McWetty
Members
-
Joined
-
Last visited
Everything posted by McWetty
-
I just stumbled onto this thread when my Samsung Bar Plus started failing to start Unraid. I initially thought I had too many USB devices plugged in (boot drive, keyboard fob, UPS control) but it seems to be the USB drive's fault. Now I need to go hunt down a USB2 drive and swap the key over. What's the teams long term goals for this issue as USB2 drives become harder to find? Boot from a cache ssd?
-
This fixed my corrupted docker image perfectly and I didn't lose any other docker information. And no need to fresh install Unraid. Wins all around. Cheers!
-
Thanks for that response. 1.) If I just delete the docker image and appdata folders (without fresh installing Unraid) will it achieve the same effect? 2.) How does the docker image get rebuilt by Unraid if I do that? 3.) If I only fresh install without deleting the docker image, will my docker database issues still be there after the install (do they reside on the array or the flash drive)? I'm just not familiar with the underpinnings of Unraid just yet.
-
Hi. I searched around looking for an answer, but I haven't figured it out for my specific case. I'm having an issue with an Immich instance that went sideways. Details: 1.) I installed Immich via the Docker compose official method found here. Everything was working great until it had some upload errors. To the tune of 670 photos missing. I decided to start over with a new instance and followed the instructions for removing Immich found here. 2.) It seemed to work so I went ahead and deleted the /appdata folder related to Immich. I've also deleted (to the best of my knowledge) the Postgres database using sudo rm -rf /var/lib/postgresql/data 3.) I went through each disk and confirmed that there's no reference to Postgres or Immich. There's only my personal files and the appdata I want to keep for Plex/Cloudflare/etc. And the other system folders that have always been there. 4.) I tried to rebuild a new instance of Immich the exact same way I did originally and I get all kinds of errors. "Cannot connect to database" being the most frequent one. 5.) I used all the commands here to clean out dangling assets related to docker. 6.) I reached out on Discord and Reddit for assistance from the Immich devs and they said it should work so long as /var/lib/postgresql/data is gone. But it's not. So I guess I need to reinstall Unraid and wipe out the gremlins in Docker. 1.) How do I eliminate all traces of Docker and "clean" install Unraid without losing the files already present on my disks? 2.) Is it as simple as backing up my key config file, wiping the flash drive, rebuilding using the USB creator, and starting a new config? 3.) Will that eradicate whatever broken database from Postgres is still haunting Immich leaving my personal files untouched? I really don't want to move 40Tb of data (again). I have most of it backed up; but I'd prefer not to have to pull from my backups. And I'm only 90% confident I have EVERYTHING backed up. I'd hate to lose something I overlooked.
-
I had been planning on jumping from Basic to Plus this holiday season (BF/CM discounts) as I'm going to butt up against my current 6 device limit by the end of the year... but this announcement kind of forces my hand as now I want to jump to pro and I did not want to stretch my budget that far this early in the year. I'm happy to support Lime, but I'm operating on thin margins (photographer building a business). 1.) Is there a coupon code for a discount to jump from Basic to Pro now? 2.) Can I wait until BF/CM to upgrade from Basic to Pro at the current price delta? I know it's only $10-20 discount, but like I said... thin margins and struggling artists.
-
As a physicist (hello fellow math nerd), I completely agree about changing one thing at a time. The PSU has been powering the 3x 8Tb drives (and assorted peripherals) very well for the past few months. The only thing I changed was the 18Tb install. Given that the CRC errors are reported, I will change that one variable first and see how it goes from there. If I see other CRC errors, I'll look at other suspects like cables. I'm also not going to sweat the CRC errors if they stay stagnant as suggested by the mods.
-
Thanks all. I have some other drives I can use to expand my Unraid server in the interim. I will be checking all the cables (both SATA and SAS connections) as suggested. The PSU is a brand new Corsair 800W Plat I got on BF so hopefully I can rule that out as the culprit. I'm pretty sure they've always had those write issues (a bad thunderstorm knocked my Syno offline repeatedly while we were out of town) and I've added a UPS to that server. Side note: does Unraid support UPS shutdown a la Synology? I'll report back if the replacement drive throws errors. Ultimately, if the replacements are ok, I'll just RMA all of them and move on. Thanks again.
