




cardNull
Members
-
Joined
-
Last visited
Everything posted by cardNull
-
Today I got a notice from FCP that I had some MCE errors. I had this come up once before. Concerned it may be a memory issue I pulled all the ram 8x16 DDR4 ECC and replaced with other matching RAM I had laying around. Today it came up again. What are the odds its actually a memory issue if I swapped all my RAM. The FCP page says to report a issue here if I cant determine the issue. The error: mcelog: failed to prefill DIMM database from DMI data Kernel does not support page offline interface mcelog: Cannot read sysfs field /sys/kernel/security/lockdown: No such file or directory Kernel in lockdown. Cannot enable DIMM error location reportingHardware event. This is not a software error. MCE 0 CPU 0 BANK 10 TSC 8956258b3f8c9 MISC 90840200020128c ADDR 198f5f3000 TIME 1767288020 Thu Jan 1 11:20:20 2026 MCG status: MCi status: Corrected error MCi_MISC register valid MCi_ADDR register valid MCA: MEMORY CONTROLLER MS_CHANNEL1_ERR Transaction: Memory scrubbing error MemCtrl: Corrected patrol scrub error STATUS 8c000049000800c1 MCGSTATUS 0 MCGCAP 7000c16 APICID 0 SOCKETID 0 PPIN 405e95213d4d4350 MICROCODE 49 CPUID Vendor Intel Family 6 Model 63 Step 2 Corrected memory errors on page 198f5f3000 exceed threshold 2 in 24h: 2 in 24h Location SOCKET:0 CHANNEL:1 DIMM:? [] Hardware event. This is not a software error. MCE 0 CPU 0 BANK 10 TSC 8ad9984b39fea MISC 90840200020128c ADDR 198f5f3000 TIME 1767298266 Thu Jan 1 14:11:06 2026 MCG status: MCi status: Corrected error MCi_MISC register valid MCi_ADDR register valid MCA: MEMORY CONTROLLER MS_CHANNEL1_ERR Transaction: Memory scrubbing error MemCtrl: Corrected patrol scrub error STATUS 8c000049000800c1 MCGSTATUS 0 MCGCAP 7000c16 APICID 0 SOCKETID 0 PPIN 405e95213d4d4350 MICROCODE 49 CPUID Vendor Intel Family 6 Model 63 Step 2 Hardware event. This is not a software error. MCE 0 CPU 0 BANK 10 TSC 8c5d0b0b35baa MISC 90840200020128c ADDR 198f5f3000 TIME 1767308512 Thu Jan 1 17:01:52 2026 MCG status: MCi status: Corrected error MCi_MISC register valid MCi_ADDR register valid MCA: MEMORY CONTROLLER MS_CHANNEL1_ERR Transaction: Memory scrubbing error MemCtrl: Corrected patrol scrub error STATUS 8c000049000800c1 MCGSTATUS 0 MCGCAP 7000c16 APICID 0 SOCKETID 0 PPIN 405e95213d4d4350 MICROCODE 49 CPUID Vendor Intel Family 6 Model 63 Step 2 nachoserver-diagnostics-20260102-1037.zip

-
Just in case anyone was tracking this. I dumped everything on the cache. It was all "docker" image junk like @JorgeB and @itimpi said. Once I booted with the new cache disks I just configured docker again and added all my containers via "previous apps". I am good to go. Just need to figure out why my server keeps crashing now.
-
I went through every single container. I could not for the life of me to figure out how to find what was doing it. Is there a clear guide to solving that? Is there a reason that the "image" is a better solution?
-
Thanks JorgeB. I will try this tonight. Are you suggesting using a docker image file always or just this once? I moved to the "filesystem" because my image file kept filling up then throwing errors.
