




u0126
Members
-
Joined
Everything posted by u0126
-
same issue here. cyberpower model: CP1500PFCLCDa Mar 15 22:31:07 unraid usbhid-ups[4697]: nut_libusb_get_report: Input/Output Error Mar 15 22:31:09 unraid usbhid-ups[4697]: nut_libusb_get_report: Input/Output Error Mar 15 22:31:11 unraid usbhid-ups[4697]: nut_libusb_get_string: Input/Output Error Mar 15 22:31:11 unraid usbhid-ups[4697]: nut_libusb_get_string: Pipe error Mar 15 22:31:43 unraid usbhid-ups[4697]: nut_libusb_get_report: Input/Output Error
-
I believe it already was, but this last go around I did this anyway (thinking maybe it'd be more thorough), I also switched BMC off on the motherboard, and a handful of other settings. We will see what happens next time I have to reboot (or at least cold off/on, I think reboots seemed to work fine) HW transcoding is working, I am assuming due to the fact I did have a monitor plugged in on boot.
-
I had the same issue with HW encoding not working and realized i915 wasn't even modprobe'd - likely because I was using the VGA port. so I've switched to the HDMI port (for the moment, and will have to get a spacer or maybe the PiKVM will keep it active properly) and am just waiting to see the next transcoding happen and see if it's using hardware or not. I have similar issues with this motherboard... I got it because it supports ECC (as a bonus), a processor with QSV and thought the IPMI stuff would be nice to have. I have a PiKVM, and the IPMI seems mostly useless anyway... it doesn't seem to be booting my system reliably. Often times after BIOS post, and then the "importing firmware configuration settings from odata server" will show up and then it'll go to a black screen... and never fully boot. Other times, it will boot fully. I can't figure out what it's being stuck on. I also tried to optimize power usage using autotweak and didn't do a ton of stuff but it wound up being unable to boot and I had to remove the CMOS battery and do a full reset. There's a lot of options and variables in the mix here. It's driving me crazy. I've tried disabling a bunch of things, I gave the IPMI a static IP and sometimes it's online and sometimes it's not. It just seems like this thing has a lot of weird crap going on.
-
Disk shares are really night and day. That shfs overhead is a killer. Seems like my system gets bogged down possibly with I/O having to pass through the shfs layer and that locks things up from the SMB server reading from it... because right now mounting a disk share directly is like it's directly attached to my Windows system. At least for now so I don't have to worry about data corruption weird stuff I'm only going to do activities inside of the specific disk share itself. Not move things in and out of it. It'll let me at least do a lot of cleanup on the specific disk, stuff that was sometimes super painful when trying to go through the user share.
-
I've got some fun things I've noticed (without any in-depth research) but simple anecdota - if things are "clean" - I haven't done anything to lock up the samba connection, I can get 100-200MB/sec between my Windows system and Unraid (2.5G onboard ethernet on both connected to the same 2.5G switch) and that's great. What sucks is when samba locks up (and seems to happen frequently enough to go to Google once again) and everything stalls out for what feels like an eternity. Just minutes ago I tried to move one folder to another inside of the same share (/mnt/user/foo) and same mapped drive and all, not even that much data (~5 gig) and my entire Windows explorer process wound up locking up for well over 5 minutes. It never timed out or gave up, it just sat there. I can't figure out a discernable pattern so far, other than shfs processes do seem to be busier at the moment (I am doing some other stuff on the array, usually, but nothing that should be completely freezing up simple samba operations)
-
Yeah, I had set it as ready to restore to. what I'm still curious about is if parity is restoring things back as they were isn't it restoring/emulating a corrupted xfs filesystem? If it's sector-based?
-
It is rebuilding while the array is active, out of curiosity I looked at /mnt/disk9 and seeing new downloads are hitting that disk. I'm not really concerned about performance (it's still performing well enough) and I'm on vacation not in any hurry for that to finish... it's not at top speed but seems at least 50% last I checked. Previous post seemed shocked that new stuff is being sent to that disk, but I'm just letting unraid do its thing. I'd expect if that was "crazy" it'd leave the disk out of the array while it did that. I'm just confused what it might be emulating (or maybe it's because I'm conceptually thinking it's emulating a "disk", but really it's just emulating "missing sectors" overall?) - when it says a disk is being emulated does it not mean the disk but rather simply the "missing data" (sectors) are being filled in?
