GatorMB
Members
-
Joined
-
Last visited
Everything posted by GatorMB
-
Good morning! Here is the update... Server is 100% stable. It has not crashed at all since the cpu was swapped out. However, I did find another issue. The Nvidia Tesla P4 GPU gets super hot when transcoding 3 files in tdarr. I have disabled the tdarr container and it runs stable. I have ordered a fan for the GPU to help cool it. More to follow on the success of that! Again, huge thanks to JorgeB & JonathanM for all your help!
-
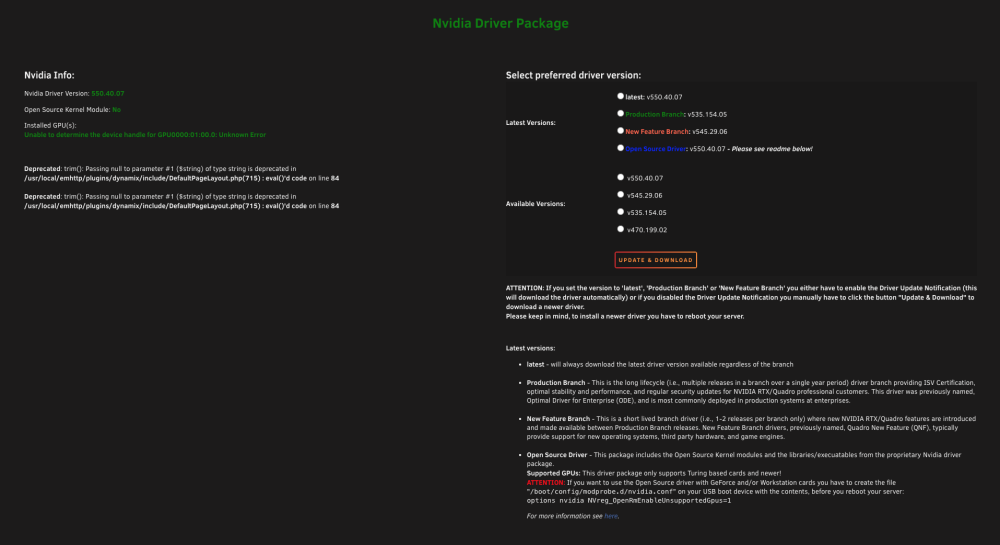
For some reason the GPU card shows when I boot, and then it falls off the system. I caan't see the card details in the nVidia driver section, and I can't see. it in the GPU Statistics plugin. Am I doing something wrong, or is it a bad gpu? What is another alternate GPU you would recomment that won't break the bank?
-
System is stable. It was 100% a bad processor. Thanks everyone for all your help!
-
New processor arrived today. It’s now in and I’m up and running. I will report back within 72 hours if it’s stable. Fingers crossed!
-
I do also notice that I get a failure on the GPU plugin in Unraid on occasion. Do I need to disable the onboard video now that I am running the Tesla P4?Or do I have a bad GPU as well?

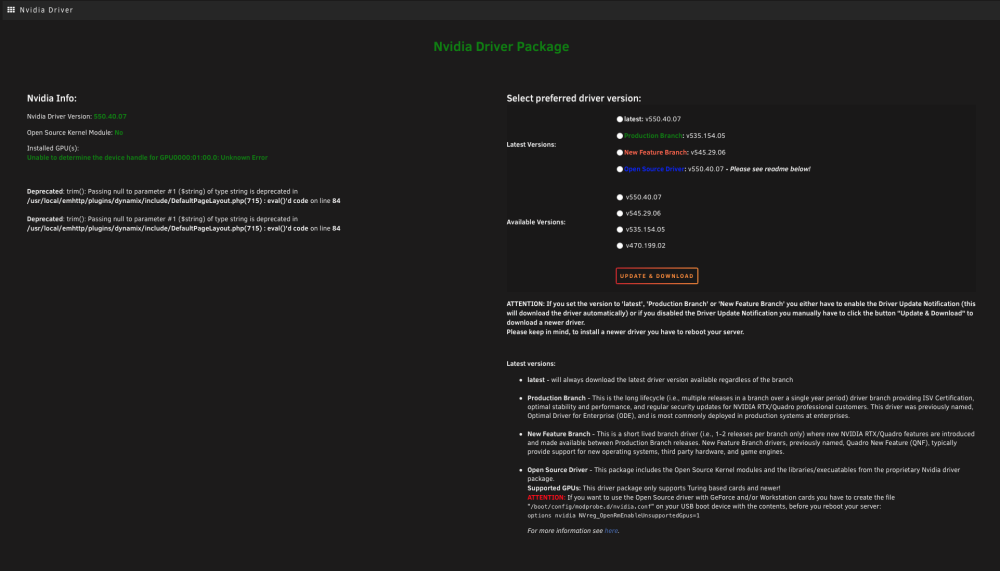
-
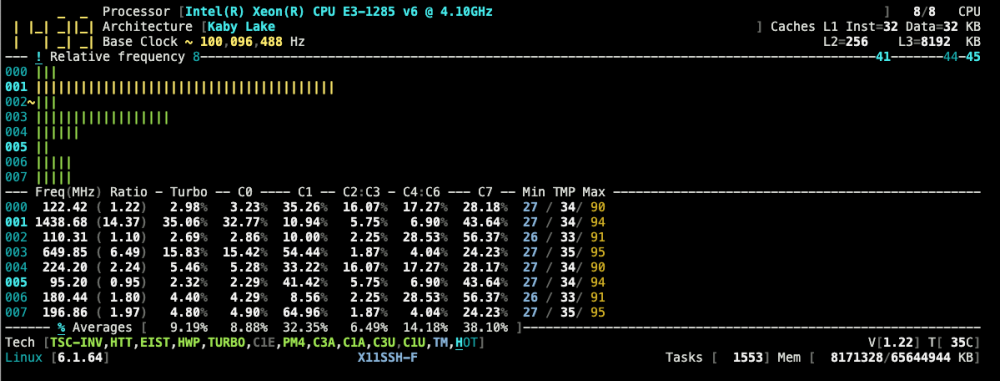
I'm starting to believe you are correct. I initially ran this box with a Supermicro x9scl mobo and cpu and it ran perfect. It just couldn't handle transcoding and the mobo didn't have a slot for a gpu card. I upgraded the mobo to the Supermicro x11ssh-f and the cpu to the xeon e3-1285v6. Ram went from 32 to 64. All drives, psu, cooling, case stayed thee same. I started having failures. I changed the ram and still same issue. I changed the mobo and same issue. I changed the psu from 600 80+ white to 850 80+ gold. I added liquid cooling. I added a Tesla