-
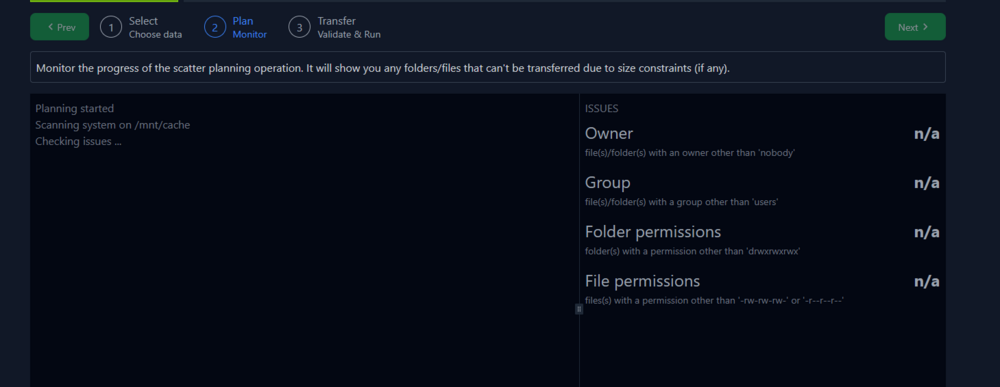
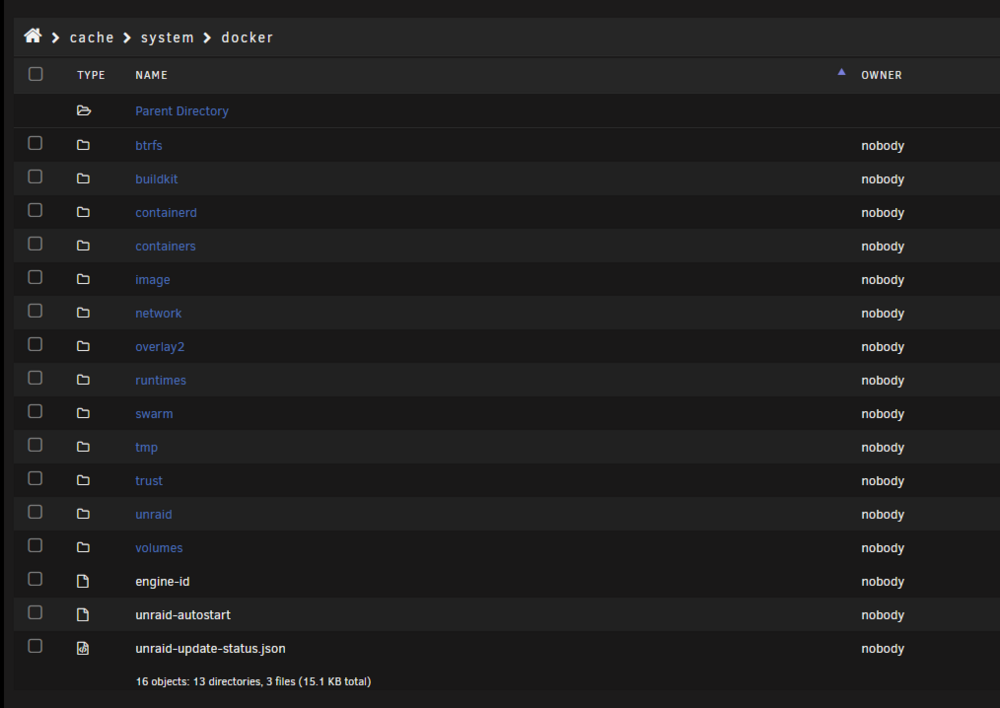
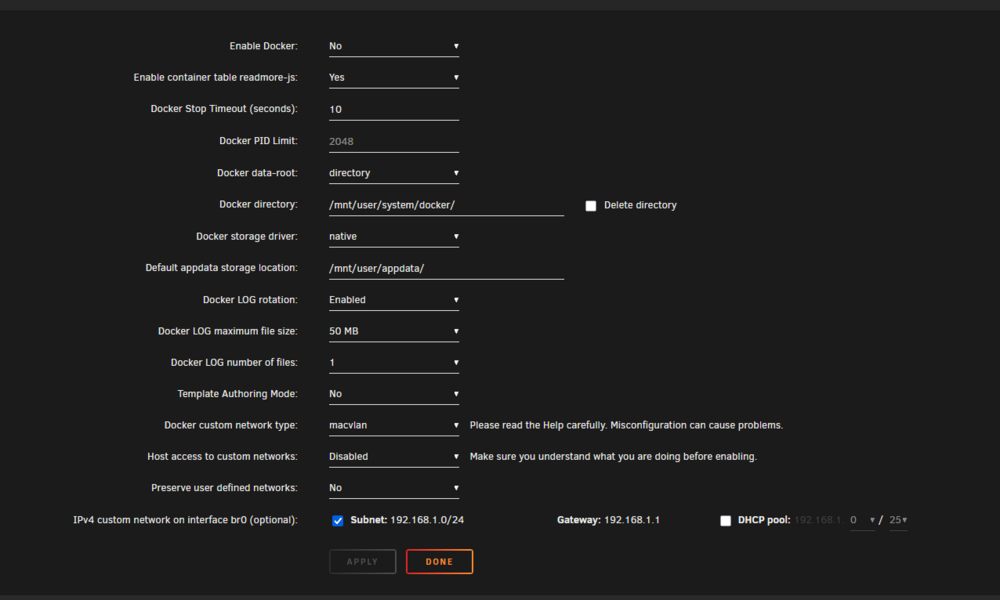
I let the mover run overnight and only 40GB moved. I have another 140GB to move. But now it seems that hours can go by and only a few hundred MB will have moved. I tried to load up "unbalanced" to move it that way. But no luck. It wont get pas this: Eventually that screen will be blank (the large dark box with "planning started"). I was able to move other data from one place to another, But trying to move data from the Cache to the array. Wont happen. I tried restarting unbalanced. What have I tried on the server so far? I rebooted more then once. I have all docker and VM stuff off. I have downloaded and reviewed the logs to no avail. I tried some googling and AI support. But nothing turns up why "my" issue is happening. The best I could track down was some folks saying that many small files on the cache can "just take forever" and "its the nature of the mover". My cache pool is 2 disks (each 250GB) in raid 1. I checked the smart on the main drive. Its reported it was fine. One final note. I have docker setup as a "filesystem" not the image file. This is the section that is taking forever to move. Its the only thing left on the cache. There is nothing above this folder. My docker settings: nachoserver-diagnostics-20250624-1837.zip

-
This resolved my issues. Many thanks! If anyone sees this, your codecs are located here: https://support.plex.tv/articles/202915258-where-is-the-plex-media-server-data-directory-located/ Delete the whole "codecs" folder.