-
How would that work? As of right now /mnt/disk9 is already putting in fresh data. Is that both being rebuilt and able to function at the same time, or is there some version of disk9 that's being rebuilt? Struggling to see how it can rebuild something at the same time it's adding to it. Stopping the rebuild, putting into maintenance, then xfs_repair on dm8? If /mnt/disk9 is mounted/available right now but is being emulated (and emulating the xfs corruption) how is it available and adding new data to it already? Shouldn't it still be corrupt?
-
Funny enough Unraid is still saying it's emulating the contents of disk9. which is just the *current state* of that drive, right? The drive 42.5% being rebuilt from parity? It's still confusing to me what it's restoring and how it knows it's wrong, if parity can tell, can't I simply xfs_repair what's still there? What exactly is it restoring?
-
yeah, I understand all that. Like I said most could be re downloaded I just don't know what I lost. so building a file list (unencrypted) is at least the most basic thing. I am shipping backups off (as fast as I can) but it's too late for that disk issue sadly. Literally was doing it this weekend while I was bored on vacation.
-
If the rebuild to this disk is 42.5% completed does it make sense to stop it and see if there's any way to recover/find anything on it at this point?
-
ehh. Simply using a different fuel type feels a little bit of a stretch here. Mostly, I misunderstood exactly how parity applied. I did understand destroying the disk would be but I also did not have time to wait for some sort of "recovery" process that I wasn't sure entailed, and still again, thought parity worked like I thought it did from using other "parity" tools 😛 Ultimately I skimmed it and did not fully comprehend it; I'm used to so many other systems (parity tools, ZFS, etc, etc) and did not understand the Unraid application of parity which ultimately can be summed up as above "it comes in only when a disk is missing/failed/unavailable and will emulate the data" and that is it. Also I learned that dual parity doesn't actually provide 2x the amount of parity (which I know other people have thought too), but rather a second copy of a single disk parity using a different mechanism (so that up to 2 disks can be emulated when unavailable) I'll take a look at the script. Even a find -type f is all I'd need in the end. Most I could redownload but I need to know what to redownload. I'm over 50% capacity on ~300TB on Unraid alone, with a bunch of USB drives I need to move into Unraid + possibly shuck the drives and add to the array. Glad this came up _before_ that then, ultimately. I'm sorry for raging, I'm just super annoyed at how quick this came up and ultimately it's just my fault. This was one reason it took a while to decide on Unraid vs. SnapRAID/MergerFS/etc. vs. ZFS, was "do I want to use someone else's management style for my system" but Unraid seemed "hands off" enough... I actually tried SnapRAID/Merger before this and switched off of it in favor of some newer hardware and Unraid as it seemed like it had enough community/support/etc but I misunderstood how some of the internals worked. If I didn't have to leave I might have spent more time exploring options instead of applying my usual ZFS "replace it in place for now" approach, thinking parity provided something else. It would have been nice if there was something that popped up and ran xfs_repair for me or notified me. I didn't fully understand what disabled disk or whatever was and Googled quick and saw some "here's how to fix it" with only a couple of them mentioning gotchas/losing data (but again I thought that applied only if parity hadn't been built yet)
-
Well sadly that's how I took it, because I thought parity acted like I'm used to with par2 and such. A safeguard statement that if parity wasn't available you'd lose data, something like that. So there we go. What a pisser. All this because I moved things into another room before I left for a trip and wanted to make sure shit was stable before I left for weeks without the ability to physically do anything with it. I didn't see the xfs_repair until much later and I'm used to ZFS failing a disk and being able to put it back right in place. I understand ZFS raidz is actual RAID and this isn't, but as stated, I thought parity worked like I've experienced it with other apps (and maybe it does under the hood somehow, but not in the same portable fashion) The real shitty thing is I don't even know what was on that disk. If I even had a list of files that would have been something. I'm going to setup a daily job to make an entire file list of my system now so worst case any further stuff I at least know what was lost.
-
If the underlying disk goes corrupt, the parity data about the disk is corrupt, right? So it can't emulate the good data? Bit confused when it jumps in. If a disk goes corrupt, Unraid unmounts it and parity patches the missing data, yes?