P4. Nothing has eliminated the problem. The only thing left is the CPU. I am waiting for a xeon e3-1270v6 to arrive in a few days. I'll swap it out and see if that helps. If not then I'm at a total loss as to what could be causing it! Could it be bios related? I have BMC connected, but don't have the password, so I will need to reset it via the jumper? Then I can review it on a remote pc. I have link aggregation connected from the mobo to my ASUS GT-AC5300 router. I literally have no idea what else to try?! I have the syslog going to root on the flash drive, but nothing seems to stand out to you or others... Do you think it could just be a bad CPU?!
-
Ok, so I went away to the lake yesterday am and left the server running. I got back an hour ago and it's all locked up again. Not showing on the network either. Did a hard reset and it came up fine. Here are the logs. I can't figure this out! Someone please point me in the right direction! syslog syslog-previous
-
No, I don't leave any active connections. It's a headless server and I only log in to run a process or to try to figure out an use such as this. I'm going to enable the IPMI function and connect that lan port for diagnostics later this weekend.
-
So yesterday I woke up to an unresponsive server again. No network connectivity, nothing. So, I decided to try 2 more things. I changed the PSU from a 600w to a new corsair 850 80+ Gold. I then added a corsair water cooler for the cpu. Again this am, I woke to a non-responsive server. But this time it was still showing on the router as connected. If it crashes over the weekend, I'll upload a new set of logs. goldraid-diagnostics-20240216-2022.zip syslog-2.txt
-
I will after this learning experience! lol It’s running fine now. I’ll post in the morning and let you know if it crashed again. Thanks again for all your help!
-
Ok, then how would I reset it to that?
-
What would you suggest?