-
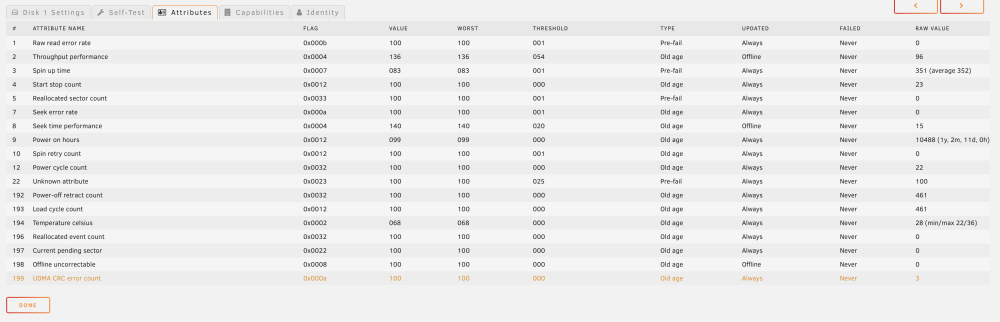
I have 4x 18Tb WD181KFGX drives in my Synology DS1019+ that have been doing fine for around 1 year. I opted to move them (and 3x 8Tb Red Pros) to my Unraid server to combine all drives into one location (I plan to sell the Synology as my storage demands have increased). The 8Tb drives moved over flawlessly and have been running for about a month with zero hiccups. I pulled the first 18Tb for transition and Unraid threw a SMART error flag. So I checked it in a number of SMART test environments and it came back clean. So I put it back in the Syno, rebuilt the array, and everything was fine. Then I pulled a different 18Tb from the Syno for transition and stuck it in the Unraid box... it too threw SMART errors. Wut? Fine... I then ran it through Unraids SMART tests (both short and extended) and it came back clean. Why is Unraid showing it as having errors if the SMART tests are showing it clean? And why would it only be happening to the 18Tb drives? Here's the log for the second drive from Unraid: ATA Error Count: 3 CR = Command Register [HEX] FR = Features Register [HEX] SC = Sector Count Register [HEX] SN = Sector Number Register [HEX] CL = Cylinder Low Register [HEX] CH = Cylinder High Register [HEX] DH = Device/Head Register [HEX] DC = Device Command Register [HEX] ER = Error register [HEX] ST = Status register [HEX] Powered_Up_Time is measured from power on, and printed as DDd+hh:mm:SS.sss where DD=days, hh=hours, mm=minutes, SS=sec, and sss=millisec. It "wraps" after 49.710 days. Error 3 occurred at disk power-on lifetime: 7465 hours (311 days + 1 hours) When the command that caused the error occurred, the device was active or idle. After command completion occurred, registers were: ER ST SC SN CL CH DH -- -- -- -- -- -- -- 84 43 00 00 00 00 00 Error: ICRC, ABRT at LBA = 0x00000000 = 0 Commands leading to the command that caused the error were: CR FR SC SN CL CH DH DC Powered_Up_Time Command/Feature_Name -- -- -- -- -- -- -- -- ---------------- -------------------- 61 20 18 e0 0b 7d 40 08 2d+23:21:11.619 WRITE FPDMA QUEUED 61 20 10 20 13 81 40 08 2d+23:21:11.617 WRITE FPDMA QUEUED 61 20 08 20 11 81 40 08 2d+23:21:11.617 WRITE FPDMA QUEUED 61 20 00 e0 0b 81 40 08 2d+23:21:11.617 WRITE FPDMA QUEUED 61 20 f0 c0 0a 81 40 08 2d+23:21:11.617 WRITE FPDMA QUEUED Error 2 occurred at disk power-on lifetime: 7465 hours (311 days + 1 hours) When the command that caused the error occurred, the device was active or idle. After command completion occurred, registers were: ER ST SC SN CL CH DH -- -- -- -- -- -- -- 84 43 00 00 00 00 00 Error: ICRC, ABRT at LBA = 0x00000000 = 0 Commands leading to the command that caused the error