-
yeah, that's just standard "if you format a disk it will delete all data" - not a very important "hey if this was previously a data disk try a repair first!" at that point. Using parity with tools such as par2 it's able to see it figure out that files don't match it's checksums / the parity it originally built and rebuild. That's what I "assumed" it did. Here's the issue I have with your statement. Do you use mysql? Do you know what it does end to end under the hood? No. Do you drive a car? Can you explain everything it does to go from point A to B? No. (And don't be snarky with "actually I do" you can get the idea of the examples) - the selling point of Unraid is its relative simplicity. Even though I know it's not RAID I had to apparently feel the pain of what parity is and isn't as it applies to unraid to learn that. Which is awesome. Parity to me was amazing when I saw how par2 worked; in this case I'm still at a loss of what it really provides - an "emulation layer" for a missing disk basically and no "knowledge" of the data - just bits - which is what data is, but apparently it somehow created parity of some disk that failed/was incorrect just minutes prior. It was fine until I turned it off and turned it back on a couple minutes later and it came up as disk uncountable or whatever.
-
I didn't have the luxury of time to go through the logs as I was leaving for 3 weeks, I wanted to make sure the system was going to be stable. I mistakenly thought parity worked like par2, where it had knowledge of what was corrupt and would repair. Maybe it does that exact thing but still wondering why it didn't in this case. Apparently the parity on unraid is only good if nothing is corrupt and won't detect/fix corruption (or only does that on a parity "check"?) I just don't understand what the point is. I have 15x 20tb drives - it's a lot of data to have backups immediately available, and it took weeks to get the data centralized so I could begin shipping backups of it.
-
which is sad because I literally was setting up 2-3 different offsite backup mechanisms to begin this weekend. Like I said I don't even have a list of what I lost now. Unraid really needs to make this shit clearer. Detect the corruption and make it more obvious what next steps to do. Also it seems like everyone is confused how parity works and expects that to provide a loose "backup" So you're saying disk9 started corrupting so the parity of that disk was added in as corrupt?
-
I guess maybe you did answer that. Any data on disk9 is gone? What the fuck was the point of parity then? disk9 needing a repair should be the same as disk9 being gone or a failure. Where was the 20tb of data being patched in through parity?
-
So... I would have expected unraid to have given me some sort of visual idea of this. To me it looked simply like it just needed to be replaced. The UI simply showed the disk was unavailable. Not "hey it just simply needs a quick repair!" and even some way to run that. I noticed that xfs_repair myself eventually, but after things were underway. Again mt expectation was I've got two parity drives that were supposedly valid and current. Now as far as parity / data redundancy goes, I tried to read up on it again, it seems like if parity was current (as it should have been) data shouldn't be lost. Essentially it should be like disk9 totally failed and I put in a brand new disk. The fact it happened to be the same disk should be irrelevant. Since it refused to mount it anyway. What I can't seem to get an answer is if my data is gone or it will be restored when rebuild is done. It says that data was being emulated, I don't recall seeing anything there but an entire disk was possibly missing... With parity I waited to be built for something like 7-10 days to be complete. Will data show up or is what I currently see what I'm going to get? Will a rebuild "find" and patch the missing data in?
-
there's actually 3 - 2 I know I did manually, one I don't know if maybe it ran it automatically at some point, because I just learned how to generate it and only ran it once yesterday to see what was in it and today for this. disk9 was the one that failed and I see multiple references in the shares/*.cfg to it, which makes sense as those are where I am seeing holes in data. how does parity work exactly? obviously it's there to recover data, but when/how does that recovery happen? or is it only during the "data is being emulated" stage...? because I don't recall seeing it at that point still.
-
I had waited for over a week I believe it was for that initial parity build to finish... trying to figure out how it actually helps with anything at the moment.
-
the shitty thing is I don't know what I lost exactly. usually at a minimum I build a file list - so I have an inventory. I just had started using this Unraid box as my primary storage mechanism (and actually drained my owner 2 NAS units completely) so if any of that stuff (which was safe for years...) was part of it, moving to Unraid kinda messed up my entire data collection within a week I actually have CrashPlan and was going to re-setup 1 or 2 other "off site" backup options now that things seemed stable - literally this weekend.