-
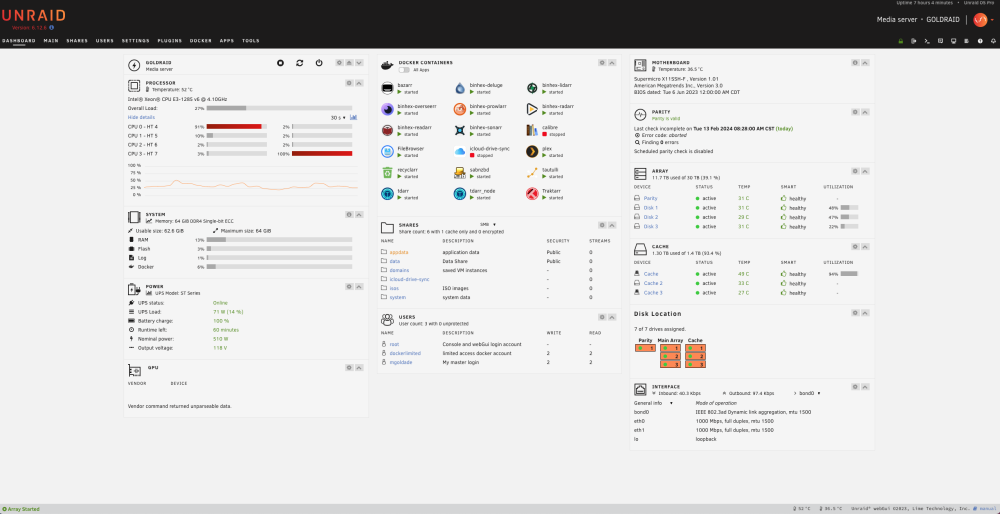
I went to the bash command and made sure all appdata / domains / system shares were moved to the cache using: rsync -av --remove-source-files /mnt/disk2/appdata/ /mnt/cache/appdata/ It moved all files. I then removed all empty folders left behind: find /mnt/disk2/appdata/ -type d -empty -delete I corrected appdata folder permissions: chmod -R 755 /mnt/cache/appdata/ chown -R nobody:users /mnt/cache/appdata/ I made sure that the appdata / domains / system shares were all now cache only in my shares menu. I made sure that the data & iCloud-drive-sync shares were all now pointing to array in my shares menu. I reloaded the nvidia driver, and installed the gpu statistics plug-in. I removed changed the macvlan to ipvlan. I have checked the cache pool and It's still pretty full (I think). I have a 2tb ssd and a 256GB ssd. Do I need a larger cache pool? What am I missing? And before I forget, huge thanks to trurl & JorgeB for all your help. I really appreciate the time you are taking!
-
NETWORK ID NAME DRIVER SCOPE 400cca84e0d2 br0 ipvlan local 06eb05e8c95b bridge bridge local 74b5ac950c5a host host local 8c0d0933753b none null local
-
So, it crashed again. Here is the syslog info. syslog-previous.txt syslog.txt
-
More specifically, here is a snippet of the log that I think might be an issue that I have no idea to resolve. Feb 14 09:38:01 GOLDRAID root: Fix Common Problems Version 2024.01.18 Feb 14 09:38:02 GOLDRAID root: Fix Common Problems: Warning: Share appdata set to cache-only, but files / folders exist on the array Feb 14 09:38:02 GOLDRAID root: Fix Common Problems: Warning: Docker Application bazarr has an update available for it Feb 14 09:38:10 GOLDRAID kernel: ------------[ cut here ]------------ Feb 14 09:38:10 GOLDRAID kernel: WARNING: CPU: 2 PID: 270 at net/netfilter/nf_conntrack_core.c:1210 __nf_conntrack_confirm+0xa4/0x2b0 [nf_conntrack] Feb 14 09:38:10 GOLDRAID kernel: Modules linked in: nvidia_uvm(PO) macvlan xt_nat xt_tcpudp veth xt_conntrack xt_MASQUERADE nf_conntrack_netlink nfnetlink xfrm_user xfrm_algo iptable_nat nf_nat nf_conntrack nf_defrag_ipv6 nf_defrag_ipv4 xt_addrtype br_netfilter xfs md_mod zfs(PO) zunicode(PO) zzstd(O) zlua(O) zavl(PO) icp(PO) zcommon(PO) znvpair(PO) spl(O) tcp_diag inet_diag jc42 regmap_i2c ip6table_filter ip6_tables iptable_filter ip_tables x_tables efivarfs 8021q garp mrp bridge stp llc bonding tls igb intel_rapl_msr intel_rapl_common x86_pkg_temp_thermal