




bubbaQ
Moderators
-
Joined
-
Last visited
Everything posted by bubbaQ
-
I'm finally upgrading my main workstation to Windows 10, and I'm using Intel 550 10GBE cards for a direct connection. Using iperf, I get only about 4Gb/sec ... but if I set the TcpWindowSize size large enough (iperf switch "-w 2048k") I get the expected 9.9 Gb/sec. This is on a clean win10 install, and it doesn't matter whether I use unRAID as the iperf client or server.... meaning it doesn't matter which system gets the -w flag to initiate the larger TCP window size. Anyone see this before?
-
By "haste" I meant abandoning the project permanently. I completed my tests and all the hashes all match, so even on files over a TB, there was no corruption.
-
Don't be hasty.... I'm running hashes against them now to compare to backups. You might just need to use long integers and recompile it.
-
Have you tested it with *large* files? I get overflows with large files. See attached.
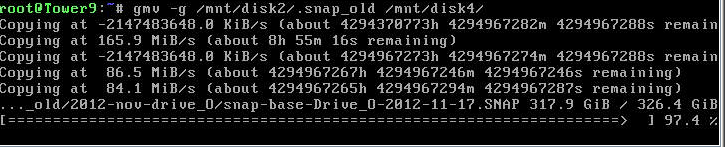
-
The "multi-stream" changes are really killing me. I had to revert to 6.7 as I lost 40% of my throughput when copying disk to disk in the array. Can we get back the ability to set reconstructive write ON and have it *stay* on?
-
What did you do to get it running?
-
To replicate: Size browser so there is no horizontal scrollbar. Resize so there is a horizontal scrollbar. Scroll right. Banner area at top does not cover entire canvas on the right.
-
Some points: - be sure you start the script with "#!/bin/bash" line - be sure you are using Linux line endings, and not Windows. - use apt-get install -y -q <package name> or else it will fail waiting on you to approve it. Also check the log from the unRAID Docker GUI to see the progress of the script.
-
Any reason you abandoned the Syncrify docker? I have Syncrify running on bare-metal in unRAID, and would like to move it to a docker, but didn't want to waste time if there was a deal breaker in it.
-
No, once the webGUI is doing a shutdown, you can't use it for anything else. If you end up in that loop, your only choices are to 1) login via telnet and deal with it by hand at the CLI, or 2) the big red switch. But there is a way to create a back door HTTP listener on another port using awk. I used that for a long time so I had HTTP access to do some things like a "kill-anything-that-has-files-open-and-stop-array-now-damnit" script. But logging in via ssh and doing it from the command line ended up being easier for me than maintaining and upgrading that code with new stuff I wanted.
-
That's what my original did: http://lime-technology.com/forum/index.php?topic=42773.msg407486
-
You have to do a search and replace to insert custom html/javascript into the stock unRAID html. I've done it but it is fraught with peril of 1) it not working on a different version and 2) hosing up the page so a user couldn't get to the buttons to shut down unRAID. But as I said in the original thread, that is a perfect place to put it..... plus adding an extra click-through when stopping the array when there are open files that may block it, so you don't get stuck in a loop.
-
FWIW, you can't run phpvirtualbox in unRAID 6.x even with a web server working, because the php install is incomplete (no extensions, such as SOAP)
-
There are many hardware solutions out there that allow fan speed control via scripts... check out: http://www.sidewindercomputers.com/fancontrollers.html I use the Matrix Orbital, but the T-balancer is a good choice too.
-
It defaults to "disabled" in the BIOS now. I also have this board and like it. Only thing I don't like is the location of some of the headers make them hard to get to with cards installed.
-
It is possible... particularly if s2ram has a specific knowledge of your mobo. Run "s2ram -n" to see if it has your mobo in its database.
-
I have compiled s2ram (from the suspend-0.8 source). Note, you will have to first install libx86 for it to run. Both are in the attached zip file. If you lose your video when you resume, or have trouble getting your machine to go into or wake up from s3 sleep, you may benefit from using s2ram instead of writing the state directly to /sys/power/state. s2ram is cleaner, and does some "preparation" of the system before entering s3 suspend. suspend-utils.zip
-
Intel NICs are cheap and plentiful. Intel NICs built into mobos are not as common. IPMI is not very common. Inexpensive KVM over IP boxes are easy to find. The AOC-SAT2-MV8 works in a PCI slot, and does not have to have PCI-X. OTOH. you can buy a 3rd party fan controller board with PWM control, and roll your own software to control it. If you want a specialized feature, particular multiple ones, you are really limiting yourself by demanding it all come in one unified package. Pick one (IPMI, Intel Nic, PCI-X, Fan control) that you want integrated in the mobo, then use alternatives for the other ones.
-
I have found PWM fan control that I could manipulate with software on every mobo I've tried, on at least one fan port. You can also check the speedfan website, and review sites like SPCR, which will often report where fan speed control was possible. Unfortunately, your requirement of PCI-X slots, ECC memory, and IPMI greatly limits your choices. Why do you have such odd hardware demands?
-
My guess is that the mobo manufacturer either has not exposed the control interface on the chip to be software controlled, or there is something in the BIOS you need to change to enable it. I'd e-mail tech support.
-
Did you try running pwmconfig?
-
No, install a full Slackware dev system on that box, build the drivers needed, and TEST whether you will have pwm fan control. No need to go on a scavenger hunt if what you are looking for won't work when you find it.
-
Did you run sensors-detect ?
-
The standard Slackware DVD is a live boot.
-
If you are up to running unRAID on a full Slackware install, then that is your best option. I would do a test install of Slackware first, and see if you get pwm control of the fans. If you do, then add unRAID. If not, you need to do more research on a driver for your chipset.