-
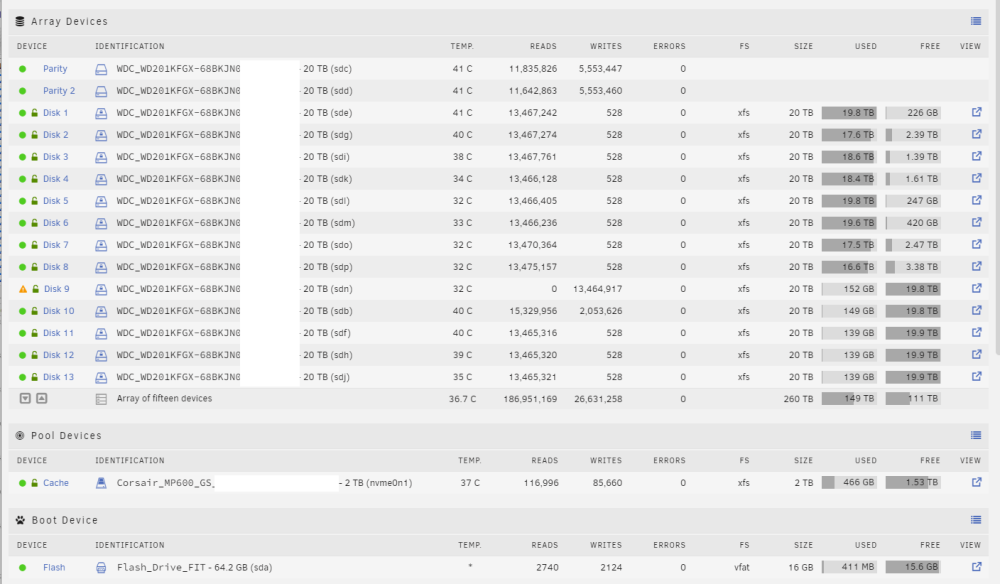
Haven't done anything too crazy. I powered it down (gracefully) to move my system into another room. After powering it up, things seemed fine. I was due for a parity rebuild, it seemed - so I started that process. However, weird shit started to happen and I had to issue "reboot" (not a hard reboot) and when it came back up a couple things I noticed. nginx didn't start - so the unraid UI wasn't available. /etc/nginx/conf.d/servers.cnf didn't exist. So I "touch"'ed the file, then nginx came up. Cool. Also seemed like this brand new (weeks old and was one of the highest rated ones for Unraid) USB boot drive showed it wasn't "cleanly" shut down and recommended fsck. Problem is fsck wouldn't actually fix anything no matter what. Popped it into a Windows system and let it fix it there. No complaints now. Yay? root@unraid:~# fsck /dev/sda1 fsck from util-linux 2.38.1 fsck.fat 4.2 (2021-01-31) There are differences between boot sector and its backup. This is mostly harmless. Differences: (offset:original/backup) 65:01/00 1) Copy original to backup 2) Copy backup to original 3) No action [123?q]? 3 Filesystem has 7830038 clusters but only space for 1957758 FAT entries. root@unraid:~# Also, one of my disks said it was corrupt - "device is disabled" - okay, fine I guess...? It happens. Didn't see any issue beforehand. So I wound up using the recommendation here of essentially replacing it in-place (I don't believe it really has any issues right now) - which would delete the data... I didn't have a spare disk to pop in, but it looked like that was suggested, but not mandatory (I mean, what is the point of having 2 dedicated parity disks...?) Now I'm looking at stuff while the array is back online and I'm clearly missing a lot of random shit. It's a big array; but I had two parity disks in there and had let those build originally. What I don't get is it said that the contents were emulated and I have parity disks but what happened to the data(?) - now I'm in the middle of a data-rebuild back to Disk 9 and I fear that there was no copy of the data properly somewhere to begin with(?) The disk was basically full. Any thoughts on this? Will data wind up getting repopulated back in somehow after the data rebuild (will it pull/be reconstructed from the parity disks? when do the parity disks "step in" to provide the data in any of this process?)
-
Looks like in 6.12 it'll be fixed in core anyway?
-
yeah I didn't have anything obvious, all rsyncs were killed, didn't see any processes still open, no dockers, no VMs, only SSH was me as root directly into /root. it looked like shfs (as I posted later) still had some /mnt/diskX uses that weren't dying down. like some fuse leftover stuff.
