




TheIronAngel
Members
-
Joined
-
Last visited
Everything posted by TheIronAngel
-
Hi all, is anyone else getting or knows how to resolve the error "A device attached to the system is not functioning" when trying to access an array share that is passed through as a disk via the VM configuration? The drive is accessible after a fresh restart and you can browse/create/delete files via the VM mount. It appears to also remain working as long as there is at least periodic activity like a file copy or download. But, after an undetermined amount of inactive time (more than 15 minutes) the VM is, at first very slow to access the drive then after finally opening and trying to browse a folder results in the above error message. It is a Windows 10 Pro VM, latest updates with the VirtIO drivers installed. None of the array disks are sleeping and the share is perfectly accessible from other network machines and the WebUI. The VM can access other shares from the UNRAID box that are mapped as a network location. I don't see anything glaringly obvious in Services that should be running but isn't. Restarting the VM isn't a major before doing something as its mostly just a convenience thing but would like to not have to 'work around' the error
-
Morning, I've finished maintenence and installed a new hotspare for the array. Once I took the array offline and installed the new disk Unraid stopped responding to network requests other than Ping so I had to force a shutdown. After reboot, the array came online and Data Disk 2 is now showing 10TB As you can see, Parity check is also running (Removed a drive from the array in addition to an unclean shutdown) - still not sure why it didn't expand the cap on rebuild but all things are back as they should be. Time to leave it alone until the next bad drive XD

-
Attached Hmm, that would make sense, will update on Saturday when I restart it unless there is an actual proceedure to follow diskstation2-diagnostics-20230525-0644.zip
-
Hey, I've done a cursory Google search for this info but haven't found anyone with exactly the same issue that I'm having. As the title states I've done a drive replacement in my array with a unit that is 'larger' than the original drive but it hasn't expanded the file system to use the new space. Is there something I'm missing to get it to expand the FS on the drive? More info: I had an 8TB drive that, after a parity check ended, had spit out 1100+ Reported uncorrect and 350,000+ Reallocated sector count so I decided to proactively replace the drive with the 10TB hot spare before UNRAID marked it bad. I stopped the array, unassigned the 8TB drive and assigned the 'new' 10TB drive. Started the array and let it complete the data rebuild. This process completed normally and all the data was rebuilt onto the new 10TB drive, however, it is reporting that the 10TB drive has a capacity of 8TB and I don't see an obvious way to expand the drive out to the full 10TB. Array information: Parity 1 and Parity 2 are 10TB drives There are already 2 other 10TB drives in the array working normally. The Drive is in XFS format. The array hasn't been restarted after the data has rebuilt. First 2 things that have come to mind: Stop the array and check the disk properties, there might be something there that will allow an expand operation but only when the array is offline. Run a parity check and it may automatically build parity for the last 2TB of the 10TB drive The only reason I haven't tried these yet is this isn't a high priority as I will work on it over the weekend but since that is still a little way away I thought I'd ask the awesome community! Any thoughts or knowledge is, as always, much appreciated!

-
Managed to get it to complete post after using the second newest UEFI image from Gigabyte - there must be something in the newest one that is causing it to throw a tanty. Thanks @MAM59 for the info its interesting to know for any future projects! Will avoid the 5700G for any future projects.
-
That's something I'll certainly try doing, maybe an older version too?
