




HawkZ
Members
-
Joined
-
Last visited
Everything posted by HawkZ
-
Wanted to update here. I've been too tied up with work to dig into this too much but over the past (many) months have tinkered with various fruit settings to no avail, not able to find the combination that would both keep fast browsing from Macs yet also not have my backup from my PC (Crashplan) have me routinely hit the open file limit on my Unraid box, requiring me to kill my smb session to regain access to the file shares. It's been quite a painful run, but my attention was elsewhere. Fast forward to this past week, when I upgraded from 6.11.5 to 6.12.4-rc19 on a whim before I dug back into this again. To my amazement, post upgrade I have yet to be locked out for open files, even with Crashplan running regular backups. I don't have notes showing the old fruit settings to compare to but I am guessing something changed there, and/or this was a samba bug that an upgraded version fixed? I am not seeing anything else in the changelogs to really indicate anything that would affect this. Does anyone have any ideas as to what was the culprit/fix?
-
@JorgeB You are exactly right. I was holding off on making any determinations pending further watching, but was just coming here to reply when I saw your response. So far, have not had the runaway open files issue recur. Have initiated several manual backup runs since the change was implemented to try to trigger it and still no instances of issue. This is really looking like the culprit. Thank you!!! Will keep monitoring but expecting this to be resolved. I do have Mac machines in the house, and we have one machine (which I probably need to reload) that has seemed to have some network share connection issues/delays since the change, but my wife (primary Mac user) has not reported issues on her system yet. It appears from the description this setting may be necessary for being a Time Machine repository (not currently used) as well as more responsive Finder browsing. I may have to dig into some of these vfs_fruit settings if leaving this whole setting is not an option.
-
This was enabled. I flipped this off and will monitor. Thank you!
-
CrashPlan backs up files when changed. Runs continuously throughout the day. For local drives on a system it is supposed to trigger a backup on change. For backing up remote volumes it scans it periodically throughout the day. When it does that it inspects each file and does a size/date comparison to the last backed up version to determine if it has changed and needs to be backed up for a change. I don't manually initiate a backup, but after it decides to scan it again, the SMB open files start building up until we hit the limit. I do have over 65535 files, but have no idea why the OpenFiles plugin shows 2 open entries per file. Watching it closer it does appear that files I open through other means only show 1 entry open and clear after I close the file. Items opened through CrashPlan stay open, despite me killing the CrashPlan program/service. I did another test and if I reach the max SMB file limit and reboot the client computer, it does clear the SMB max open files condition (expectedly - but wanted to confirm that data point). Having narrowed this to files touched by CrashPlan I'm a bit stumped as to why this was never a problem with my Drobo but is with Unraid. No response from CrashPlan support yet but given this worked before I doubt they will have much to say about a different result on Unraid which they don't officially support. Really appreciate your assistance here and any further ideas you may have, but other than the knowledge that this worked fine with the Drobo (which was perhaps masking the issue somehow), everything here now has me leaning towards this being a CrashPlan application issue not releasing files properly.
-
Back to hitting the limit again unfortunately. Here are updated diags. tc-diagnostics-20221206-2314.zip
-
Right, I saw this in the logs as well. This was being generated from a VPN docker container I was tinkering with but wasn't working. I have regenerated the network.cfg file and switched docker to ipvlan instead of macvlan. In addition, I've turned off all Docker containers other than MariaDB which is slated to be in use soon. I am glad to wipe this one too as a troubleshooting measure though if you feel it is related. Just fired up CrashPlan again and will post back another diagnostic if/when it hits the limit unless you have additional input in the meantime. Thank you!
-
Here you go. tc-diagnostics-20221206-1026.zip
-
Well I am approaching it from both sides here and have a ticket open with CrashPlan as well in case something changed recently with an update, but I don't suspect it did (nor can I find any config settings surrounding closing open files). It runs a periodic check for if a file has changed and backs it up in a continual fashion. This is the first time I've had any issues with running into the limit of SMB open files or had visibility into what was being left open, but the configuration of the backup has not changed from when I did this against a Drobo NAS. To the PC/backup software it just sees the drive as mapped drive letters. The difference here is just that the shares are now sitting on Unraid vs the Drobo which is why my primary suspicion is that this is on the Unraid side. I am open to it being being either component here, just trying to narrow this down. Also looking at anything on the Windows pc side that has to do with SMB session timeouts. FWIW, I killed the CrashPlan process on the PC and the SMB open file count did not clear until I killed the smbd process in Open Files. Probably let it sit for about 30 mins as a test.
-
@dlandon Why are multiple open files being created per-touch/read and never being released? That seems to be the root of the issue:

