

bonustreats
-
Posts
63 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by bonustreats
-
-
4 hours ago, johnnie.black said:
Replace the disk.
Gotcha. Do read failures always equal disk replacement? Is it safe to assume that any time there are errors in that column on the main screen that the drive is bad?
Thanks very much!
-
18 hours ago, johnnie.black said:
Yes, and they've been happening for a month at least, do you have system notifications enable?
Start by running an extended SMART test on the parity disk.
Here it is, sorry for the delay!
Edit: sorry, uploaded the wrong one.
-
6 minutes ago, johnnie.black said:
Yes, and they've been happening for a month at least, do you have system notifications enable?
Start by running an extended SMART test on the parity disk.
I don't think I have them enabled; is this the correct way to enable them?: https://wiki.lime-technology.com/Configuration_Tutorial#Install_UnMENU_for_Screen_and_Email_Notifications
Extended SMART test is currently running, but I think it said to allow 2 hours per TB. I can just download the results and paste them here, correct?
Thanks for responding!
-
2 minutes ago, FreeMan said:
As I understand it, those are read errors on the disk itself, not parity errors - the errors just happen to be reading the parity disk.
HOWEVER - wait until one of the experts peruses the diagnostics file and chimes in with a more authoritative answer before doing anything. In the mean time, I would suggest that you suspend any write activity to your array. If you're simply streaming media, you should be OK until then.
Gotcha, I was guessing/hoping it's something along those lines. Write activity is suspended.
Thanks!
-
Hi Everyone,
Setup: 1x4TB WD Red (parity), 2x2TB WD Green, 2x2TB WD Red, 64 GB SSD Cache, 2GB Flash.
On the Main tab, under the "Array Devices," unRAID is saying that there are 239,435 errors for the parity disk. However, under the Parity History, the last check completed with 0 errors (run on 14AUG) - please see attached image. Is this something to worry about? I tried searching the forums, but could only really find info about actual parity errors that come up during a check.
Diagnostics are also attached.
Thanks in advance!
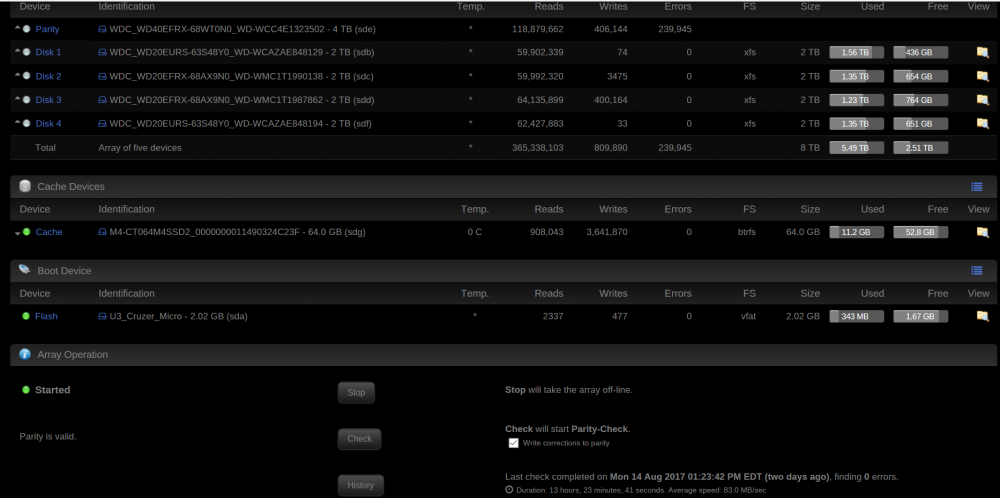
-
Just now, Squid said:
Yes it will
Meowlrighty, here they are - thanks for the quick reply!
-
On 2/25/2017 at 10:09 PM, Squid said:
I've thought about trying to detect what causes the call trace, and then report that as the issue. Unfortunately it's not quite as easy as it might seem since there is no specific number of lines before the trace that states what caused it. IE: some traces have why 3 lines before, others 5-6 lines, etc.
But, I think that if I find IRQ nobody cared within say 10 lines that should suffice....
I got an update to FCP, and ran a rescan - it's now showing the irq 16: nobody cared in the GUI, and it's telling me to post my diagnostics. Will posting the diagnostics now provide any new information compared to the one from Saturday? If so, I'll gladly post them.
I haven't seen any particular issues of note; maybe some transfer speed reduction in some cases, but that might be related to the hard drive that's being used for that copy.
-
On 2/21/2017 at 8:08 PM, John_M said:
6.3.2 has a different kernel so maybe that made the difference.