-
Right, that's a given, sorry if I wasn't clear, thats what I'm looking for troubleshooting tips on. It has to be something to do with the HBA in the x16 slot that's causing it to have issues as without the card UNRAID boots normally. Additionally the board sounds the single beep for "POST Complete" and then dispalys out to the flashing underscore. Its like the board is still trying to hand over video to the HBA even though it has been instructed explicitly not to. If there are any settings in the UEFI that I can change outside of force CPU graphics and Displayout via iGPU that might change things, I'm all ears. Unless you're trying to say that this motherboard simply won't work with an LSI2008 controller in the PEX16 slot
-
Hey, I'm trying to troubleshoot an issue with UNRAID where I have an AMD CPU with graphics (2200G) in a Gigabyte B450M S2H motherboard with an HBA. This motherboard only has 1x16 slot and 2x1 slots for expansion. I first tested the machine without any drives installed to ensure UNRIAD boots normally and get all the apps and what not installed and didn't have any issues at all. I set the UEFI/BIOS settings to Force on CPU graphics: Enabled and to Prefer iGPU as the startup display output instead of the default PEX16 slot. I then rebooted without HBA to confirm settings don't have an issue and all was working. Once I had the HBA installed in the PEX16 slot the machine now beeps for post but starts to a flashing underscore and does nothing else. I can't see UNRAID on the network and it reboots with CTRL-ALT-DEL commands as well as turns off instantly with the power button which indicates to me that the OS hasn't started at all I've flashed the most recent BIOS to the board already and can't install the HBA in any of the other slots as the card won't fit in them due to the slot not being 'open' at the end like in server boards. I know the HBA works as I was freshly using it in an intel system with iGPU in the PEX16 slot and didn't have any issues. I don't need a video card in the system hence I have installed the x8 HBA into the x16 slot. All drives are empty on the connected HBA as they are fresly pre-cleared after being removed from another array and getting a wipe and re-preclear. I've put a pin in the project for the day since it's at work but thought I'd consult the forum experts to see if they've seen anything like this. I did try my Google-Fu before posting but could only find people who were able to get UNRAID to start but not show a GUI on the host - as in, they could communicate over the network to the box. I can't. During my digging I've found these 2 things I can try tomorrow, is there anything else I should add to this list: Reflash the BIOS (just in case) Manually set the PCIe version to the correct one for the card as AutoNeg might not be setting correctly.
-
Would it be even worth attempting a rebuild using PD1 or just scrap them? I've realised how dumb this idea is since the array has been online and the parity will now be *very* out of sync - unless you guys have something you can recommend trying I'll dump the old Parity disks out tomorrow, install the new ones and and rebuild with them. As mentioned before now that I have a file list of what was on D23 I can easily replace the missing content much quicker than checking every single folder for missing data so it's not all that much of a time sink. I think I'll have to raw-dog the new drives striaght into production as I simply don't have the time to wait for a full Read/Write/Read clear of the drive - I will make it known that I would really prefer to burn in the new drives with a complete preclear but these are brand new Ironwolf units so I have a baseline trust that they work out of the box and as it stands right now getting some form of parity protection on the array is more important that running a preclear on brand new disks.
-
It is indeed a white label unit. I can see why you wouldn't trust them, I've lost trust in them too now to be honest. Although it has a 1yr warranty I think I'll avoid them going forward. Not worth the hassle but I'll still get them RMA'd since they're only a little over a month old. Unraid has disabled the disk after 11,166 read errors.
-
@trurl @JorgeB Looks like the parity disk is bad after all, any insight into the current status from a diag? It got 625GB into the rebuild before getting marked bad again. Since I only attempted a rebuild using PD2 do you think it would be possible for me to complete the same steps again this time with PD1 as the parity disk or is it time to call it unrecoverable? Since I was able to emulate the disk I know exactly what was stored on the drive so recovering the information shouldn't be particularly difficult. diskstation2-diagnostics-20221230-0136.zip
-
Much appreciated for all your help guys, I have the rebuild of D23 running to the pre-cleared hot spare and another preclear is running on the new 10TB drives before I use them. I wasn't expecting to get anything back from that disk but y'all are miracle workers and looks like everything is back! Happy new year to you all!
-
Dear lord, you can checkfs an emaulated disk - OK, done and remounted the array in online mode, disk is mounted and only 83GB in L+F out of 1.6TB on the disk - That is monstrously good. Am I correct in assuming the process to complete will be as Follows: Offline array --> Assign replacement disk23 -> rebuild data Once data rebuild is complete --> offline array --> Assign Parity Disk 1 --> rebuild Parity Done after that right?