-
Thanks for your help with this. I have moved disks and parity is rebuilding now. Good to know on the CRC. I will monitor it for now. I have 10 drives of varying size. It would be ideal to pare them down so that I am not using SATA power splitters. Which I am now, and could be causing these issues? I am using a SAS HBA for the disks that have issues now.
-
The disk that was tossing errors "Raw read error rate" (raw value of 1) is now zero. "Returned to normal". However the Multi zone error rate is still 1. Now my Parity disk has a Raw read error rate of 1, and UDMA CRC error count of 53. So something is up. But I am not sure how to keep chasing this one. I do have 1 8TB drive with less then 48 hours on it so my plan was to put that in the parity slot. Then build parity. Once that was correct I was going to replace all my 4tb with new 8tb disks. I guess my question now is, I can just shut down, remove the parity disk, add the new parity disk, boot up and let it build right? Looking at this (https://docs.unraid.net/legacy/FAQ/parity-swap-procedure/), I am right. But maybe I am doing it wrong lol This procedure is strictly for replacing data drives in an Unraid array. If all you want to do is replace your Parity drive with a larger one, then you don't need the Parity Swap procedure. Just remove the old parity drive and add the new one, and start the array. The process of building parity will immediately begin. (If something goes wrong, you still have the old parity drive that you can put back!)
