




Cody Peters
Members
-
Joined
-
Last visited
Everything posted by Cody Peters
-
Certainly no overprovisioning. Its a fairly powerfull system with lots of ram as you mentioned. Looking at the time stamp... It was not a backup task. I was performing a data dump on the server. In the 200-300GB range. That mover event was manually triggered to get some files off my cache drive. Its possible the cache drive was still being written to during that time. Not sure why the flash backup was running then. Thats an odd time. In unraid connect there is a flash backup setting, with no date or time options. Maybe this triggered it? My back up runs every monday at 2 or 3 AM, so that was not happening then. Its 2 sets of 2x32gb sticks in the correct corresponding spots for dual channel. While I do not have any database specific Dockers. I am sure some of them run databases in their normal operation. But again, this is a fairly powerful system that normally idles around 5% cpu. If its running out of memory, is there a way to allocate more to the system from available/cache? Kinda a silly problem to have for someone who has as much ram as I do. I only have 2 vm's with 12GB allocated. And the dockers which I dont think there is any control over. Knowing that this system idles quite low, I still built it up to be powerfull enough with 10gb nics to take large data dumps at speed. I have never seen this issue before, and updated to 7.0 8 days ago. I am slightly skeptical of that, unless the reporting of the error is a new feature :s Thanks.
-
First time seeing this error. I would be very surprised if its actually an out of memory issue. Per the errors instructions, I am posting here to see if anyone can review my diagnostic logs, which are attached. Thanks! server-diagnostics-20250120-2051.zip
-
Haha, good catch.... what luck to buy 2 drives at the same time with the last 5 digits of the serial matching. Okay, so I will pull the identified failed drive MKM0042000204P1102, let the server rebuild before doing anything else. I am dumbfounded that this has been an issue since 2018. Why why why.... I thought this was me specific, I am very unhappy to see this to be an OS issue.
-
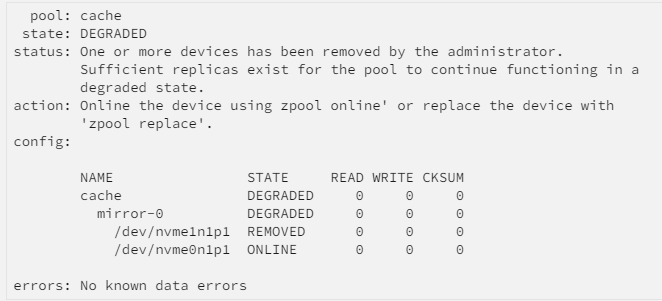
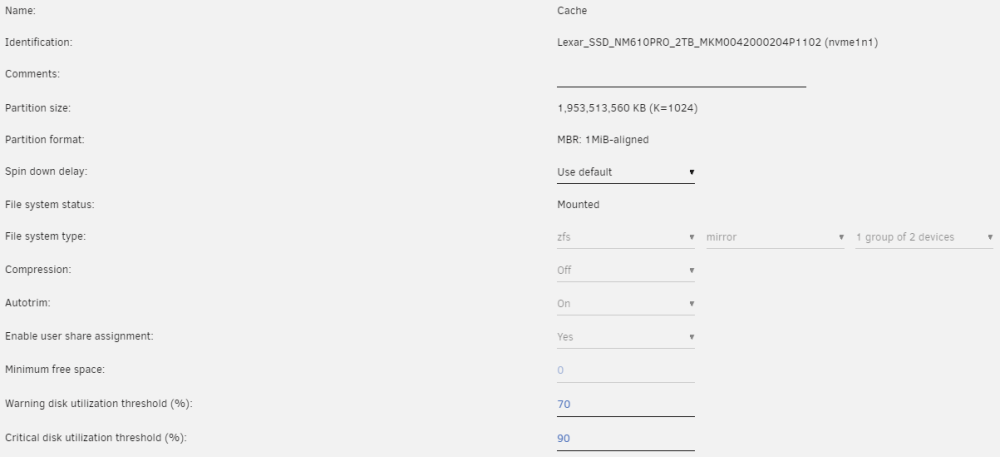
Okay, long story short i hope. I have a ZFS cache pool. It has 2 nvme drives. I never noticed it, but both drives show up with the same serial number like this: I have been fighting some high IOWAIT times for a while now. Finally bit the bullet, and in the process of backing up, taking screenshots of things. I noticed that the serial numbers matched. I thought that was weird, so I went to look into the the Cache drive. And I found this: How could a drive with the same serial propagate into both drive slots? How could an array with a failed drive NOT SAY THERE IS A PROBLEM? For the record, this system has been up for over a year on this hardware. Here is the config for the mirror settings: Going forward to fix this my plan is to LEAVE the drive with serial ending in 1102, and PULL the other drive. Then let a rebuild occur after switching the drive out. Any other ideas? This is wild, that I never got a notification about a degraded drive. Or even an obvious error anywhere, I can only see the issue in the cache drive config page.

