the array. The drive is not attached to either Share, and I'm fine with dropping the contents of it. Could I shrink the array from 3 + 1 parity to 2 + 1 parity, moving disk3 to replace disk2, and re-add my RMA'd or replaced drive back as disk3 later? Or is that not how shrinking the array works? Also, for my own education, can you tell that's the failing drive because of the sector errors? Or are there other useful logs that tell you that?




