

bubbaQ
-
Posts
3489 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by bubbaQ
-
-
I run 10GbE on two workstations, each connected directly (i.e. no switch) to one of two 10GbE cards in unRAID.
Both workstations have large NVME and RAID0 SSDs.
My cache in unRAID is three 4TB SSD drives in a btrfs RAID0 array, for a total of 12TB. So in theory, the hardware will support 10GbE speeds. Spinners in unRAID top out at about 200MB/sec.
Xfers to/from the workstations to cache are very fast (but I need to turn off realtime virus scanning on the workstation to get the absolute fastest performance) and they get within 80% of wireline.
Workstation backups go to cache, as well as certain datasets I need to have fast access to are kept only on cache.
For ransomware protection, the entire server is read only except for "incoming" data on cache. Anything I want to copy to the server I copy it to cache first, and then manually log into the server and move it from cache to its ultimate destination on the array.
Cache is rsynced to a 12TB data drive (spinner) in the array periodically, after confirming data on cache is valid..
-
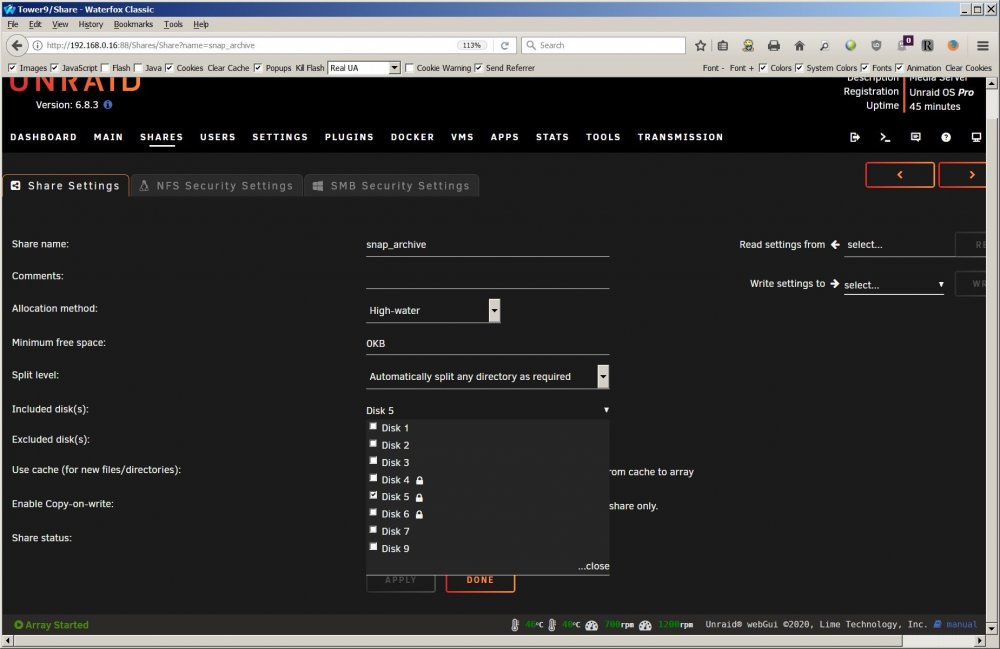
Added some drives (xfs encrypted) and added them in slots 10,11,12. Disk 7 was the highest slot in use. FWIW slots 4, 8, and 9 were empty.
After a reboot, the user shares tab in the GUI did not list any drives above disk 7 as available for inclusion in the share. So I stopped the array, and moved one of those new drives back to an empty lower slot (disk4) and restarted the array, and the shares GUI sees it and created a share on it.
I even tried manually editing one of the share .cfg files as a test to include one of the new drives (disk12) and it would still not see it in the GUI.
I added an unencrypted test drive at disk13 and formatted it, and created some files/directories on it, restarted the array and same problem.
Image and Diagnostics attached.
Suggestions?
-
By "haste" I meant abandoning the project permanently.
I completed my tests and all the hashes all match, so even on files over a TB, there was no corruption.
-
Don't be hasty.... I'm running hashes against them now to compare to backups.