intel_powerclamp coretemp nvidia_drm(PO) nvidia_modeset(PO) kvm_intel i915 kvm crct10dif_pclmul crc32_pclmul crc32c_intel ghash_clmulni_intel sha512_ssse3 ast sha256_ssse3 sha1_ssse3 aesni_intel crypto_simd drm_vram_helper iosf_mbi drm_ttm_helper drm_buddy ipmi_ssif cryptd nvidia(PO) drm_display_helper rapl ttm mpt3sas drm_kms_helper intel_cstate raid_class intel_uncore drm intel_gtt i2c_i801 joydev i2c_smbus scsi_transport_sas agpgart syscopyarea ahci Feb 14 09:38:10 GOLDRAID kernel: i2c_algo_bit mei_me input_leds acpi_ipmi led_class video sysfillrect i2c_core mei libahci sysimgblt intel_pch_thermal wmi fb_sys_fops thermal fan ipmi_si backlight intel_pmc_core acpi_power_meter acpi_pad button unix [last unloaded: igb] Feb 14 09:38:10 GOLDRAID kernel: CPU: 2 PID: 270 Comm: kworker/u16:5 Tainted: P IO 6.1.64-Unraid #1 Feb 14 09:38:10 GOLDRAID kernel: Hardware name: Supermicro PIO-1UUP-ND1-AI036/X11SSH-F, BIOS 3.0 06/06/2023 Feb 14 09:38:10 GOLDRAID kernel: Workqueue: events_unbound macvlan_process_broadcast [macvlan] Feb 14 09:38:10 GOLDRAID kernel: RIP: 0010:__nf_conntrack_confirm+0xa4/0x2b0 [nf_conntrack] Feb 14 09:38:10 GOLDRAID kernel: Code: 44 24 10 e8 e2 e1 ff ff 8b 7c 24 04 89 ea 89 c6 89 04 24 e8 7e e6 ff ff 84 c0 75 a2 48 89 df e8 9b e2 ff ff 85 c0 89 c5 74 18 <0f> 0b 8b 34 24 8b 7c 24 04 e8 18 dd ff ff e8 93 e3 ff ff e9 72 01 Feb 14 09:38:10 GOLDRAID kernel: RSP: 0000:ffffc90000178d98 EFLAGS: 00010202 Feb 14 09:38:10 GOLDRAID kernel: RAX: 0000000000000001 RBX: ffff88879ccdf800 RCX: 0c5d9175f44708e9 Feb 14 09:38:10 GOLDRAID kernel: RDX: 0000000000000000 RSI: 0000000000000001 RDI: ffff88879ccdf800 Feb 14 09:38:10 GOLDRAID kernel: RBP: 0000000000000001 R08: fe5f0278be059942 R09: 76ba4064315dc017 Feb 14 09:38:10 GOLDRAID kernel: R10: d444fff6b20efcb2 R11: ffffc90000178d60 R12: ffffffff82a14d00 Feb 14 09:38:10 GOLDRAID kernel: R13: 0000000000034e1b R14: ffff888416ba0400 R15: 0000000000000000 Feb 14 09:38:10 GOLDRAID kernel: FS: 0000000000000000(0000) GS:ffff889055280000(0000) knlGS:0000000000000000 Feb 14 09:38:10 GOLDRAID kernel: CS: 0010 DS: 0000 ES: 0000 CR0: 0000000080050033 Feb 14 09:38:10 GOLDRAID kernel: CR2: 00001fb78b21b000 CR3: 00000002e2362001 CR4: 00000000003706e0 Feb 14 09:38:10 GOLDRAID kernel: DR0: 0000000000000000 DR1: 0000000000000000 DR2: 0000000000000000 Feb 14 09:38:10 GOLDRAID kernel: DR3: 0000000000000000 DR6: 00000000fffe0ff0 DR7: 0000000000000400 Feb 14 09:38:10 GOLDRAID kernel: Call Trace: Feb 14 09:38:10 