getty
Members
-
Joined
-
Last visited
-
Awesome! I will keep an eye on it but the errors seem to have stopped. I was able to locate 2 files causing csum errors in my cache scrub. I deleted them and let them be rebuilt by Docker, rescrubbed, and ran the script to clear errors and it is all ok for now. Thanks so much for the assistance! Will probably look into an M.2 replacement for cache sooner than later.
-
Currently running the memtest off a USB as I'm UEFI. It doesn't appear to be finding any errors though. Edit: memtest completed and is reporting 0 errors or ECC errors.
-
Ok I'll give it a go tonight. Just pick the memtest86+ option at boot? Is there anything I should be looking for to post here for results?
-
Attached here. Thank you for looking into this with me! tower-diagnostics-20230509-1213.zip
-
May 8 22:32:58 Tower kernel: BTRFS error (device sdc1): bdev /dev/sdc1 errs: wr 0, rd 0, flush 0, corrupt 14420370, gen 0 May 8 22:33:31 Tower kernel: BTRFS warning (device sdc1): csum failed root 5 ino 100152063 off 1343488 csum 0xfb571968 expected csum 0x15800c92 mirror 1 May 8 22:33:31 Tower kernel: BTRFS error (device sdc1): bdev /dev/sdc1 errs: wr 0, rd 0, flush 0, corrupt 14420371, gen 0 May 8 22:38:32 Tower kernel: BTRFS warning (device sdc1): csum failed root 5 ino 100152063 off 1343488 csum 0xfb571968 expected csum 0x15800c92 mirror 1 May 8 22:38:32 Tower kernel: BTRFS error (device sdc1): bdev /dev/sdc1 errs: wr 0, rd 0, flush 0, corrupt 14420372, gen 0 May 8 22:38:32 Tower kernel: BTRFS warning (device sdc1): csum failed root 5 ino 100152063 off 1343488 csum 0xfb571968 expected csum 0x15800c92 mirror 1 May 8 22:38:32 Tower kernel: BTRFS error (device sdc1): bdev /dev/sdc1 errs: wr 0, rd 0, flush 0, corrupt 14420373, gen 0 May 8 22:38:33 Tower kernel: BTRFS warning (device sdc1): csum failed root 5 ino 100152063 off 1343488 csum 0xfb571968 expected csum 0x15800c92 mirror 1 May 8 22:38:33 Tower kernel: BTRFS error (device sdc1): bdev /dev/sdc1 errs: wr 0, rd 0, flush 0, corrupt 14420374, gen 0 May 8 22:38:33 Tower kernel: BTRFS warning (device sdc1): csum failed root 5 ino 100152063 off 1343488 csum 0xfb571968 expected csum 0x15800c92 mirror 1 May 8 22:38:33 Tower kernel: BTRFS error (device sdc1): bdev /dev/sdc1 errs: wr 0, rd 0, flush 0, corrupt 14420375, gen 0 May 8 22:38:38 Tower kernel: BTRFS warning (device sdc1): csum failed root 5 ino 100152063 off 1343488 csum 0xfb571968 expected csum 0x15800c92 mirror 1 May 8 22:38:38 Tower kernel: BTRFS error (device sdc1): bdev /dev/sdc1 errs: wr 0, rd 0, flush 0, corrupt 14420376, gen 0 May 8 22:38:38 Tower kernel: BTRFS warning (device sdc1): csum failed root 5 ino 100152063 off 1343488 csum 0xfb571968 expected csum 0x15800c92 mirror 1 May 8 22:38:38 Tower kernel: BTRFS error (device sdc1): bdev /dev/sdc1 errs: wr 0, rd 0, flush 0, corrupt 14420377, gen 0 May 8 22:38:38 Tower kernel: BTRFS warning (device sdc1): csum failed root 5 ino 100152063 off 1343488 csum 0xfb571968 expected csum 0x15800c92 mirror 1 May 8 22:38:38 Tower kernel: BTRFS error (device sdc1): bdev /dev/sdc1 errs: wr 0, rd 0, flush 0, corrupt 14420378, gen 0 May 8 22:40:26 Tower kernel: BTRFS warning (device sdc1): csum failed root 5 ino 100152063 off 1343488 csum 0xfb571968 expected csum 0x15800c92 mirror 1 May 8 22:40:26 Tower kernel: BTRFS error (device sdc1): bdev /dev/sdc1 errs: wr 0, rd 0, flush 0, corrupt 14420379, gen 0 Good Evening, I am seeing the above errors coming through my server when I view the cache log. I am looking for any information on what could be causing (is it a cache disk going bad, some other issue, etc) My cache is on an SSD albeit not a super new SSD, but an ADATA drive. Do these errors matter, are they causing issues, could I be losing data, etc are all my questions. Looking for the way forward here. Any and all information helps. My RAM is running at 2133 (I thought maybe it was a RAM issue based on other forum posts but as seen above the warnings and errors reference SDC1, my cache device.) Edit to add: I have run a scrub and no errors are found. I am not noticing any degradation to my server functionality but the errors concern me because they look scary.