-
Thanks for the info, but it turned out to be a random, but not actual ram failure. Its running again and doing a parity check. Seems okay.
-
Awesome, thanks for this information. However, I left it running in safe mode for a bit and it started crashing again. I updated my post.
-
My server is struggling. It died overnight after seeing a bunch of high latency events in my network. I have tested the USB stick, and it seems fine. I initially thought it was my 10GB Mellanox nic, I pulled it, but am still having issues getting the system online. Unable to get a web interface at this point. I can access the terminal from a direct attached monitor and keyboard, but I usually only get a few minutes before the call trace starts and locks me out. Update 1: Safe mode appears to be working ok. Nic card reinstalled. Everything is running. So that means its likely a plugin? Is there any way to re-enable one at a time? Ive seen some mentions of nvidia in the errors. I suspect its an issue with the nvidia driver/plugin, or my video card itself. Update 2: Spoke to soon, still crashing while in safe mode. Picture attached. Console stops working when this happens. Update 3: Decided to run memtest86. Failed. Removed 2 of 4 sticks, passed. Removed the other 2 sticks, put original 2 back in, passed, put all 4 back in, passed.... Ummm. This was a head scratcher. server-diagnostics-20231224-1401.zip
.thumb.jpg.b2b684811a0dc0d7583fed17b5f45425.jpg)
-
Awesome, thanks. Looking forward to the update. As for the GPU thing, it looks like its not actually implemented yet from Dash. The creator wants to, but is not able to test/invest the time into it and is asking for community assistance.
-
