




sph031772
Members
-
Joined
-
Last visited
-
My docker had been running good for months. I haven't changed anything in the docker settings since I initially set it up, but I did move my appdata folder to a new SATA SSD cache protected by RAID 1 from a stand alone NVME. I noticed after I moved it the qbittorent Web UI login took longer to prompt, a few seconds. Now it just simply stopped working a few weeks later. When I disable VPN it works though. CA backups has been backing up QBIT and I also noticed that the folder permission state owner nobody (not sure if that changed at one point). Im using Nordvpn as my VPN, I tried replacing the sever file with a new one, but no luck. All of my ARR dockers use a separate bridge network I created called dockerrnet 172.18.0.0/16 I tried switching to br0 and changing the LAN Network settings, nothing has worked. I see static routes but I'm not sure what the gateways are. Route: 172.17.0.0/16 Geteway: docker01 Route: 172.18.0.0/16 Gateway: br-31fc6dcb88df1 I get the following error when I start the Docker with VPN enabled. 472 DEBG 'start-script' stdout output: TLS Error: TLS key negotiation failed to occur within 60 seconds (check your network connectivity) TLS Error: TLS handshake failed DEBG 'start-script' stdout output: SIGHUP[soft,tls-error] received, process restarting I'm running Tag 4.4.5-1-01. Any help would be much appreciated. supervisord.log_1.txt
-
Ok, got it. Thanks JonathanM that makes sense, I'll try reproduce it by removing the HBA and putting back the original hardware configuration when I built the VM.. The last issue I had number 4 listed above. I rebooted the server, the VMs were not set to auto start and I did not start the VMs. The array did not start, and some how in Disk settings Enable AutoStart was set to "No". (The array has always Auto started). When I changed it to "Yes" and started the array all disks errored out. Does anyone have an explanation for that behavior?
-
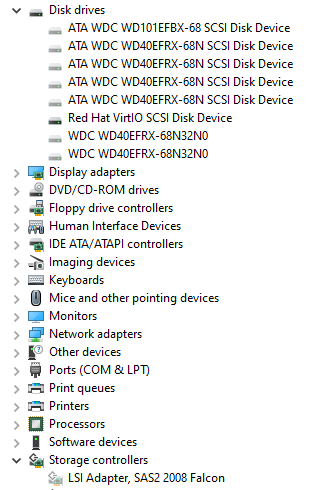
Thanks for the explanation JorgeB, I won't be testing your theory, I'll take your word for it ;-). Any idea how this could happen or how it can be avoided? I created the VM long before adding the HBA. The only thing that might have happened is at one point I edited the VM and I suppose the HBA got added then? This morning, I edited the VM to remove the entire PCI section: <hostdev mode='subsystem' type='pci' managed='yes'> <driver name='vfio'/> <source> <address domain='0x0000' bus='0x24' slot='0x00' function='0x0'/> </source> <address type='pci' domain='0x0000' bus='0x00' slot='0x06' function='0x0'/> </hostdev> After I started the VM, I went into Device Manager > Hidden Devices, and I can confirm that the LSI card and all of the disks were indeed there at one point, they are gone now: I can only assume this is an Unraid Bug because I'm sure I didn't add the HBA, and I've never had a SCSI controller end up in a VM like that. Going forward I'll make sure to review the XML of each new VM to make sure the HBA isn't added automatically. I'll monitor closely and hope I don't get any more disk errors. I'll report back in few weeks. Thanks for all of your help, any clarifications on why this may have happened would be much appreciated.