-
Yep. They have been working for a couple years in this set up with no issues whatsoever. Per those logs, Radarr just up and deleted everything. The logs look as though I had logged into my radarr and just hit the delete all button. Which of course I didn't do.
-
Welp... here's my radarr log that I just found showing that it decided to delete all my movie files..... Excellent. Logs here in case you have experience with this. Else I will post in Radarr forums.radarr.3.txtradarr.2.txt
-
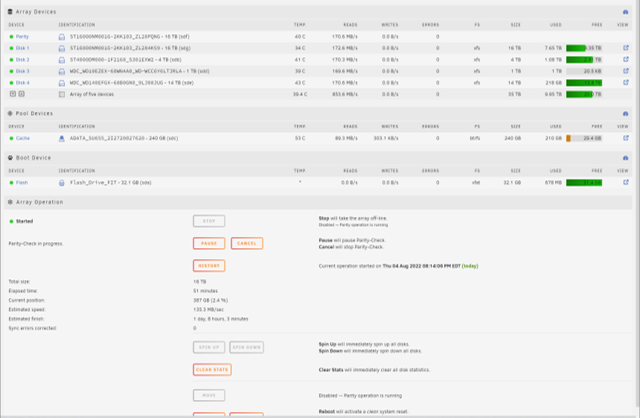
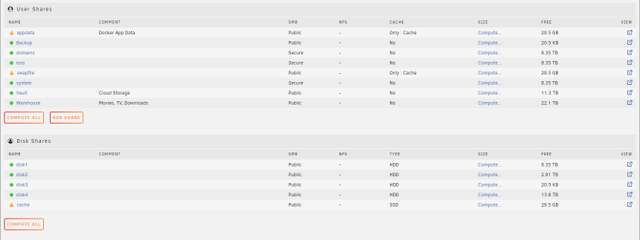
Any ideas why system, isos, and domain are reporting 8.35 TB? There's no way they're that large right? Trying to nail down if there's an issue or if one of my Dockers somehow took an axe to my files. I suppose either Plex, radarr or sonarr could be the culprit but I'm not sure why that would happen out of the blue after running happily for years.
-
Diagnostics folder attached. Unfortunately, like I said in my first post I restarted my system and so there is no longer log data from the uptime where the issue took place/started. I hope these help. Sorry for not including them to start, I am learning. tower-diagnostics-20220804-2157.zip
-
I am currently in the middle of a parity check on my large media server running Unraid 6.10.3. I opened plex tonight to find that only 29 movies of my 3000 movie library were present. I immediately ran to my pc to access the unraid gui and to my dismay, the share holding my movies and tv shows was showing half full (only the tv shows and 29 movies remained). Additionally, my separate 1TB disk containing backups of my appdata was totally empty in the gui. A separate disk housing a nextcloud file storage seems unaffected. I am trying to figure out what could have caused this to happen and if there is any coming back from it or if the files are still there but the filesystem is corrupt. Here are the details of my system. Main Shares As you can see, disk1 is only half full. Prior to this occurance, that disk was nearly full. The Warehouse share is a High-Water share using disks 1 and 4. The Backup share utilizes disk3 only housed my appdata backups. The cache disk currently holds my backups. The Vault share utilizes only disk2 and appears unaffected by my issues. Of note, system, isos, and domains are each showing as 8.35 TB. This is leading me to suspect a filesystem issue but I don't know what to do. All command line to show partitions shows matching information to what Unraid gui shows. I feel I am in over my head with these issues despite being pretty good with understanding and managing my Unraid and previous Linux/Docker setups and I am looking for any guidance. Thanks so much for any and all help. (I am a dingus and restarted the system before copying down any logs. Sorry)