I guess it hasn't, because it is now back again; same "irqpoll nobody cared" error.
The question now is: is this a serious problem or just some kind of background process that's not going to hurt anything?
-
On 2/2/2017 at 7:31 PM, John_M said:
Good luck with the new motherboard. I wouldn't bother marking the thread - it wasn't a very satisfactory conclusion so no point in raising other people's hopes if they're searching for help with a similar issue.
It looks like other people are running into the same issue that I was (call trace errors, at least), and unfortunately, I am again.
I got a new (to me) MB, processor, and RAM from a friend of mine early last week. Swapped everything over, and it booted right up, I couldn't quite believe how easy everything was. I went through and updated all my plug-ins, as well as went from 6.2.4 to 6.3.1. I ran into a bit of a snag trying to upgrade to 6.3.2, but figured it wasn't a big deal and would upgrade later. Parity check ran; everything seemed great again. Unfortunately, the same call trace error popped up in Fix Common Problems again. I ran the diagnostics to post this yesterday, but it seemed like the forum was down or something, so they're here now. I didn't do a windiff or anything, but it looks like the exact same error that came up before.
I was able to upgrade to 6.3.2 and (so far) the issue hasn't resurfaced, so I'm not sure how useful the diagnostics are. However, that makes me wonder how the heck the same error could crop up with completely different hardware. Could it possibly be my flash drive?
-
Yes, that's correct. Everything about your array is stored on the boot flash.
I hadn't heard that little gem about jumping too many BIOS versions. That really stinks. I've never owned an Intel motherboard and I wouldn't buy one, knowing that. I like Asus and Gigabyte, personally.
I'm sorry this has become such a pain for you.
Ha - I wouldn't ever again either, now. That thread said they got out of the mobo game in 2013, so hopefully you CAN'T in the future

I've heard mixed things about Gigabyte, but (so far) no complaints about Asus, so I'll probably look into a replacement Asus board.
Thanks for the support - it's pretty aggravating when stupid things like this crop up.
Should I mark this thread as "Solved"? Or maybe "Closed" or something?
Thanks everyone for your help and input!
-
Just to double check: the unRAID OS is agnostic to the hardware (for the most part), right? If I switch the hardware (mobo, processor, RAM, etc), unRAID won't even notice, as long as it's booting into the same flash drive/hard drive configuration as before, correct?
-
Well, I tried the cable...no dice.
Did some more googling, however, and found this thread:
https://communities.intel.com/thread/30813
It basically describes my problem and troubleshooting attempts to a T (my board is DH67CL). It turns out that you can brick your motherboard if you 'jump' too many BIOS update versions. Not sure if this is an Intel-only problem, but I tried to go from version 105 to the newest one, which is 160. I saw NO disclaimers on the Intel website warning about this problem, so if anyone uses Intel boards for their unRAID builds, this would probably be useful information to give to them. Not sure where that should go, though...should I email an admin? I may be able to "unbrick" it by using a next generation (compared to mine) processor, but I don't think I want to buy a processor just for a potential fix, only to find that it doesn't work and now I'm out the money for the processor, too.
I guess the hunt is on for a new motherboard, at least. Unless now is a good time to upgrade other internals...
-
I'm sorry to hear that. It seems you did it right and the update was successful. I hope your theory about the DVI connector is correct. Do you have a graphics card you could try?
Thanks - I borrowed a DVI to VGA cable today, so hopefully that theory can be tested. I do have a video card and can try that next. If that doesn't work, I'll try to google a little bit more, in case there's something I missed. Otherwise, it might be new mobo time.
I'll try the cable and all that jazz later this afternoon and will report back.
-
I'd just update the BIOS for now and restart with the USB stick in the same socket and see how it goes. If it happens again, try the USB stick in a different socket.
Sorry for the delay in reply - work was a little crazy yesterday, so I just got to this today...aaaaand I've run into an issue.
I ran the F7 BIOS update from here: https://downloadmirror.intel.com/22273/eng/BIOS%20Update%20Readme.pdf. I double checked the correct BIOS version and put the .BIO file onto a recently formatted 1GB flash drive. I went through the utility, I got a message saying something like, "BIOS update successful, rebooting machine." Only...nothing came back up, just a black screen with a "cable not plugged in" message. I tried restarting multiple times, did a fair amount of googling, and settled on following Intel's advice (http://www.intel.com/content/www/us/en/support/boards-and-kits/desktop-boards/000005753.html). I tried Option 1, but the computer didn't automatically boot into Maintenance mode; so I tried option 2. Pulled the CMOS battery for ~20 minutes and tried again. Same result - no screens loaded. Then I tried the BIOS recovery option (http://www.intel.com/content/www/us/en/support/boards-and-kits/000005630.html). Still nothing.