-
@dlandon For whatever reason, this issue has returned. Have upped the open file limit to 65535 and am hitting this as well. Attempts to push the limit higher than this have not been successful. Since my prior NAS (Drobo) did not have this issue I am back to my original premise that Unraid is not closing opened SMB files properly. The OpenFiles plugin is showing 2 instances of each file touched held "open" and the list sits there and does not shrink over time, just gets bigger. What are the next steps in troubleshooting here?
-
@dlandon Thank you very much for your assistance here. I installed the User Scripts plugin and set this to run at startup of the array. Since doing this I have not been able to reproduce the issue, so I suspect it is resolved at this point. I have no settings to adjust on CrashPlan to control the number of files it touches at once or it's methods so either the initial backup of the re-introduced files on the new Unraid server (really should not be "new" backup since everything was in the same folder structure/drive letter - however file ACLs were undoubtedly slightly different) was generating a lot of file touches and the multiple stops/restarts when it hit the maximum have let it finally finish, or else the new maximum limit is raised to the point that it allows it to do what it needed to do. Not knowing if I have a unique case here or not, or if there are negative performance aspects to this setting, I'd certainly consider the increased soft limit to be in consideration for adding in as a default in a future update to avoid this issue for other users. Thanks again!
-
Thanks for the reply! It looks like I probably need to add the following to the /etc/security/limits.conf * soft nofile 40960 However when adding that it does not seem to take effect after restarting samba. After rebooting the entire Unraid server, the setting in limits.conf does not persist. How can I apply this soft limit on all users either to test or to make persistent?
-
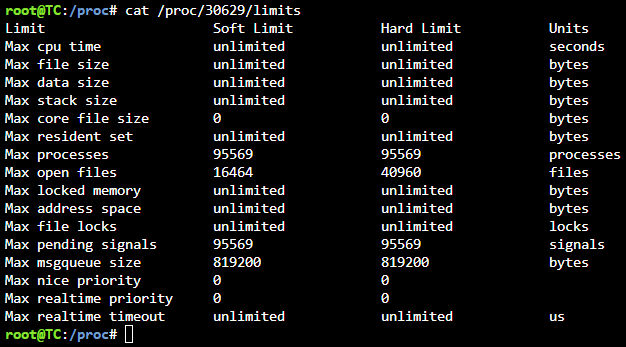
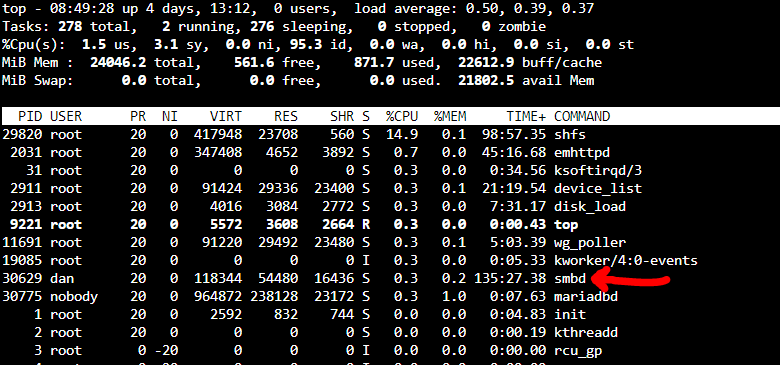
Ok - finding a bit more. While the above limits would seem where they are set, these are the limits on the running smbd process that are maxing out. Note the "Max open files" of 16464 which matches where it is capping out. However, you'll notice the smbd process is not running under root, which is where I gathered all the current user limit data before, so this process running under user level is getting a DIFFERENT set of limits to it: So, where are these set? Also, of note, found this, but while this fixed the issue, "kernel change notify = no" seems like this would leave some gaps (potentially requiring a restart of samba) to let anyone see any file changes not initiated through samba access: https://www.truenas.com/community/threads/kernel-change-notify-yes.45379/
-
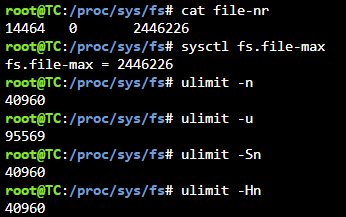
Per some steps in this article: http://woshub.com/too-many-open-files-error-linux/ it does not appear that the limit at 16424 is from any of these...
-
This thread is over 4.5 years old and issue still looks like it has not been addressed. Maybe someone listening can add additional instruction to the wiki or the downloader page for the USB Creator, considering the wiki now tells windows users to just use that. I just created a new USB drive as well and had this issue. Had to perform manual steps as others in this video:
-
Confirming that the smbd[....] synthetic_pathref: opening [....../........] failed messages have returned when copying files to Unraid after removing "logging = 0" from SMB Extras