You might just need to use long integers and recompile it.
-
Have you tested it with *large* files? I get overflows with large files. See attached.
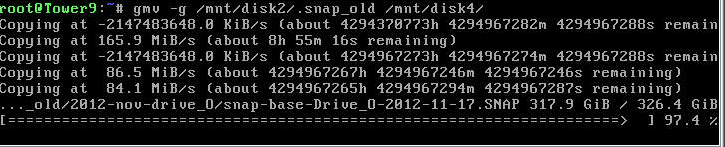
-
39 minutes ago, testdasi said:
+1 what itimpi said.
Same here.
-
8 hours ago, johnnie.black said:
It's not really a bug, it's a feature, though I don't like it either you can turn it off.
How can this NOT be a bug? Both the setting in the GUI and the command line option are broken of you can't set it to always use turbo write.
-
What did you do to get it running?
-
Reverted to Version 6.7.2 and turbo-write seems to be working better. Still some oddness though -- it seems to read for several seconds from the source with no writing to the destination, then stop reading from the source while writing to the destination and reading from the other data disks to reconstruct parity.
-
Had to downgrade back to Version 6.7.2 due to bug in turbo-write not working properly in 6.8.x

-
2 hours ago, johnnie.black said:
The issue here is that since v6.8.x Unraid reverts to read/modify/write mode when activity is detected in multiple array disks, and unfortunatly this can't be turned off, I did ask Tom to only use this if write mode was set to auto, but no dice, it can't be disabled for now, so your writes are constantly going from reconstruct write to r/m/w, hence why parity and the destination disk also have reads, for the r/m/w part, if you downgrade to v6.7.x. you'll see the expected behavior, but speed won't likely be much better since disk4 will be constantly seeking for the data and parity calculation reads.
Is there a thread somewhere that explains this bug?
-
21 minutes ago, johnnie.black said:
No worries, my bad also because I didn't read the entire post carefully, I missed that this was an array to array copy, so not related to what I was talking about.
The issue here is that since v6.8.x Unraid reverts to read/modify/write mode when activity is detected in multiple array disks, and unfortunatly this can't be turned off, I did ask Tom to only use this if write mode was set to auto, but no dice, it can't be disabled for now, so your writes are constantly going from reconstruct write to r/m/w, hence why parity and the destination disk also have reads, for the r/m/w part, if you downgrade to v6.7.x. you'll see the expected behavior, but speed won't likely be much better since disk4 will be constantly seeking for the data and parity calculation reads.
I don't think so. I tried setting write to r/m/w and got very DIFFERENT disk activity... the same that I normally see with r/m/w. Same amount of reads and writes from target and parity, and reads with no writes from source disk... all other disks no activity.
-
You are correct... I corrected the OP to reflect xfs.
My bad.... I was working on some btrfs issues on another server the last few days.... and had googled btrfs issues a mission times.
-
39 minutes ago, johnnie.black said:
I don't have an explanation, but I did observe similar behavior, but only sometimes, usually for a short while, and not in a reproducible way, so I never tried to investigate further, but is likely related to btrfs (or COW in general) since all my servers are also btrfs.
I first stopped and restarted the copy and got the same results. Then I restarted the server, and got the same results.
It's been running for several hours and the results have been the same throughout the copy.
-
Version 6.8.1 with dual parity. Freshly booted.
I'm moving several TB of large (over 500 GB) image files from an old 6TB drive to a new 12TB using DISK shares only. I enabled turbo write (reconstructive write) expecting things to go faster. All data drives are WD Reds with xfs.
I expected to see writes but no (or few) reads for parity 1 and parity 2 and the destination drive, and reads but no (or few) writes to the other data disks. I expect the read rate of the other data disks to be about the same as the write rate to parity and the destination drive.
But I am seeing two odd things:
1) the read rate from the OTHER data disks (about 50MB/s) is only about half the write rate to parity and the destination (about 100 MB/s); and
2) is a significant rate of READS from parity and the destination drive (about half the rate of WRITES to those drives)
Yesterday I wiped an old data drive with 0 so it could be removed from the array (dd to /dev/mdX) with reconstructive write and I got the expected 170 MB/sec to the data drive and parity with no reads, and pure reads at 170MB/sec from the other data drives. Removed it and did a parity check and all was fine.