-
Both Parity disks completed the extended SMART test and I've followed your instructions, unfortunately disk23 does not emulate and just comes up as 'Unmountable: Wrong or no filesystem' I also had a swathe of UDMA CRC errors on restarting the array however its not confined to one backplane or expander as only some disks on Row 2, 3 and 5 in the diskshelf got them as well as a couple of disks in that were on internal headers on the master controller (not in the disk shelf at all) - I'm not really sure what to make of that other than 'meh, UDMA CRC error, not a major issue' Diags attached for checking and I've stopped the array diskstation2-diagnostics-20221229-1558.zip
-
Interesting, thanks for the info, I just checked my scheduled parity check settings and looks like I have mine setup the way you have described unless the settings aren't accurate until the array is online. If I'm not mistaken the last notification from UNRAID was: Error code: aborted Finding 3584 errors Last month's Parity check completed without issue and no hardware has been changed between parity checks so those errors are new. I won't speculate further on the cause or if the errors are actually errors or schmoo from a disk about to blow as its getting a bit to far into the unknowable to be worth any real consideration but wanted to at least offer the information. This whole experience has been very enlightening and educational!
-
Wow, magic right there! I feel very much vindicated in going UNRAID for this, I'm almost 100% Certain that nothing has been written to that disk in a long time due to all of my shares being set to 'High water' mode - a disk much higher on the list (lower in number) has been getting the writes recently and not much as been added to the array as well. Excellent, thank you very much - I'll let you know what the result of the SMART Extended test is for the drives and whether or not I'll be trying that process. Let me know if I'm out of field here but I have a couple of last questions before I let this run and take a break from asking you wonderful people questions: 1: Is it possible that UNRAID failed the parity disks due to garbage data coming from the drive that eventually failed during the parity check? 2: On that same note: Hypothetically speaking, if a parity check starts and a drive in the array is spitting out bad data would this corrupt parity data? Would UNRAID be able to detect that the drive is sending schmoo or would it assume that what the drive reads out is correct? Thank you so much JorgeB and trurl for the time that you've taken out of your day, especially being that its the festive season, to help read logs and answer my questions, it is all very, very much appreciated.
-
SMART Extended test has started on both of the Parity drives, by the time this has finished I image the replacement drives will have arrived or will be close to arriving (ETA~16 hours for test.) Providing one or both of them pass an extended test I'd like to attempt to re-enable parity, admittedly I'm a little lazy and don't want to manually replace the data on the missing disk if I can help it given we're in the holiday season I have things I would rather do. Can you point me at the resource to follow for re-enabling parity - at this point my assumption would be, as mentioned before, the 'new config' and select 'parity data is valid option' but really would prefer that to be confirmed before I do something I can't simply 'ctrl+z' if you know what I mean. I hope you don't mind me asking, I love to know what most people would call 'irrelevant information' and tend to ask a lot of curiosity questions. Do you know what would be the result of parity data that isn't completely correct? Would ALL reconstructed data be bad or only parts of the data? Since I have 2 parity drives that failed with an hours gap would I be better off only re-enabling one of the parity drives (the last one to be marked failed) or both?