Running in bridge mode is not an option. I need to specify the network segment. Is there no workaround aside from being forced to use the listed port. In all fairness, I would argue this is a template issue as its not enforcing the port change to the underlying software. Why have a webui port option if it does not work, regardless of network mode. To confirm, I am not using "bridge" mode. I am trying to use the custom br interfaces, not the host interface.
-
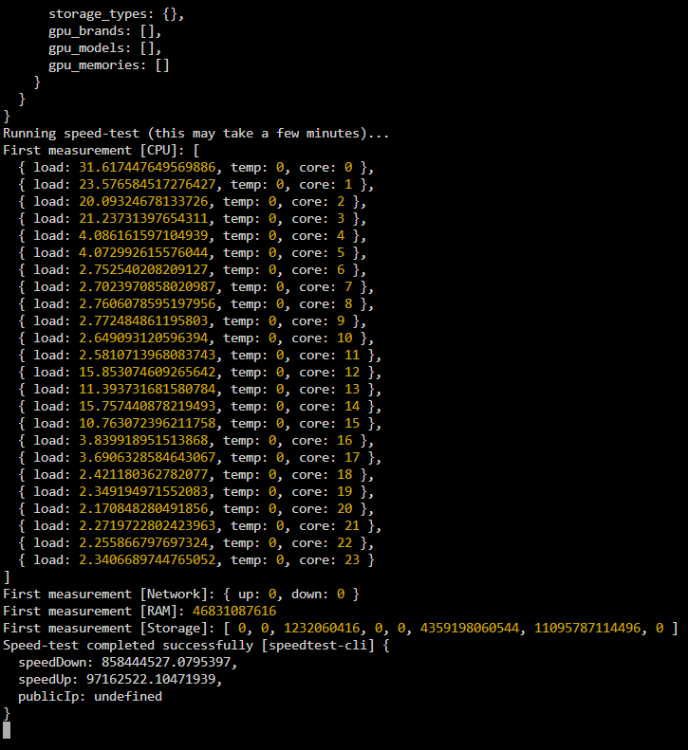
Hello, Having 2 issues. 1: When I change the port, the docker does not launch with the new port number. 3001 is already used by another service. When I change it to 3005 in the WebUI field, it still launches with 3001. 2. When I add the ,gpu tag in the advanced settings, it just hangs after the speed test. No further information available. EDIT: Actually it looks like after a minute or two of running the whole dashboard dies: (regardless of GPU or not)
-
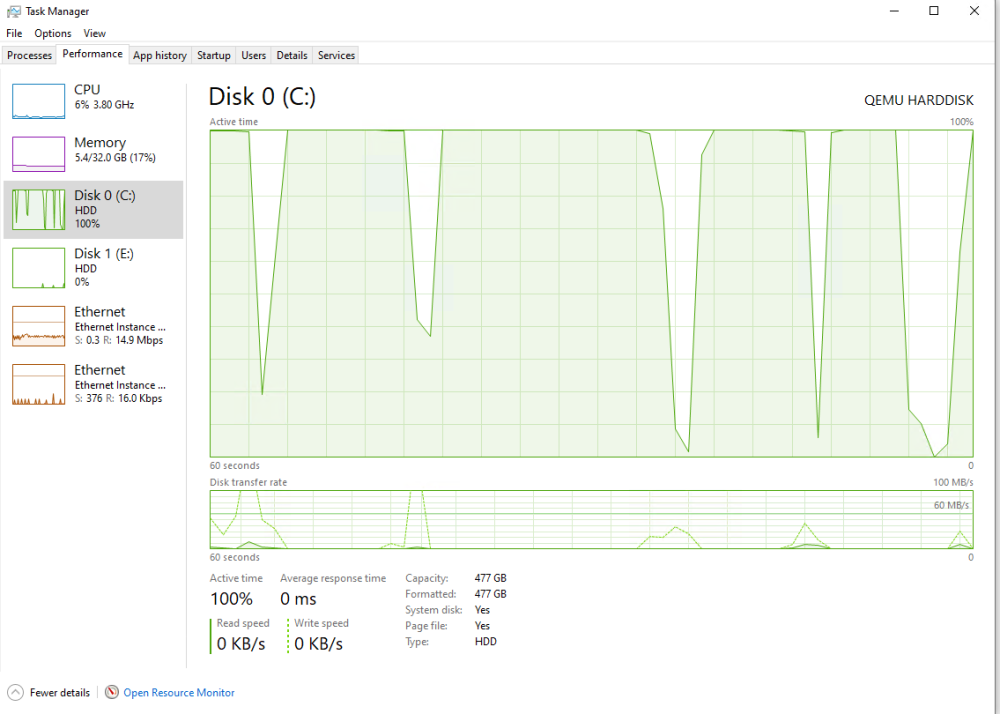
I have a windows VM that has 2 SSD's passed through to it. Not the controllers, just the drives. The main OS drive can sit there and idle fine, but as soon as I start performing write operations, after about 1GB it starts freezing, locking up, pinging out. Eventually it will start to come back to life and I can see in task manager that the drive is 100% utilized. This will continue for a minute or two after the files have stopped moving where they were created, copied or extracted to. I was having this exact same issue when I was running the vm as a disk image on the cache pool and thought the ssd would fix it. I have tested both drives and they have the same behavior. They are connected to different sata controllers, X570 and Asmedia (only one drive is connected). I updated the virtio driver package and saw no change.
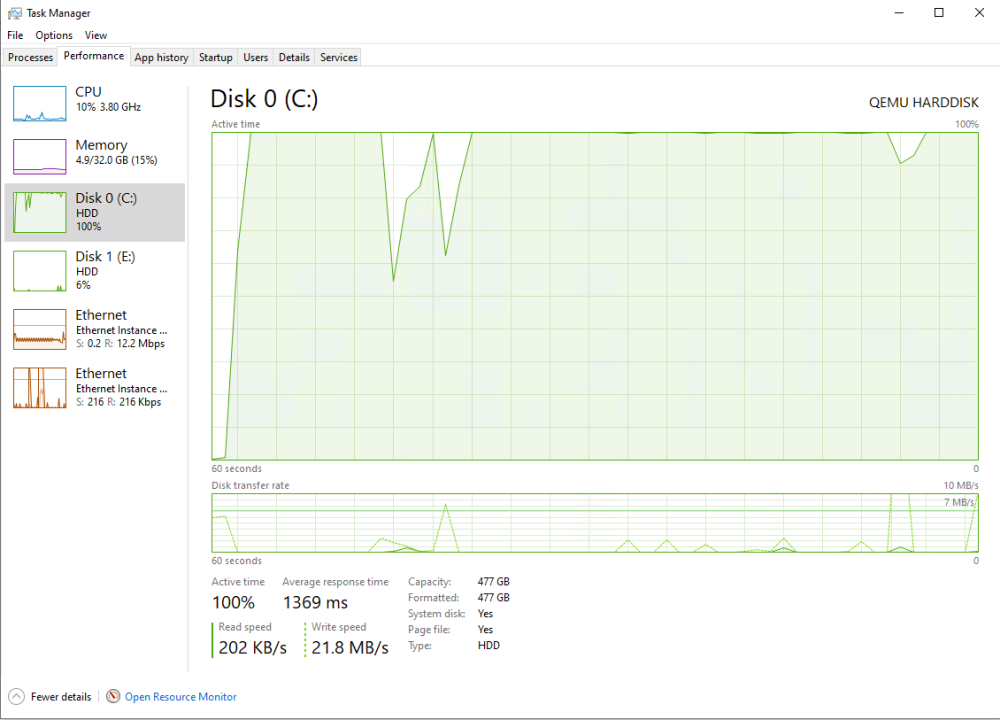
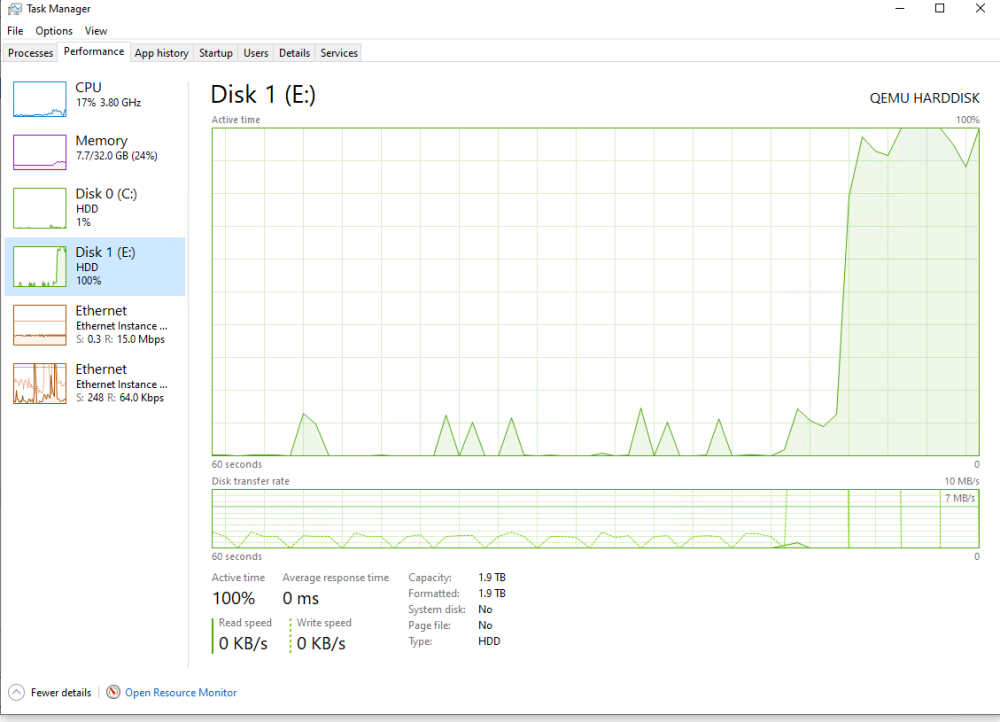