-
Thanks for answering so quickly Squid, Art of Server observed the same thing. Now that you too have observed the same thing, and after further investigation, it looks like one of my 2 VMs that has nothing passed through to it, does have a PCI device with the same bus number as the Dell HBA in the XML: <hostdev mode='subsystem' type='pci' managed='yes'> <driver name='vfio'/> <source> <address domain='0x0000' bus='0x24' slot='0x00' function='0x0'/> </source> <address type='pci' domain='0x0000' bus='0x00' slot='0x06' function='0x0'/> </hostdev> Am I interpreting this correctly, if so, how could this have happened, could it be causing the disk errors, and in your opinion what should I do next? Thank again for the help

-
I've been using Unraid for over a decade with no issue, recently I upgraded my hardware from a Lynfield Xeon on Supermicro to an 11th gen i7 on Z590. Everything was going well for a few months, then all of a sudden I started having a reoccurring issues with my array after upgrading certain components. Shortly after adding a Dell DH310 SAS2008, (about a week after) I had an array incident where all disks in the array including the parity started generating errors. I tried removing the HBA to eliminate it as the cause, and everything was good for a couple of days. Then after unplugging all the drives while the server was on (sigh), I had errors ONLY with the Parity drive. I figured maybe it's because my WD RED 4TB drives are 3-4 years old. I changed the parity disk with a brand new 10TB WD Red Plus, and replaced the HBA with another identical card, and after a couple of days all drives have errored again. After rebooting, the array is showing good again. I'm not sure what the problem is, I searched the forum, but haven't found anything exactly like my problem. I'm assuming hardware, but I can't find a smoking gun in the diagnostic logs. The first time I had the issue, the server was off the UPS on the bench, because I was upgrading it, so it may have been due to a power glitch, I don't know and I didn't save the logs before rebooting. The array came back online with disk 1 disabled, but I was able to get it back after removing/adding back to the array. The second time I was away for the weekend, all drives had over a million errors when I got home. I was unable to remount disk 2, ended up having to remove from array do a manual file recovery, add it back to the array empty, format. I was doing maintenance on the server, thought I had powered it down, unplugged all of the disks (sigh), and about 80 errors were generated on Parity ONLY. I pre-cleared the parity disk successfully, but took advantage to add a 10TB Parity disk to replace it. I finally recovered all my files, rebuilt parity, everything was green array was healthy. Server was connected to a brand new Sign Wave UPS. I shutdown the server to remove an unassigned drive, made sure everything was well seated, and when I booted up again the array was stopped. I went into the disk settings and AutoStart that was set to "no". I set it to "yes" and started the array. All disks started generating errors. I downloaded the logs and smart, attached and rebooted. The array came back online and is showing "array turned good" When I added the HBA, I upgraded the RAM (successful Memtest), but at the same time, I had to connect my internal USB 3.0 addon card to a PCIe 1x extension cable, because the only slot I had left was under the GPU. I only have one USB controller on the Mobo, and I'm passing it trough to my Gaming VM. So I have my Samsung Flash Drive connected to addon 2 port USB 3.0 PCIe 1x, connected to a PICE 1x extension cable, and connected to that I have a Philips USB 2.0 HUB so that I can connect my Unraid Flash and UPS Console Cable . Could the Flash drive cause errors like that? Also I'm connected to a brand new fully charged Sinewave APC UPS BR155MS2. I'm convinced the Dell HBA is compatible and working, I bought them refurbished from Art of Server and when I had the issue he shipped me another one to test, same issue so unlikely the card (Great guy BTW). There's even a hidden BIOS setting that appeared in the Advanced HDD settings of my Mobo to manage the HBA. The Amazon CableCreation 8087 cables were thoroughly tested for weeks with a HP 240 HBA with no issue. Unraid v 6.9.2 My hardware: Case: Fractal Design Meshify 2 PSU: EVGA 850 P2 MOBO: Asus TUF Z590-Gaming WIFI BIOS 1403 (most recent) CPU: i7-11700K RAM: 64GB (4x16GB) OLOy DDR 4 3600MHz MD4U1636181CHKDA HDD: 4x WD 4TB Red + 10TB WD Red Plus SDD: 2 x 1TB Samsung SSD Evo 870 Cache Protected NVME: 2 x WD BLACK SN750 SE 500GB (1 for VM and 1 for Docker) LSI HBA: Dell H310 LSI SAS2008 PCI-Express Fusion-MPT SAS-2 [Falcon] (rev 03) cooled with a Noctua 40mm fan. 8087 Cables: Amazon CableCreation Mini SAS 36Pin (SFF-8087) Passed through to Gaming VM: GPU: EVGA RTX 3080 10GB USB controller: Intel Corporation Tiger Lake-H USB 3.2 Gen 2x1 xHCI Host Controller (rev 11) RAM memory: Intel Corporation Tiger Lake-H Shared SRAM NVME: Adata Gen 4 1TB Internal PCIE 1x Ethernet controller: Intel Corporation Ethernet Controller I225-V (rev 03) Sorry for the long winded post, trying to add as much info as I can, Thanks in advance for the help! unraid-diagnostics-20220428-1710.zip unraid-smart-20220428-1713.zip


