




beachbum
Members
-
Joined
-
Last visited
-
Hello comunity, I need to build a Linux VM but as part of the settings I need to create to LVM disks. A LVM disk size 220GB where the files will reside and also an EFI type disk size 4MB These are the settings on Proxmox however I can’t seem to be able to replicate on unRaid as I see no option for disk type EFI. is there a way to create a template using the following settings ?? See attached picture. Thank you very much
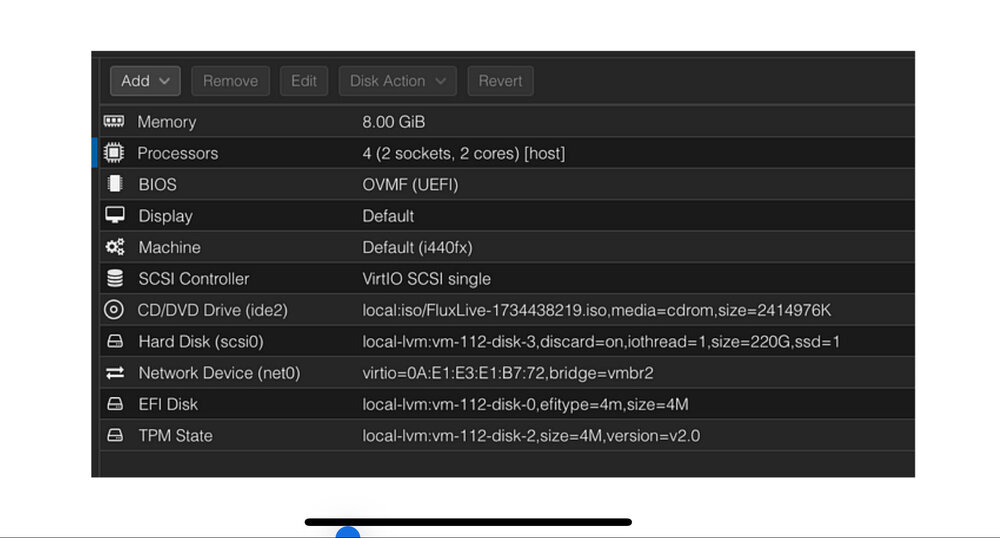
-
UNRAID 6.12.4 / Linuxserver - NEXTCLOUD UNABLE TO UPLOAD FILES Fresh Unraid install. Fresh install of MariaDB and Nextcloud. worked for 2 days. Only 2 users. neither user is now able to upload files for my Nextcloud. not enough space when using the client app. while using the web I get I ether get an unknown error has occurred or error when assembling chunks status code 504. I was able to find a solution which might have applied to me since im using the NGINX proxy manager, however i then switched to try and upload directly to the lan ip address of the nextcloud docker so not using the proxy manager and I still cannot upload hence i believe the error is within nextcloud. My nextcloud share is directly on to the array and it does not use the cache drives. So i clicked on nextcloud - logs: ( logterminal/nexcloud.log ) #3 {main} Exception: Not installed in /app/www/public/lib/base.php:283 Stack trace: #0 /app/www/public/lib/base.php(709): OC::checkInstalled() #1 /app/www/public/lib/base.php(1196): OC::init() #2 /app/www/public/cron.php(43): require_once('...') #3 {main} [migrations] started [migrations] 01-nginx-site-confs-default: skipped [migrations] 02-default-location: skipped [migrations] done usermod: no changes ─────────────────────────────────────── ██╗ ███████╗██╗ ██████╗ ██║ ██╔════╝██║██╔═══██╗ ██║ ███████╗██║██║ ██║ ██║ ╚════██║██║██║ ██║ ███████╗███████║██║╚██████╔╝ ╚══════╝╚══════╝╚═╝ ╚═════╝ Brought to you by linuxserver.io ─────────────────────────────────────── To support LSIO projects visit: https://www.linuxserver.io/donate/ ─────────────────────────────────────── GID/UID ─────────────────────────────────────── User UID: 99 User GID: 100 ─────────────────────────────────────── using keys found in /config/keys System config value memcache.local set to string \OC\Memcache\APCu System config value filelocking.enabled set to boolean true System config value memcache.locking set to string \OC\Memcache\APCu System config value upgrade.disable-web set to boolean true [custom-init] No custom files found, skipping... [ls.io-init] done. I found an error.log file on the nexcloud app folder and came up with this: [18-Nov-2023 17:53:56] NOTICE: fpm is running, pid 417 [18-Nov-2023 17:53:56] NOTICE: ready to handle connections [18-Nov-2023 18:05:05] NOTICE: Terminating ... [18-Nov-2023 18:05:05] NOTICE: exiting, bye-bye! [18-Nov-2023 18:05:34] NOTICE: fpm is running, pid 445 [18-Nov-2023 18:05:34] NOTICE: ready to handle connections [19-Nov-2023 16:25:55] WARNING: [pool www] server reached pm.max_children setting (5), consider raising it [20-Nov-2023 05:57:34] WARNING: [pool www] server reached pm.max_children setting (5), consider raising it [20-Nov-2023 06:05:13] WARNING: [pool www] server reached pm.max_children setting (5), consider raising it i have been googling solutions and i think it points out to not enough resources ?? My server is 16GB of Ram any help is appreciated.