As a test, I tried turning off reconstructive write, and got 90MB/sec reads and 90MB/sec writes for parity and destination drives.... just as expected.
Any explanation? Is xfs spreading these large files around on the disk rather than doing linear sequential writes? If so, why is it doing so much READING from the destination drive and from parity?
See attached image. Source is disk4 and destination is disk5.

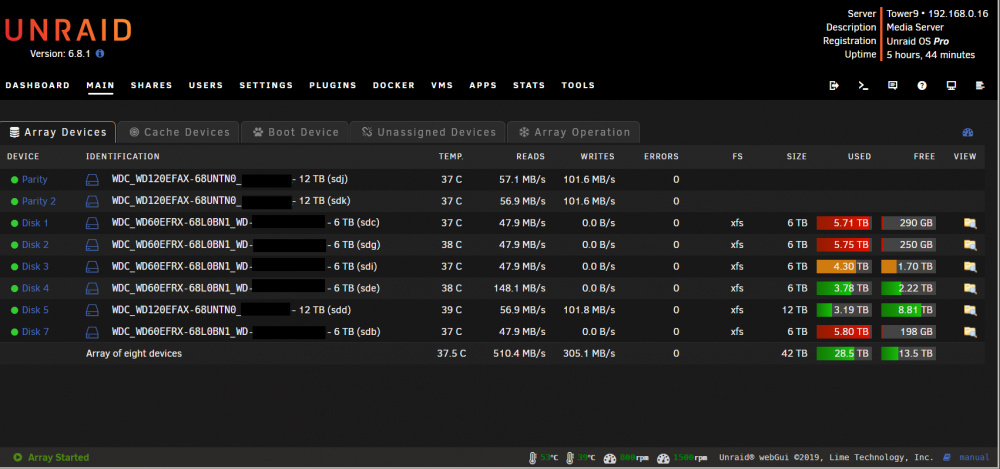
-
On 12/3/2018 at 1:53 PM, johnnie.black said:
Interesting, so trim still works with the 860 EVOs, I'm assuming with a current UnRAID, what model LSI do you have?
Don't touch LSI. I use either Areca or Adaptec SAS controllers with HW RAID and onboard cache. This server is an Adaptec 7000Q series.
I'm staying on 6.5.3 ... can's stand the UI in 6.6... makes me want to vomit.
-
Well, I'm glad I asked. My existing cache drive was 4 PNY 256GB SSDs. hdparm -I says they are RZAT:
Data Set Management TRIM supported (limit 8 blocks)
Deterministic read ZEROs after TRIMSo I decided to do some testing, took them out of HW RAID, secure erased them, and set them up in a btrfs RAID0 cache pool. Worked fine, RAID0 was confirmed working.
But fsutil refused to run on them... reported "discard operation not supported."
Had I not started this thread, I probably would not have proceeded. But in spite of that test, I went ahead and tried a btrfs RAID0 cache pool with 2 Sammy 4TB 860 EVO SSDs.
The kicker.... fstrim appears to work on the Samsung array (at least no errors). Before you ask, the Samsung drives are on the same controller (in fact same ports) as the prior cache pool of PNY SSDs. But I cannot see any relevant difference in trim support between the PNY and Sammy SSD's
-
On 12/1/2018 at 8:13 AM, johnnie.black said:
I took it as he was asking if a raid0 pool is being trimmed and fstrim reports success but not working as it should.
That is the correct interpretation.
On 12/1/2018 at 7:57 AM, johnnie.black said:Yes, most currently recommended LSI HBAs don't currently support trim with Unraid, but the user gets an error when running fstrim, so easy to know, what
IIRC, LSI interrogates the drive capabilities, and if a drive does not specify the type of trim support (DRAT or RZAT) it will not pass trim commands to the drive. Check an SSD with hdparm -I /dev/sdX. The Sammy 860 EVO's I am using correctly report RZAT.