The only thing I can think of is that the onboard HDMI is not the default output, and that the onboard DVI is, resulting in no screen image and all kinds of insanity being inflicted upon the motherboard through my multiple 'failed' attempts. Unfortunately, I don't have a DVI-to-HDMI cable to test this theory, even though it sounds weak to me. Why wouldn't the board output to either port? I'll try to borrow a cable tomorrow to test.
Has anyone run into a problem like this? I'm really lost and I'm REALLY worried that I just screwed my board and my server.
Thanks,
Jeff
-
You could try the unBalance plug in. I used it to convert my disks to ZFS.
-
Ah-ha! From system/lsscsi.txt in the diagnostics:
[0:0:0:0] disk SanDisk U3 Cruzer Micro 8.02 /dev/sda /dev/sg0
state=running queue_depth=1 scsi_level=0 type=0 device_blocked=0 timeout=30
dir: /sys/bus/scsi/devices/0:0:0:0 [/sys/devices/pci0000:00/0000:00:1a.0/usb1/1-1/1-1.3/1-1.3:1.0/host0/target0:0:0/0:0:0:0]
That matches the owner of IRQ 16:
Jan 27 20:32:26 Radagast kernel: ehci-pci 0000:00:1a.0: irq 16, io mem 0xfe727000
Jan 27 20:32:26 Radagast kernel: ehci-pci 0000:00:1a.0: USB 2.0 started, EHCI 1.00
So the problem is likely to affect the boot device.
So does that mean that all USB ports are affected or just that particular one? If I switched the unRAID stick to another USB port would the problem go away or is this indicative of problems to come (like if one USB port goes bad, they'll all eventually go bad)?
I couldn't find any of my flash drives to upgrade the BIOS last night, so I'll try to grab one today and update it later this evening. I'll then restart the server and see if the problem comes back again. Should I add any other steps?
-
If you want to try the boot option you can edit your syslinux configuration by going to the Main page of the web GUI and locating the Boot Device section and clicking the word "Flash". That opens a new page dedicated to your boot device. Scroll to the bottom and you'll see the Syslinux Configuration section. The area of interest looks like this:
label unRAID OS menu default kernel /bzimage append initrd=/bzroot
Edit it to look like this:
label unRAID OS menu default kernel /bzimage append irqpoll initrd=/bzroot
and click the Apply button. It will take effect when you reboot. I can't say it will fix it - it might even make things worse - so try the BIOS update first.
Thanks for the info! I'll try the BIOS update tonight or tomorrow. I don't really have experience with unRAID RCs and a little leery about RC software in general, so maybe that'll be a last ditch effort.
If the BIOS doesn't fix it, I'll try the irqpoll option. Speaking of fixing, is this a persistent error (once it happens it 'stays on' or can it occur at any time? Would a server restart clear it from unRAID?
-
Computers are very effective air cleaners.Do it in a non-living area of the house (or outside) as you will be astonished at the amount of dirt and dust that can accumulate there.

You don't even want to touch the inside of a tobacco smokers computer.

I try to clean my hardware 2x a year, once in spring, once in fall because I have two things keeping my apartment dust filled: forced air and a cat. I do that ever since a friend of mine gave me some of his old hardware (which I used to make my first unRAID build) and it was pretty freaking gross (please see attached pic). I can't even imagine a smoker's machine - yuck.


-
Rob is way better than me at interpreting these things but I might be able to shed a little light. The trace was called because IRQ 16 was ignored for some reason.
Jan 29 11:24:56 Radagast kernel: irq 16: nobody cared (try booting with the "irqpoll" option)
Jan 29 11:24:56 Radagast kernel: CPU: 0 PID: 10784 Comm: smbd Not tainted 4.4.30-unRAID #2
Jan 29 11:24:56 Radagast kernel: Hardware name: /DH67GD, BIOS BLH6710H.86A.0105.2011.0301.1654 03/01/2011
Jan 29 11:24:56 Radagast kernel: 0000000000000000 ffff88021fa03e70 ffffffff8136f79f ffff8800cc873600
Jan 29 11:24:56 Radagast kernel: 0000000000000000 ffff88021fa03e98 ffffffff8107f8ce ffff8800cc873600
Jan 29 11:24:56 Radagast kernel: 0000000000000000 0000000000000010 ffff88021fa03ed0 ffffffff8107fb9b
Jan 29 11:24:56 Radagast kernel: Call Trace:
Jan 29 11:24:56 Radagast kernel: <IRQ> [<ffffffff8136f79f>] dump_stack+0x61/0x7e
Jan 29 11:24:56 Radagast kernel: [<ffffffff8107f8ce>] __report_bad_irq+0x2b/0xb4
IRQ 16 is used by a USB 2 controller:
Jan 27 20:32:26 Radagast kernel: ehci-pci 0000:00:1a.0: irq 16, io mem 0xfe727000
Jan 27 20:32:26 Radagast kernel: ehci-pci 0000:00:1a.0: USB 2.0 started, EHCI 1.00
This is where I struggle, I confess, trying to link the controller via a hub to a specific device. So I can't say what the device is. An obvious candidate would be your USB boot device, but I just can't say with any certainty. Maybe someone else can help here.