-
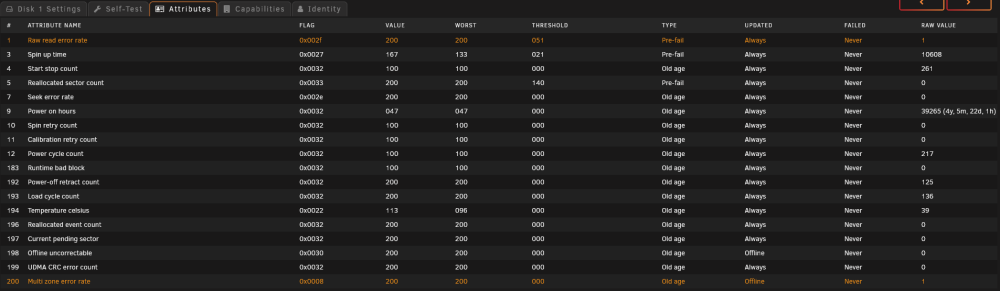
I added 1 and 200 to all my WD drives. Disk 1 popped alerts right away. Another disk has those same values for 1 and 200. But its not in error.
-
nachoserver-diagnostics-20240105-0827.zipAttached is the diagnostics export.
-
For the last 5 days I have been getting notified that the health check of my disks is failing. One disk in particular "disk1" is having read errors. When I run a SMART test, both short and extended, it says PASSED. I will note that my extended test took like 8 hours to complete. Is there a next step to testing the drive or gathering additional info on the "read" errors? Would it be the FS that is causing it? I have attached the SMART logs. Thank you. SMART-REPORT.txt
-
After correcting all those settings (following my guide and the one @itimpi suggested) then allowing the parity check to complete. I rebooted and it was fine. Then I rebooted an hour ago and it was unclean again. It seems like progress, since I was not able to get a clean reboot since spring.
-
I adjusted it from the default value today. The array is doing a parity check now (from the unclean shutdown) so I will have to wait to test until after. My timeout now is 7 minutes (420 seconds) on the array. It was 1.5 minutes (90 seconds)
-
I had not read that one, but I have now. The only differing info from the post I linked above was about the docker container shutdown and SMB / NFS mounts. I set my docker containers to 30 seconds from 10 seconds (default). My remote server (Unassigned Devices remote shares) is not offline when my main server goes down. Today it was definitely up. I tested them today and they all took about 2 seconds to unmounted. My remote shares are for my backup server. Additionally I set the timers the same as Dlandon suggested in my link above.
-
My system shutdown normally until did the 6.12 update earlier this year. (pretty sure that was the version that started it. It was spring I think this all started). I have read this thread (by dlandon) and made the changes suggested, but have not had the chance to test yet: I was hoping someone could help me figure out what the logs say is the reason for my unclean shutdowns. I have not had a clean shutdown since spring. If I stop the full array and then reboot / shutdown, everything is fine. But I shouldn't have to do that. I didn't used to have to do that. Thanks nachoserver-diagnostics-20231015-1014.zip
-
allthethings-diagnostics-20220502-2151.zip
-
Here are the diagnostics. allthethings-diagnostics-20220502-2151.7z
-
I have a drive in my array that reports errors. All 4 drives are the same age. They came from a retired WD sentinel. The drive seems to be operating properly. I have put 2TB of data on it. Are these errors of great concern? Do they "resolve" if I overwrite them? I read that can happen. Is there any way to repair the sectors? Can I do anything but replace it? My array is 4 x 4TB disks. WD Blacks model: WDC WD4000F9MZ-76NVPL0 I have 2 cache drives (128GB and 250GB) - No errors, just thought I would supply it in case. Here is the downloaded report: https://pastebin.com/raw/a8b0r7SB