-
I have been running 4 SSDs in hardware RAID 0 as my cache drive for a few years. I need it since I have 10 GBE between workstation and unRAID and really need the speed as I work with large (>100GB) files regularly. I also back up large drives to unRAID regularly over 10 GBE and need the speed.
I leave “hot” files on the cache, since I need read access as fast as possible for a couple of weeks while I work with them.
I have good performance, but the drives are “hidden” behind the HW RAID controller. Most of the files are working copies of files I have stored offline, so they just sit on cache till I am done with them, and they never get moved to the array.
As expected, performance decreases over time since I can’t trim the RAIDed drives. I have to back up cache, break the RAID, secure erase the SSDs, reconfig the RAID and then restore.
I need a much larger cache drive so I am going to use four 4TB SSDs in RAID 0. But I am thinking about using BtrFS to do the raid instead of the HW contoller. The deciding factor will be if I can use fstrim to trim the drives RAID'ed with BtrFS w/o breaking/rebuilding the RAID.
There is conflicting info out there as to whether you can do effective fstrim on the drives in a BtrFS RAID 0 configuration. Some say you can do it but it won’t actually be effective, and other say it does work as expected.
Anyone here want to chime in with their $0.02?
-
I have a collision of two needs.
I love unRAID because in a failure (system itself or drives) I can mount and access the drives from unRAID in Windows box. Using XFS Explorer, R-studio, FTK Imager, XWays, etc, depending on the filesystem, I can get to and recover data. I can also recover data from damaged drives with my forensic software/hardware such as a PC-3000 controller.
I also have wanted native encryption in unRAID for a long time. But encryption with LUKS/dm-crypt complicates the ability to do disaster recovery. I would have preferred TrueCrypt or Veracrypt because of the widespread support, but cest la vie.
Plan B is always boot up Linux, mount the drive with the passphrase, and make a dd image. This takes (potentially a lot of) time and another hard drive. Time is usually short in a disaster recovery. The vast world of forensic recovery software is almost exclusively Windows, particularly the "good" stuff.
So I wanted to start a thread to collect ideas on how to more quickly access encrypted unRAID disks on a Windows box. As of now, I have not tested anything, but have found some candidates:
LibreCrypt
https://github.com/t-d-k/LibreCrypt
FreeOTFE
http://download.cnet.com/FreeOTFE/3000-2092_4-10656559.html (no longer maintained)
Any other suggestions?
-
Just one line changed in default-white.css:
table.wide tbody td{padding:.2em 0} -
Would you consider adjusting the CSS padding in the main drive display table or make it configurable (I use 0.2em rather than the default 10px)? This (and a number of other things) are based on pixels rather than em and don't scale well with high DPI monitors. I've been using a sed script to change it for a long time, but every time the css changes I have to redo the script, and as new themes are developed, I have to write yet another sed command if I want to use the new theme. It would be nice going forward if more things can be em-based css rather than pixels.
-
Don't know if this was a regression in 6.4 or not, but I run emhttp on port 88 rather than 80, and when launching VNC from the VM management page, it does not add the port 88 to the IP, so VNC fails to connect. If I append the :88 to the IP manually, it works fine.
-
Timestamp: 7/7/2017 5:24:00 PM
Error: SyntaxError: expected expression, got '*'
File: DockerSettings.pageSource Code:
if (good && (ippool < ipbase || ippool+2**(32-pool[1]) > ipbase+2**(32-base[1]))) {good = false; swal . . .



10GBE and TcpWindowSize with Windows 10
in General Support
Posted
I'm finally upgrading my main workstation to Windows 10, and I'm using Intel 550 10GBE cards for a direct connection.
Using iperf, I get only about 4Gb/sec ... but if I set the TcpWindowSize size large enough (iperf switch "-w 2048k") I get the expected 9.9 Gb/sec.
This is on a clean win10 install, and it doesn't matter whether I use unRAID as the iperf client or server.... meaning it doesn't matter which system gets the -w flag to initiate the larger TCP window size.
Anyone see this before?