One thing I do notice is that your BIOS is dated 2011 so it might be worth looking to see if an update is available. Failing that, maybe try the "irqpoll" boot option that's suggested. I'm not sure why you think your CPU might be overheating. I can find no evidence of that.
Thanks for looking!
Do you mean that the boot device itself is potentially bad or the port to which it's attached? I just looked and there is a BIOS update from 2012, so I can try to apply that when I get home later today.
I tried to look up what irqpoll is, and a lot of it goes over my head (sorry); however, it seems like when this is thrown, it indicates potential hardware failure. Not sure which component, of course, haha.
In another thread (https://lime-technology.com/forum/index.php?topic=35590.0), they said that the problem was CPU overheating. I didn't see any evidence when I looked through the logs, but figured it might be something good to do anyway and to reduce the number of potential variables.
I'm pretty woefully ignorant on log perusal, so if you don't mind me asking, what do you look for when going through a log?
-
Figured as much - just didn't want to spam all my stuff, if this was some common error that I had missed.
Thanks!
-
Hi Everyone,
Current unRAID setup:
unRAID v6.2.4 - stable
Mobo: Intel BOXDH67CL LGA 1155 Intel H67
CPU: Intel Core i3-2105
RAM: Can't find the receipt at the moment, but I'm pretty sure it's 8GB Kingston (non-ECC)
HDDs: 2xWD20EFRX, 2xWD20EURS, 1xWE40EFRX (parity)
SSD: Crucial M4 64GB (cache)
I was updating plugins tonight and went to Fix Common Problems, ran the scan, and the message said: "Your server has issued one or more call traces. This could be caused by a Kernel Issue, Bad Memory, etc. You should post your diagnostics and ask for assistance on the unRaid forums."
I briefly looked through the forum, and ran the diagnostics. Based on the forum searches, I looked for keywords like: "hot" "throttle" "trace" and "err/error" and they all came back pretty empty. I will probably reapply thermal paste to the cpu later this week, but after that and a memtest, is there something that I should try? I'd be glad to post the diagnostics, if needed - I just don't know what to look for.
Beyond that, do you think it's safe to have it on? I don't want to overheat anything or cause any irreparable damage if I can help it.
Also, I've had a few "Plex server is unavailable" from remote viewers in the last few days - any chance they're related?
Thanks very much for your help and time!
Jeff
-
Never mind! Did it and everything's working - thanks so much, I really appreciate it!
Jeff
-
Gotcha - yep, I'm an idiot. Sorry I missed that.
Going forward, delete docker .img file and then reinstall using Community Apps (which I did not use before)? If so, I'll try to tackle that this weekend.
Thanks for the quick reply!
-
Hi Everyone,
I went through the noob docker setup guide and currently PMS seems to be running just fine. Yesterday, I saw an "update ready" under the 'Version' in the docker tab (please see attachment #1). When I click on it, it asks "Are you SURE you want to update" and I respond in the affirmative. It then proceeds to download and start extracting things, then it comes up with an error (please see attachment #2). I looked through and searched some of the forums, but didn't happen upon anything that helped. I'm using the "limetech' version of the docker, not the needo version.
Steps taken to try to fix:
1. Click icon, then Stop, then start PMS - no change
2. Click icon, then restart PMS - no change
3. Click icon, then update - no change
4. Reboot server and tried steps 1-3 - no change
Any help is most appreciated! I'm still noob-level, and I apologize if there was a fix that I overlooked. Thanks for your time!








Parity "Errors" - SOLVED
in General Support
Posted
Yeah, I think I'd be leery about trying a preclear again regardless - seems like you're just begging for trouble. New one should be here tomorrow. Thanks very much for your time and responses! I'll mark this thread as "solved."