




musicmann
Members
-
Joined
-
Last visited
-
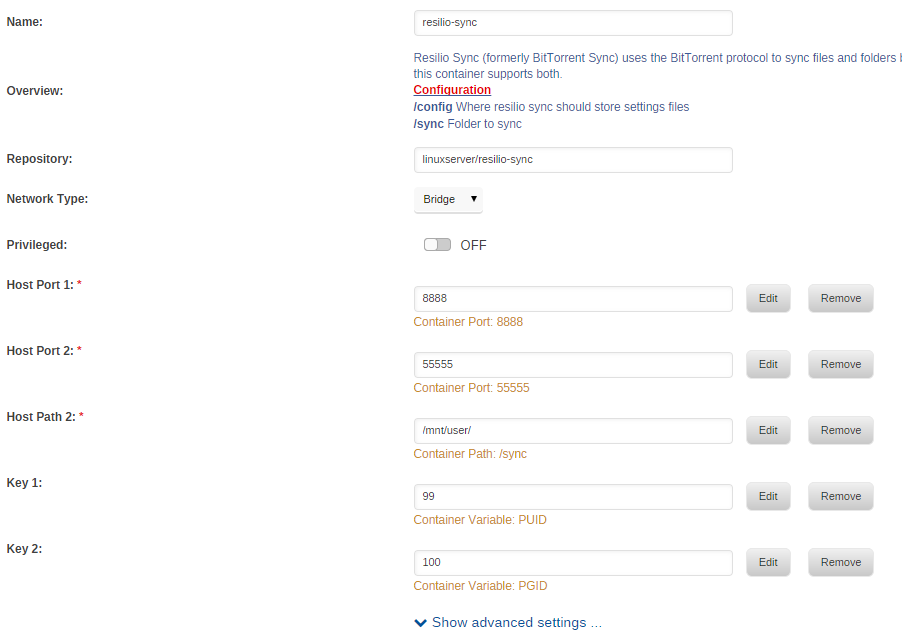
Better luck this time, but still not all the way there. When I restarted the server, at least my dockers and VMs reappeared. The folder seemed to have synced 54.6GB out of 60.0GB (about 35K files out of 56K files). The Sync application on all the machines indicate that Sync *thinks* this folder is complete. Plus the folder size hasn't changed in the last hour since I restarted. I think the setup is correctly syncing the files to the unRAID share. When I connect to the shared folders, I'm able to see all my unRAID shares, and I go into the share I set up for this and create corresponding subfolders. I can browse from a different Windows machine and see the new subfolders and encrypted files. I've attached a screenshot of the docker settings and the sync.conf code is below. { "listening_port" : 55555, "storage_path" : "/config", "vendor" : "docker", "display_new_version": false, "directory_root_policy" : "belowroot", "directory_root" : "/sync/", "webui" : { "listen" : "0.0.0.0:8888", "allow_empty_password" : false, "dir_whitelist" : [ "/sync/folders", "/sync/mounted_folders" ] } }
-
Thanks for the the clarification @CHBMB. I'm running into an issue where the docker seems to be crashing and affecting other things. Background: I'm trying to sync my 3 production computers (work desktop, home desktop, and laptop), and I want a "backup" and always-on node on unRAID. The 3 production computers all have Windows Bitlocker enabled, so those contents are encrypted at the disk level (though, of course, they look unencrypted to Resilio Sync). I'm using encrypted folders in Sync in order that have the unRAID node's contents encrypted at rest. Last night, my initial test worked. I encrypted a small folder (less than 200MB) from work desktop. I created an encrypted node on unRAID and synced. I then shut down work desktop, and I was able to add home desktop and have it successfully sync unencrypted. Overnight, I set the main folder (60GB) to sync. When I checked it in the morning, about 30GB had synced. However, when I went to the Docker tab, there were no dockers listed (previously, I also had Plex installed). Reading some of the other troubleshooting comments, I decided to 1) disable Dockers in settings, 2) delete docker.img, 3) re-enabled Dockers now with a larger image size (now 30GB). I resintalled Plex and Resilio Sync dockers. Again, I was able to sync the smaller folder, but the larger folder created problems. Docker page and VM page are now showing nothing installed. No shares are available either. A parity sync is still running from having to do an unclean shutdown after the overnight crash. Any help troubleshooting and resolving this will be greatly appreciated. I'll probably need to be pointed in the right direction for things like pulling log files and seeing run commands. Thanks
-
Thanks for the docker! I was a user of Windows Live Mesh until it went EOL. Then I was a user of LogMeIn Cubby until it went EOL. I'm hoping Resilio Sync will be a horse I can ride for a very long time. I'm able to get the docker to work when I map /sync --> /mnt/user/ However, I really want to map /sync to a share I've created (called: Resilio-Sync). Is there a way to do this? I've tried /sync --> /mnt/user/Resilio-Sync/ and got the error "your config file prevents you from accessing this directory" when I tried to set the default directory in the GUI. I also tried /sync --> /Resilio-Sync/ which seemed to give an error when when I tried to connect to a folder synced to another machine. Am I missing something obvious? Thanks in advance