GOLDRAID kernel: <IRQ> Feb 14 09:38:10 GOLDRAID kernel: ? __warn+0xab/0x122 Feb 14 09:38:10 GOLDRAID kernel: ? report_bug+0x109/0x17e Feb 14 09:38:10 GOLDRAID kernel: ? __nf_conntrack_confirm+0xa4/0x2b0 [nf_conntrack] Feb 14 09:38:10 GOLDRAID kernel: ? handle_bug+0x41/0x6f Feb 14 09:38:10 GOLDRAID kernel: ? exc_invalid_op+0x13/0x60 Feb 14 09:38:10 GOLDRAID kernel: ? asm_exc_invalid_op+0x16/0x20 Feb 14 09:38:10 GOLDRAID kernel: ? __nf_conntrack_confirm+0xa4/0x2b0 [nf_conntrack] Feb 14 09:38:10 GOLDRAID kernel: ? __nf_conntrack_confirm+0x9e/0x2b0 [nf_conntrack] Feb 14 09:38:10 GOLDRAID kernel: ? nf_nat_inet_fn+0x60/0x1a8 [nf_nat] Feb 14 09:38:10 GOLDRAID kernel: nf_conntrack_confirm+0x25/0x54 [nf_conntrack] Feb 14 09:38:10 GOLDRAID kernel: nf_hook_slow+0x3a/0x96 Feb 14 09:38:10 GOLDRAID kernel: ? ip_protocol_deliver_rcu+0x164/0x164 Feb 14 09:38:10 GOLDRAID kernel: NF_HOOK.constprop.0+0x79/0xd9 Feb 14 09:38:10 GOLDRAID kernel: ? ip_protocol_deliver_rcu+0x164/0x164 Feb 14 09:38:10 GOLDRAID kernel: __netif_receive_skb_one_core+0x77/0x9c Feb 14 09:38:10 GOLDRAID kernel: process_backlog+0x8c/0x116 Feb 14 09:38:10 GOLDRAID kernel: __napi_poll.constprop.0+0x28/0x124 Feb 14 09:38:10 GOLDRAID kernel: net_rx_action+0x159/0x24f Feb 14 09:38:10 GOLDRAID kernel: __do_softirq+0x126/0x288 Feb 14 09:38:10 GOLDRAID kernel: do_softirq+0x7f/0xab Feb 14 09:38:10 GOLDRAID kernel: </IRQ> Feb 14 09:38:10 GOLDRAID kernel: <TASK> Feb 14 09:38:10 GOLDRAID kernel: __local_bh_enable_ip+0x4c/0x6b Feb 14 09:38:10 GOLDRAID kernel: netif_rx+0x52/0x5a Feb 14 09:38:10 GOLDRAID kernel: macvlan_broadcast+0x10a/0x150 [macvlan] Feb 14 09:38:10 GOLDRAID kernel: ? _raw_spin_unlock+0x14/0x29 Feb 14 09:38:10 GOLDRAID kernel: macvlan_process_broadcast+0xbc/0x12f [macvlan] Feb 14 09:38:10 GOLDRAID kernel: process_one_work+0x1a8/0x295 Feb 14 09:38:10 GOLDRAID kernel: worker_thread+0x18b/0x244 Feb 14 09:38:10 GOLDRAID kernel: ? rescuer_thread+0x281/0x281 Feb 14 09:38:10 GOLDRAID kernel: kthread+0xe4/0xef Feb 14 09:38:10 GOLDRAID kernel: ? kthread_complete_and_exit+0x1b/0x1b Feb 14 09:38:10 GOLDRAID kernel: ret_from_fork+0x1f/0x30 Feb 14 09:38:10 GOLDRAID kernel: </TASK> Feb 14 09:38:10 GOLDRAID kernel: ---[ end trace 0000000000000000 ]--- Feb 14 09:38:12 GOLDRAID root: Fix Common Problems: Warning: Syslog mirrored to flash
-
syslog.txt I have enabled the syslog and when I get more data I will forward it after the next crash. For now, this is all I have. Are my shares setup incorrectly?