-
Hello everyone, So i set up my first UnRaid server on 6.11.5. That server is running solid for months. my nextcloud and all other apps are in working condition. So i set up my second server. This one is now running on 6.12.4. I have had nothing but problems on this server. couple of says ago a rebuilt the server again after lots of problems with nextcloud, change the USB drive and re-installed my key. Reinstalled Nextcloud and for a couple of days it seems to finally be working. Now i get another error: I am unable to upload files for my Nextcloud. not enough space when using the client app. while using the web I get I ether get an unknown error has occurred or error when assembling chunks status code 504. I was able to find a solution which might have applied to me since im using the NGINX proxy manager, however i then switched to try and upload directly to the lan ip address of the nextcloud docker so not using the proxy manager and I still cannot upload hence i believe the error is within next cloud. My nexcloud share is directly on to the array and it does not use the cache drives. So i clicked on nextcloud - logs but was not able to find anything logged. I found an error.log file on the nexcloud app folder and came up with this: [18-Nov-2023 17:53:56] NOTICE: fpm is running, pid 417 [18-Nov-2023 17:53:56] NOTICE: ready to handle connections [18-Nov-2023 18:05:05] NOTICE: Terminating ... [18-Nov-2023 18:05:05] NOTICE: exiting, bye-bye! [18-Nov-2023 18:05:34] NOTICE: fpm is running, pid 445 [18-Nov-2023 18:05:34] NOTICE: ready to handle connections [19-Nov-2023 16:25:55] WARNING: [pool www] server reached pm.max_children setting (5), consider raising it [20-Nov-2023 05:57:34] WARNING: [pool www] server reached pm.max_children setting (5), consider raising it [20-Nov-2023 06:05:13] WARNING: [pool www] server reached pm.max_children setting (5), consider raising it i have been googling solutions and i think it points out to not enough resources ?? My server is 16GB of Ram any help is appreciated.
-
well, same here !!
-
Unraid 6.12.4 New install, i setup mariadb nextcloud and nginx proxy manager. all from linuxserver ripo. i updated nextcloud and thats when it all went bad. I have since removed all containers. even disabled docker and removed the image. then deleted all associated shares. performed a new install and now i have an error while trying to install Nextcloud. "One or more ports used by this application are already in use by another service or app running on your server. " Only apps I have running are mariaDB and nextcloud. if i had the server next to me i would have just deleted all drives are install usb drive. Im out of ideas on how to reset things so i can start new and get rid of that error message. Can you please help ? Thanks
-
Error after upgrade to: 27.1.3.2 OK new install about a week old. Everything was working. Hit upgrade button under docker. Then got Error message of internal server errors. Tried a few of the fixes found via google, but unable to fix it. deleted the containers for MariaDB and nextcloud. Re-installed and still same error. deleted the containers again, and this time Deleted both the MariaDB and nextcloud. share/folders. so I reinstalled everything. It worked. Created a couple of users. 5 minutes later now a new error: Doctrine exception: failed to connect to the database. (See attached picture) stopped both containers. Restarted. Then it worked again. A minute later same error. BTW: I don’t need to save any data. I just want a fresh install that actually works . Any thoughts ?