were: CR FR SC SN CL CH DH DC Powered_Up_Time Command/Feature_Name -- -- -- -- -- -- -- -- ---------------- -------------------- 61 60 78 e0 10 7d 40 08 2d+23:19:43.782 WRITE FPDMA QUEUED 61 20 38 60 08 81 40 08 2d+23:19:43.778 WRITE FPDMA QUEUED 61 20 30 c0 06 81 40 08 2d+23:19:43.778 WRITE FPDMA QUEUED 61 20 28 c0 05 81 40 08 2d+23:19:43.778 WRITE FPDMA QUEUED 61 20 20 a0 00 81 40 08 2d+23:19:43.778 WRITE FPDMA QUEUED Error 1 occurred at disk power-on lifetime: 7417 hours (309 days + 1 hours) When the command that caused the error occurred, the device was active or idle. After command completion occurred, registers were: ER ST SC SN CL CH DH -- -- -- -- -- -- -- 84 43 00 00 00 00 00 Error: ICRC, ABRT at LBA = 0x00000000 = 0 Commands leading to the command that caused the error were: CR FR SC SN CL CH DH DC Powered_Up_Time Command/Feature_Name -- -- -- -- -- -- -- -- ---------------- -------------------- 61 20 78 c0 cf 80 40 08 23:20:30.907 WRITE FPDMA QUEUED 61 20 b0 c0 dd 80 40 08 23:20:30.902 WRITE FPDMA QUEUED 61 20 a8 c0 dc 80 40 08 23:20:30.902 WRITE FPDMA QUEUED 61 20 a0 c0 db 80 40 08 23:20:30.902 WRITE FPDMA QUEUED 61 40 98 a0 d9 80 40 08 23:20:30.902 WRITE FPDMA QUEUED And here's the attribute page from the first drive (that's back in the Syno): Final question: what can I do to fix this? I am already RMA'ing one of the drives in hopes that the replacement is fresh and doesn't trigger any SMART warnings. But I don't want to have to RMA every drive unless absolutely necessary. Especially since this seems to be an Unraid-only issue. Suggestions?
-
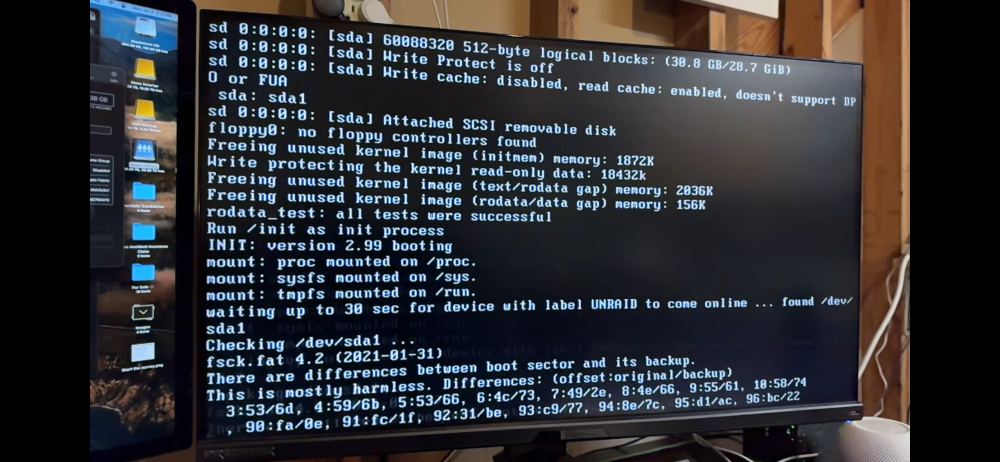
I just did as instructed. I tried first on Windows, but the UnRaid USB creator app gave me an "incompatible" marker on the drive. So, I plugged the flash drive into my Mac and ran the creator app there to completion. No errors. Moved the config folder back over and plugged the drive into my USB 2.0 port on the server. Still getting "not automatically fixing this" during boot up. Again, the server seems to be running fine, but that error kind of niggles the back of my mind.
-
I found a, 8Gb USB2.0 drive. Would it be wise to use that one? I have read that USB3.0 drives can cause issues.
-
Is there a noob approved guide for that so I don't make a mistake? I backed it up to UnRaid connect.
-
I too have run into this issue. I didn't want to open a new thread, so I'll just post to this one. I pulled the USB drive out and ran chkdsk on it in Win11. No errors. Stuck it back in and "not automatically fixing this" popped up again. Is this because it's a USB3.0 drive? I don't even know if I have any USB2.0 drives anymore. UnRaid is working fine, but I'm just a stickler for errors.