-
Sorry - I'm new here! Found how to do that and have it attached here. While reviewing something else potentially relevant came to mind. During my initial setup and loading of my data into Unraid I had the following issue where every file written to the array genereated an entry (at that point I was not backing it up yet over SMB): And from recommendations here entered the following in SMB Extras under Settings/SMB: I am going to disable this now as this may be masking anything helpful from the logs - although ironically the logs do show all the smbd entries (like the title of this post). I can let this run a while to see if anything else pops up in the logs.

-
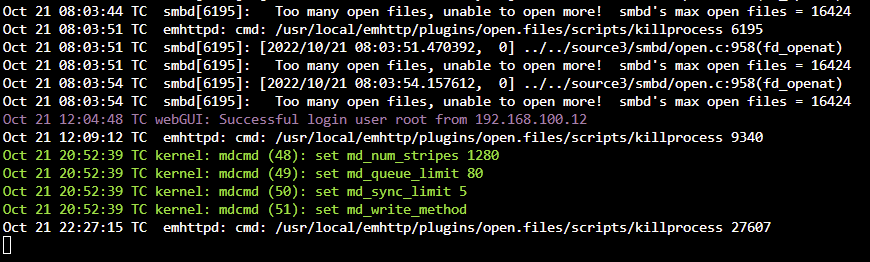
To follow up - interestingly not getting the log entries any more, but I am unable to access the shares again: Here are the logs, and me killing the process again just now from within the Open Files plugin to restore access. Note current time (local) is 22:30 as of this writing:

-
Hi - having an issue where I'm periodically losing connection to Unraid and at this point I believe I believe I have it tracked down to my backup software. I run a backup of the network volumes on Unraid from another PC using CrashPlan and after 4-6 hours it reaches the max file limit. The title and below message is what I see in the log viewer: smbd[6195]: Too many open files, unable to open more! smbd's max open files = 16424 I installed Open Files and was able to catch what was going on, unmapping a network drive from the PC doing the backup stops the buildup of open files. Below is an example of where I have not quite yet hit the limit but will be there soon (note, log was from this morning, screenshot from this evening, array stopped/started since then): I do find it curious as to why the backup software is opening multiple sessions/instances of each file but for clarity only one instance of the files, but am not here really to discuss CrashPlan's method. I suspect samba is keeping old open files open after they are no longer in use and multiple touches open new instances of open files. I believe I have two issues - samba not releasing open files fast enough after no longer being in use, and also potentially needing to increase the open files limit. The one thread that seems to be related to this that I can find is over 10 years old and all indications are that this was possibly long since fixed. Not finding anything current enough to give me comfort modifying any config files or truly identifying this as the issue. Had zero issues with this on my Drobo (RIP) previously. The fix currently is to stop/start the array, which I later learned was effectively restarting samba. Using the KILL button in the Open Files plugin also restores access to the shares. Would love any help or insight you could provide. Thank you!

-
Great read and explains this very well. In this case the drive with issues was my parity drive so would have been touched at any write (which I really wasn't doing unless the system was doing anything in the background). Thank you!
-
Rather than just to a particular disk, I would assume this would be for any write to the array (which necessitates a parity calculation and hence a read from all disks), correct?
-
I'm very new to Unraid and have a trial running on a test system. Previously while testing with some old drives, I live-swapped some SATA cables around on drives as I was adding an SSD for a cache drive and found it odd that the Unraid web interface didn't freak out or show drives offline, even refreshing the "Main" tab. It was some time later (30ish minutes to a couple hours), all these notifications rolled in about parity errors, read errors, etc. Not sure why I didn't post/ask about it then. Today I swapped in my production drives to get my array up and going for good (purchase pending once my new USB drive is delivered) and again, did it while the system was running. I didn't have the luxury of time to wait for it to start erroring, but sure enough, it made it look like everything was fine. I had to stop/start the array to get it to realize the drives weren't there. I realize what I was doing is far from the norm, but it does beg the question of how "real time" alerting of future disk failure or error reporting will be, and whether the delay will affect proper parity calculation. Is this normal? I wasn't USING the array other than an unconfigured but running mariadb docker) so with no writes/reads maybe it had not had the opportunity to realize the disks were gone (seems unlikely as the OS should have seen the device removal)? Appreciate any input you may have. Thanks!