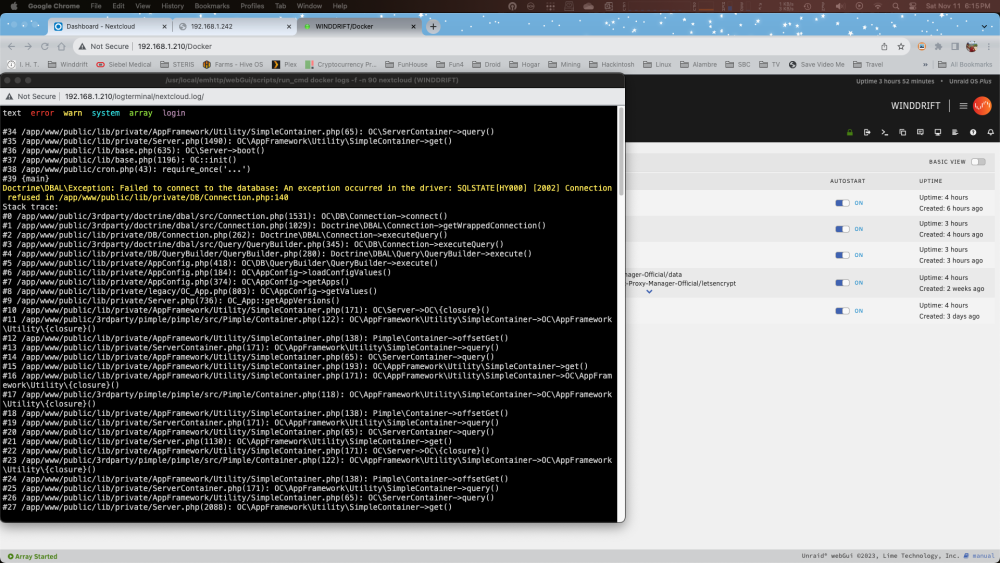
-
After following your instructions I copied back the data after reformatting as a 2 drive pool btrfs. Happy to report the system is now working as expected. Thank you for your help on this issue. Have a great day !! /Users/eli/Desktop/Screenshot last.png

-
Ok, I stopped the array, selected 1 drive only for the pool. Then went to the settings and selected xfs. restarted the array and voila !! the drive mounted and the pool is now working again. I will copy the data off the drive but then: Do i delete the pool and create a new one as a multidrive and the drives get formatted automatically ? or Do i manually format each drive as btrfs and just re-add to the existing pool ? Will the data copy back automatically or do i do it manually ? I want to make sure i do it correctly as this pool holds my appdata, domains, and system folders and i want to avoid any corruption of the files in those folders. Thank you for all your help.
-
after running: xfs_repair -v /dev/nvme0n1p1 Output: Phase 1 - find and verify superblock... - block cache size set to 1519704 entries Phase 2 - using internal log - zero log... zero_log: head block 772597 tail block 772597 - scan filesystem freespace and inode maps... - found root inode chunk Phase 3 - for each AG... - scan and clear agi unlinked lists... - process known inodes and perform inode discovery... - agno = 0 - agno = 1 - agno = 2 - agno = 3 - process newly discovered inodes... Phase 4 - check for duplicate blocks... - setting up duplicate extent list... - check for inodes claiming duplicate blocks... - agno = 1 - agno = 0 - agno = 3 - agno = 2 Phase 5 - rebuild AG headers and trees... - agno = 0 - agno = 1 - agno = 2 - agno = 3 - reset superblock... Phase 6 - check inode connectivity... - resetting contents of realtime bitmap and summary inodes - traversing filesystem ... - agno = 0 - agno = 1 - agno = 2 - agno = 3 - traversal finished ... - moving disconnected inodes to lost+found ... Phase 7 - verify and correct link counts... XFS_REPAIR Summary Wed May 3 15:11:13 2023 Phase Start End Duration Phase 1: 05/03 15:11:13 05/03 15:11:13 Phase 2: 05/03 15:11:13 05/03 15:11:13 Phase 3: 05/03 15:11:13 05/03 15:11:13 Phase 4: 05/03 15:11:13 05/03 15:11:13 Phase 5: 05/03 15:11:13 05/03 15:11:13 Phase 6: 05/03 15:11:13 05/03 15:11:13 Phase 7: 05/03 15:11:13 05/03 15:11:13 Total run time: done ---------- FYI: This is the status under the MAIN tab.