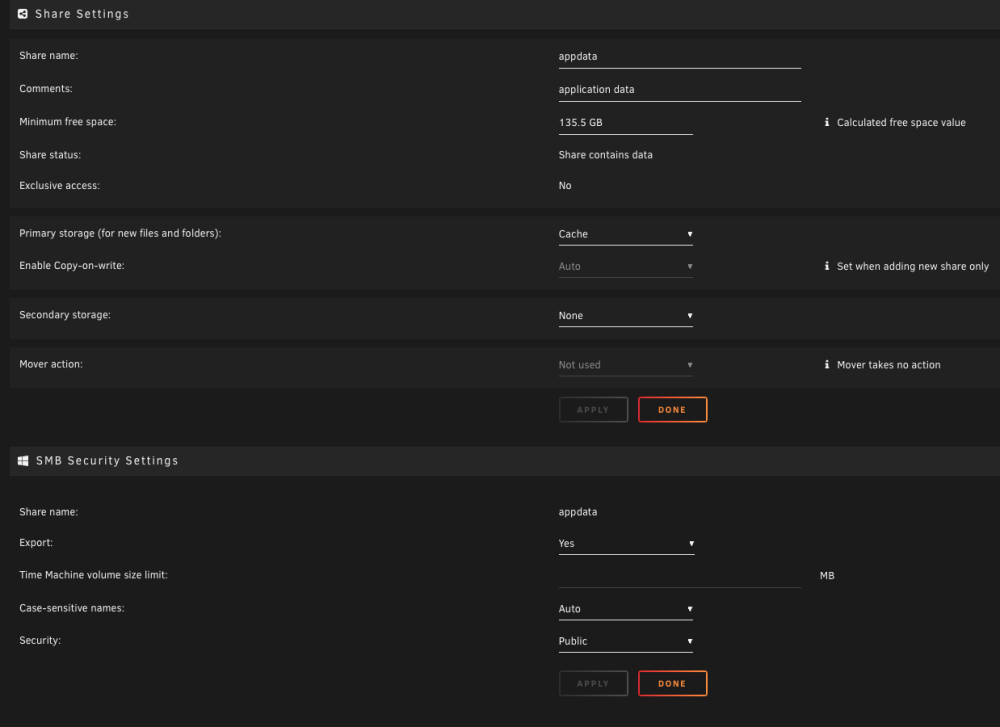
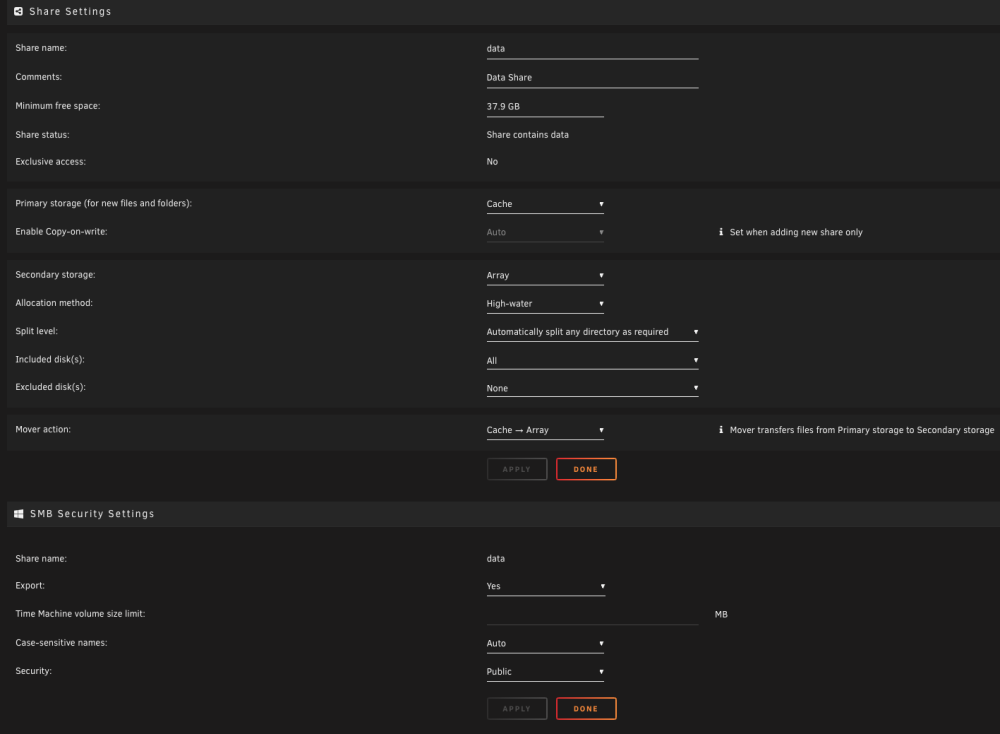
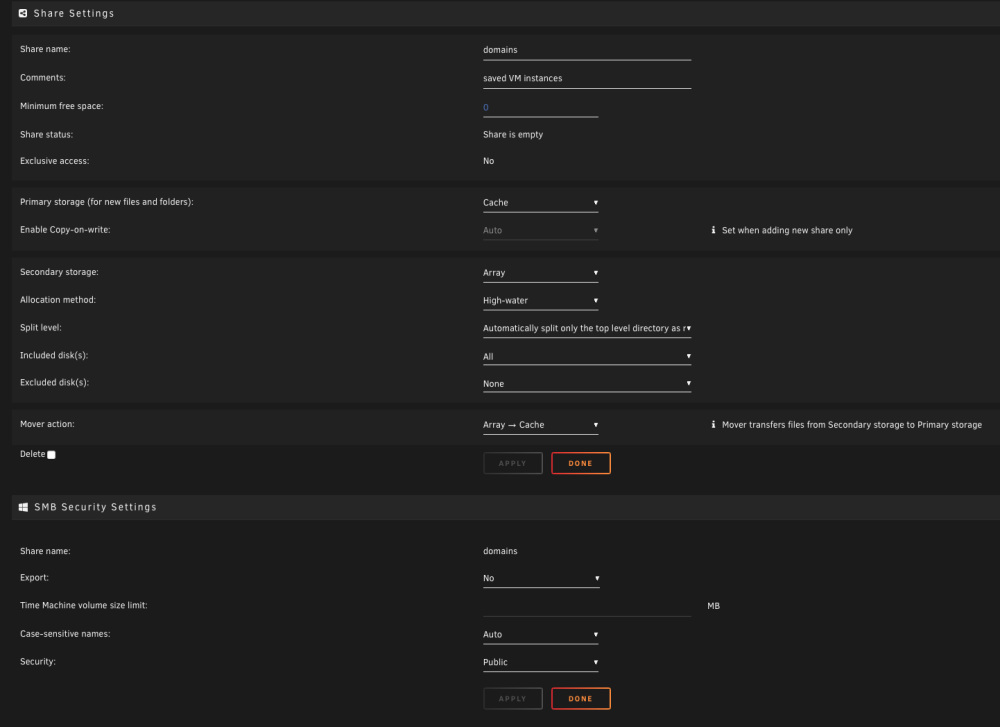
-
I have enabled the persistent syslog server. I will hopefully have better info soon. I woke up this AM and it had locked up again. goldraid-diagnostics-20240214-0912.zip
-
Hope this helps. goldraid-diagnostics-20240213-1617.zip goldraid-syslog-20240213-2221.zip
-
Good day all, Disclaimer, I'm new to this and honestly fumbling along as best as I can. I have exhausted multiple resources prior to posting here. My system specs are in my signature. I built my server initially with a Supermicro x9SCL mobo / xeon e3-1230v2 and 16gb ram. It ran well, but transcoding was an issue. I decided to replace a few items. I changed to the X11SSH-F mobo, xeon e3-1285v6 and 64GB UDIMM. I then added the Tesla p4. It is a headless server. With the new setup, it runs good and the TDARR and Plex containers are utilizing the GPU for transcoding now. However, when I go to bed, I wake up and I can no longer access the server from anywhere. The MAC address doesn't even populate in the router. I end up shutting off the power to the server and rebooting. This will allow me to access it from a desktop again. Sometimes I can access it for hours, and sometimes it locks up again in minutes. As of right now, it's been up for 6h57m. It's like when it's not being accessed, it just times out. I have brought it up to my office and connected it to a monitor and no difference. I have tried another mobo, tried new ram, reloaded everything one step at a time. The only thing I haven't replaced is the cpu. It this a config issue or a hardware issue? I have absolutely no idea and am unsure where to find more info. Any help is greatly appreciated!!