ykozovsk
Members
-
Joined
-
Last visited
-
Absolutely agree. I actually got a refurb 18tb Seagate Exos off Ebay for a very competitive price per TB. I plan on getting more to replace all the SMR's. Even the brand new ones are at a decent price. Yup, I had one of my 8tb Seagate SMRs as parity when I was first testing UnRAID and quickly learned my lesson. Although I get SMRs would work fine for media or any high read/low write scenarios, its not something I want to deal with as who knows when I need to do a large data dump write situation. Even now, I am still continuing the transfer onto the SMR drives until I get the CMR replacements and its taking FOREVER (might be another week or more at this rate).
-
Thanks for the clarification and reassurance. I'll definitely try that just for my piece of mind. On top of this, I am 950GB deep into the transfer to the single CMR based WD Red Plus drive with no issues whatsoever so far. I expect this entire test transfer to finish without slowdowns. What a pain these SMR drives are. I know they are a cost effective solution in most scenarios but damn I will never use one again, especially in a server environment.
-
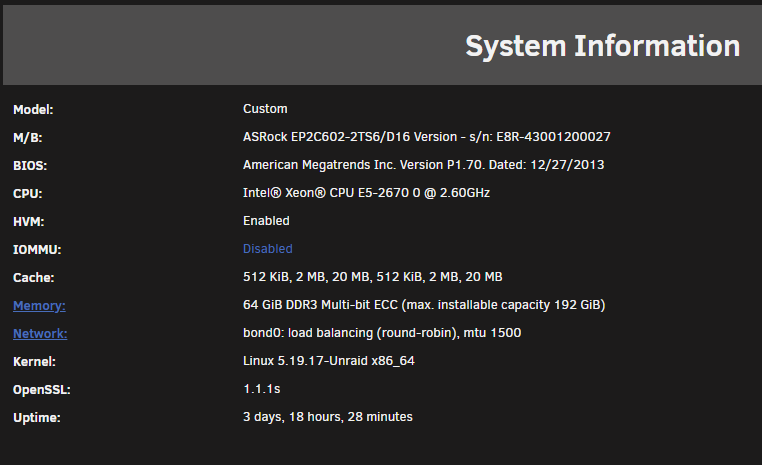
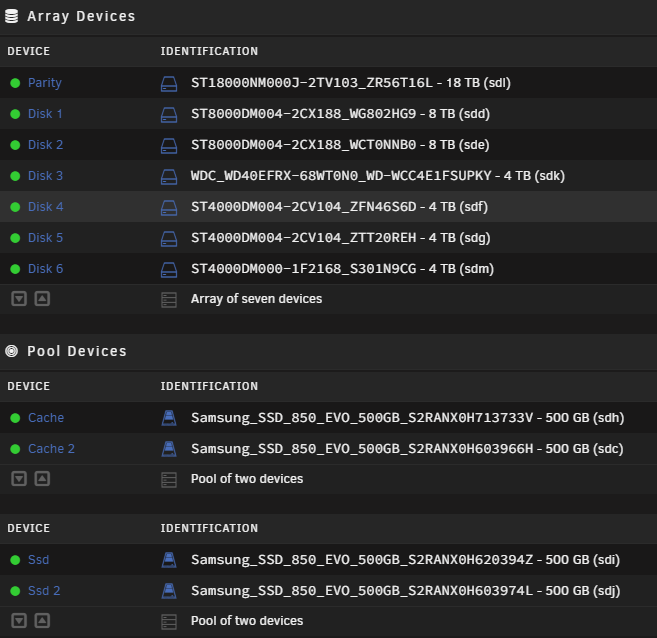
Hi all, New to UnRAID, been using a TrueNAS Scale server for about a year now. The plan is to have both running with their own specific use cases. My intent is to transfer many large files (~1-10GB per file, ~13TB total transfer) over to my UnRAID array from my other server, however no matter which method I try, after about 1TB, the transfer ends up slowing down to a crawl and even stalls/halts completely for minutes at a time. Any help would be greatly appreciated in order to diagnose the problem - as I am willing to change hardware etc. in order to make this work properly. System Info: Additional SysInfo: - UnRAID Version: 6.11.5 - Dual E5-2670 CPUs - 10G network, both servers bonded via Netgear XS708E switch - Hard drives: (note the parity drive is CMR) Transfer Attempt Details All attempts below have resulted in a major crawl (under 5MB/s, average less than 1MB/s) and ultimately a complete stall for ~30 seconds at a time after about 500GB-1TB of transfer. The initial data transfer goes great (~50MB/s without turbowrite, ~120MB/s with Turbowrite), but then hits a roadblock at that total data transfer amount. 1. Attempted transfer via SMB (from TrueNAS Scale server) using Unassigned Devices plugin through a third windows-based PC. 2. Adjusted Turbowrite on and off, same results. 3. Adjusted Disk Cache vm.dirty_ratio and vm.dirty_background_ratio to various values to isolate potential RAM cache situation 4. Attempted transfer via SMB thru Krusader on UnRAID machine, bypassing Windows-based PC 5. Mounted same source share on TrueNAS server via NFS to isolate potential SMB issue, same results 6. Thinking it might be a network issue at this point, copied over 6TB of data to an external USB harddrive, connected to UnRAID server via USB and mounted drive via Unassigned Devices. Initiated transfer via Krusader, SAME RESULTS! Note that I initially used the SSD cache and the transfer seemed fine, but since the cache is 500gb I'm not surprised it didn't create the issue as it always occurred after 500gb of transfer. But on an important note, when I tried to run the mover manually, the transfer from cache to the array did end up stalling in the same way. I believe this was after I turned off SSD caching, initiated the transfer and went direct to array and recreated the issue, then starting the mover had the same effect of stalling immediately. I am starting to think the issue lies with the SMR drives being used (as highwater is set, data is going to ST8000DM004 Seagate Barricudas at this point). I just wouldn't think it would be THIS significant of an issue as I expected a blip in transfers here and there but not a complete stall. I even ran DiskSpeed and tested all drive and controller speeds and everything is benchmarking fine with no bottlenecking. The issue resolves when I restart the server and/or the array, however once a newly initiated transfer hits the ~500gb-1TB amount, it happens again. Anyone have any pointers or things I can further test before I go and replace these drives with CMRs? Could this be caused by something else I am overlooking? During the writing of this post I realized that one of the drives in the array is indeed CMR, so my next test will be a direct copy to disk (3) to see if the issue occurs as no data has been copied there as of yet. One of the reasons I think the issue is due to a large copy to an SMR drive is from this post: Greatly appreciate the help!