-
OK, btrfs select super -s 1 /dev/nvme0n1p1 That command gave me help screen for the btrfs command showing all options. so i tried: btrfs-select-super -s 1 /dev/nvme0n1p1 (I had already tried this solution from another post) That gave me the following: No valid Btrfs found on /dev/nvme0n1p1 ERROR: open ctree failed Then I typed the second command: btrfs fi show Output: Label: none uuid: 1bd0e1e9-6de2-4ee0-960d-15b56e76552b Total devices 2 FS bytes used 144.00KiB devid 1 size 931.51GiB used 3.03GiB path /dev/sde1 devid 2 size 931.51GiB used 3.03GiB path /dev/sdf1 Label: none uuid: c7ace299-0623-44cf-947d-63136c927b24 Total devices 1 FS bytes used 2.73GiB devid 1 size 20.00GiB used 3.52GiB path /dev/loop2 Label: none uuid: 92d8dabc-0f64-4309-886d-635b8865f2c2 Total devices 1 FS bytes used 412.00KiB devid 1 size 1.00GiB used 126.38MiB path /dev/loop3 Label: none uuid: 64aae5f5-4d68-4f61-87f5-1b788f38e7f7 Total devices 1 FS bytes used 144.00KiB devid 1 size 1.82TiB used 2.02GiB path /dev/nvme1n1p1
-
The original device was: nvme0n1 Then added: nvme1n1 here are the results of btrfs fi show: Label: none uuid: 1bd0e1e9-6de2-4ee0-960d-15b56e76552b Total devices 2 FS bytes used 144.00KiB devid 1 size 931.51GiB used 3.03GiB path /dev/sde1 devid 2 size 931.51GiB used 3.03GiB path /dev/sdf1 Label: none uuid: c7ace299-0623-44cf-947d-63136c927b24 Total devices 1 FS bytes used 2.73GiB devid 1 size 20.00GiB used 3.52GiB path /dev/loop2 Label: none uuid: 92d8dabc-0f64-4309-886d-635b8865f2c2 Total devices 1 FS bytes used 412.00KiB devid 1 size 1.00GiB used 126.38MiB path /dev/loop3 Label: none uuid: 64aae5f5-4d68-4f61-87f5-1b788f38e7f7 Total devices 1 FS bytes used 144.00KiB devid 1 size 1.82TiB used 2.02GiB path /dev/nvme1n1p1 Thanks
-
Literally the first option under Tools. yet took me a while to find it.. lol !! Here is the generated diagnostics file. Thank you. lcars-diagnostics-20230502-1716.zip
-
Hello everyone. have tried a bunch of solutions from other users i found on google, but to no avail. this is my issue. I had my Cache pool running on 1 nvme drive. this is been working fine for weeks. now i have added an additional nvme so that the pool will have 2 drives for redundancy. Both drives are nvme 2TB. same brand. However when i added the second drive this broke my system. Now im getting an error of Unmountable:no pool uuid. Things i tried: Removing the second drive and reverting back to just one drive. same error. cache settings. changing format to auto , then back to btrfs. same error. then tried running the command: btrfs-select-super -s 1 /dev/nvme0n1 but i get error message : No valid Btrfs found on /dev/nvme0n1 after each attempt i rebooted the system but still same error. Note: Following Spaceinvaderone tutorial i created 2 different cache pools. the nvme cache pool is the one with this issue and this is where my "appdata" and "system" shares are located and due to the magic of Unraid my server still running. Any ideas on how to solve this issue ?
-
thank you for your response. as you suggested I replaced the sata cable and started a new pre clear process on just that one drive. I ran a standard smart test that retuned no errors. question, when you say the “extended smart test” it’s expensive… what do you mean by that ? is it posible to cause damage to the drive or just takes too long ? As I read what I wrote I’m thinking maybe you meant “extensive” ? thanks again.
-
Hello Unraid Community, I'm very excited to join this community and as such I'd like to ask for some advice. I've built an UnRaid server of 3 16 TB Seagate "Amazon Refurbished" drives, 2 1TB SSD for cache and 1 256GB Nvme drive. Following instructions from Space Invader in youtube i have run a Pre-clear on my 3 16TB Drives. However at the beginning of the process one of my drives gave out a SMART count of 4 CRC errors, while the other 2 no errors at all. In the end the pre-clear process was completed with "Preclear finished Successfully" message. I panicked and i requested a replacement drive from the seller. I have read some horror stories about these "Amazon drives" so i thought i had gotten a bad drive. While they process the RMA for a replacement drive I have been doing some research and found that CRC points to a "faulty" Sata cable and no so much a faulty drive. My question is, should i just replace the SATA cable and hope to not see the errors again or should i proceed with the replacement drive ? It's a rather a painstaking process to replace the drive due to its location on the server so i rather not replace it if it's not faulty. While i understand that ultimately the decision relies on me, i'm just trying to open a forum to discuss the gravity of a CRC error so that maybe me, and others can learn more about it. I welcome all comments on this issue and thank you in advance for your time... Glad to be a part of this community.