-
Preface: Ryzen 3900x, 2x 2Tb NVME ~3000mbps rated for cache drive, 3 HDD array. All VM's run off the cache, 64GB of ram. CPU is AIO cooled. RTX 3070 for plex transcoding. 1GB RJ45 on board NIC, Mellanox dual 10GB DAC network card. Problems: There are several, but most are related. The unraid interface will occasionally take ~5 seconds to load the page on a link click. All VM's will freeze or lock up for ~5 seconds while also reporting 100% primary disk utilization. It could be something as simple as opening an application. The VM issue happens frequently while using it. Another small problem although not the primary focus here, when I pass through a sata device to the VM, the os starts bugging out and the error log shows "reset to device raidport0", these errors do not show up unless a drive is physically passed through. I have resorted to passing through a USB sata adapter which works fine but has speed limitations. Plex seems to work fine, but based on the capability of the server, that's not surprising as it would be able to buffer well ahead of a ~5 second lag spike. What I have tried: Motherboard (x570) has received the latest firmware. Tried Windows and Linux VM's, same issue. I don't think its network related as the pings remain <1ms when the stuttering happens and this should not affect the VM's anyway. Secure boot is off. The latest bios update included the ryzen bios fix for related issues. For the sata issue, I have tried other ports, verified sata port access when other devices are plugged into PCIe or NVME slots. Honestly, the biggest issue is the VM lag. Its very annoying when trying to move files and work to have the entire box lock up for ~5 seconds every 30 seconds or so. Thanks for any input.



.jpg.e0cad16c283650bf2f9a188b00857792.jpg)