-
The drive is in a 20-bay expander, I've swapped it from position 3-4 to 4-2 (Row/Col) this was a swap with disk ending ZAD70MFR (Disk22/sdr) - MFR registered in the new bay but 5W9 did not - I've swapped them back to their original locations and the same has resulted. This expander uses 5 seperate backplanes (1 for each row) the impacted disks PD1/PD2/D23 are in position 1-1 1-2 and 3-4 respectively all other disks on Row 1 and Row 3 are working A-OK. Reasonably sure there isn't an issue with the Backplane, SAS cable, SAS Expander and Controller but happy to test anything - I work in IT myself so I've seen weirder things cause issues
-
Hi JorgeB, I've shutdown the system and rebooted earlier in the day (about 9 hours ago) to work on another machine in the rack. It has rebooted with the exact same 3 disks marked faulty and the array cannot be started. Even if I replace the missing data disk with the 'spare' that is installed UNRAID still reports an invalid config and won't start the arrage (Too many wrong and/or missing disks!). I can do another reboot if you'd like but I've attached a fresh diag that I've just generated as well as a screenshot of all disks in the system. diskstation2-diagnostics-20221228-2226.zip
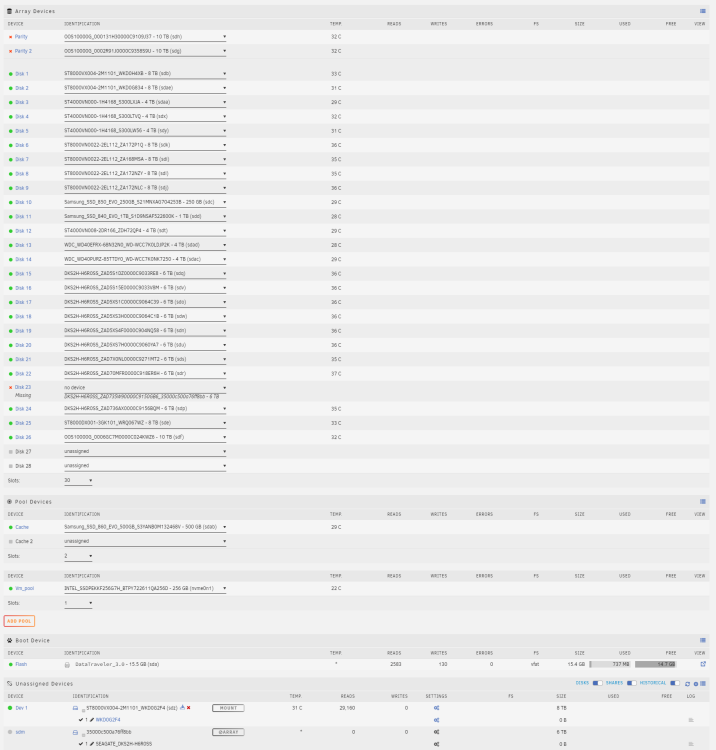
-
If I add the hotspare into D23's place the array still calls 'Invalid configuration.' and won't allow a start. I'm assuming you want me to force the parity disks online using New Config --> Same as old + replaced D23 --> Parity is valid and test? Happy to wait for JorgeB to chime in before I do anything if you think thats best though.
-
Only 1 with a SMART warning is the hotspare Dev1 (ST8000VX004-2M1101) which has had 1 Reported Uncorrect for a couple of months and hasn't degraded further since (has been pre-cleared probably another 20 times since it got removed from the array in attempt to force a fail as its still in warranty until Feb)
-
D26 is an identical drive to PD1 and PD2 - it's SMART info is basically the same across all 3 of them. They are refurb disks so I have a suspicion that SMART data isn't reported correctly on them. I have 2x new 10TB IronWolf disks on order for collection tomorrow so will be able to replace them with name brand disks shortly. I also still have warranty on all 10TB disks (purchased Nov this year - I even triple pre-cleared since they were refurbs)
-
SDM is in UD section however it looks like it's spun down and can't be spun up: Also when investigating the disk by clicking on sdm none of the typical data is shown. It's also not able to be added to the D23 slot in the array. Seems like the disk is badly in-op

-
diskstation2-diagnostics-20221228-1058.z Hi Trurl, thanks for the reply, much appreciated - here is the Diag Zip
-
Hi Guys, as in the title, this is my first multi-drive failure with UNRAID. Contrary to what I would have expected from waking up to multiple dead drives I'm actually somewhat excited to learn the process of recovering from a situation like this. I have an array of 26+2 and 3 drives have spat the dummy - one of the main reasons I picked UNRAID was for this exact situation, if more drives than parity can restore detonate then you only lose the data on the drives that turned themselves into paper weights. At this point in time I have 2 failed Parity disks and 1 data disk that decided to grenade itself after parity went bye-bye. Timeline: Midnight - Routine Parity check starts ~2am - Parity disk 1 starts throwing errors and gets marked bad ~3am - Parity disk 2 starts throwing errors and gets marked bad ~3:30am - Disk 23 starts throwing 'Sector 1 unreadable' ~3:50am - I notice issues with server and start troubleshooting ~4am Drive goes from 'Unmountable' to 'Missing' after restarting server 4:30 - Here we are at time of writing Troubleshooting: So, for troubleshooting of all disks I've done the basics: Restart the server Power Cycle the disk shelf For Parity 1 and 2 - Both are SAS (PD1 and PD2) SMART DST - Pass - I suspect they are still functional and contain valid parity data as everything that gets written to the array gets written to Cache first and transferred to disk at 6am logs show IO errors on at least PD1, I'm revising my opinion here, both have probably taken an arrow to the knee. For Disk 23 - SAS (D23) Reconnect the drive in the same bay slot - Still not detected Swap the drive to another bay in the chassis (on a different backplane) - No detect Conclusion: Here is my conclusion, Please do tell me if you think there is something else I can/should do before moving on: D23 going Dodo would have been recoverable in addition to PD1 so long as PD2 hadn't also decided to fall flat on its face. Unfortunately with all 3 drives marked bad by UNRAID this means that the array is 'unrecoverable' in a traditional sense. I have a hot spare disk that I could use to replace D23 literally installed and waiting, and can get a couple of disks for the Parity drives later today to build a new array but I want to keep the data on all other disks. Boiled down, I have to replace the failed drives and create a new array config with new drives maintaining disk order to keep data on the drives that aren't dead but... Questions: 1: I have 23 other disks from this array all with information on them and I would like to keep the information on these disks - I understand that this should be possible when creating a new config with the drives but I would like someone with experience to point me to the right resource or 'hold my hand' while doing this for the first time to make sure I don't do something dumb. Things like letting me know of any risks/things to be aware of when doing this would also be very much appreciated! 2: Why did I say 23 and not 25 'other disks'? I added 2 disks within the last 30 days and, as of ~6 hours prior to the failure, neither of them had anything stored on them yet. My question is: One of these drives happens to be the right size to become a parity disk, would it be possible to remove this disk and assign it as parity instead of buying a replacement or would doing this be a case of 'don't know what could happen, just be safe and don't do it' recommendation? 3: Is it possible that the 2 Parity drives are A-OK (they pass SMART etc.) and could be forced to resume opteration in an attempt to restore the data on failed D23 to the hot spare before getting the parity drives replaced just in case? 4: If option 3 were tried what possible issues could occur if the parity drives aren't 'dead' but just not reading correctly? Would D23's content be mangled and unusable or worse - like, rest of the array data takes a grenade? - AKA, is this something reasonably low risk and worth trying or something high risk and I should just write off D23 and count my blessings that the other disks aren't FUBAR too? Things to note: Not all data on this array is backed up but all critical files are - any data stored on this array that isn't backed up, primarily - lets say for argument sake - ISOs, is replaceable and only classed as 'nice to have.' If push comes to shove I'm more than capable of manually verifying what ones are missing and re-acquiring anything lost. I'm not in a huge rush to fix this problem so if there are options that take time to try thats fine. Its now 5:55am and I'm going back to bed and will check back in a little while, I can post any information that you would like when I get back up in a couple of hours Earlier in the day I had updated UNRAID 6.11.0 --> 6.11.5 and the unit was awaiting a restart which I was planning on doing after parity check had completed today but had to restart the server during troubleshooting which completed the update - not sure if this is an issue for logs or something.




