




delgadot2040
Members
-
Joined
-
Last visited
-
so this seems to have worked for me: removed the binding from the vfio and USB controller completely so it can be read by the unraid server system device. Remove the ticked box in the VM edit form view to make sure the usb is no longer connected. In the XML view is where I added the USB controller in the hostdev section. I noticed at this point i could get into the vm but that if things were plugged into the usb controller while starting it, there would be some pinning now and then. i then switched back to UEFI mode just to test and everything worked straight away. by making sure i had the full multifunction section of the XML in place for the GPU i no longer got errors within the VM. by using UEFI mode again I no longer had pinning issues with the USB controller. I hope this helps others
-
i should have also mentioned that i recently also switched from UEFI mode to Legacy for boot as per spaceinvaders advice. That helped with my GPU passthrough but maybe thats the cause of the problem here?
-
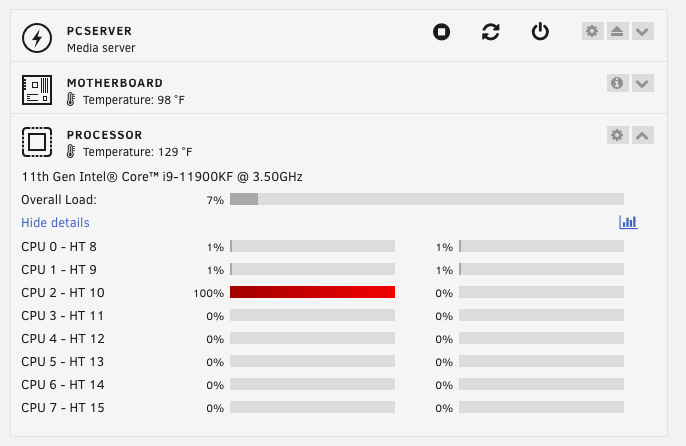
I am having an issue when it comes to passing through both my gpu and usb controller into my windows vm. i had been running both together until i recently went back to the XML and fixed my gpu. i had been getting error 43 on the gpu driver because i reverted the original XML to make changes to the vm on the form view side of things. i forgot to go back and redo the xml side but once i fixed that, this new issue popped up smh. when i try to run the vm passing through both the gpu and usb controller, my cpu 2 gets pinned to 100% and doesnt allow the vm to start. I have to terminate the process for the core to go back to idle. if i remove the usb controller from the vm, it starts perfectly fine. so something about the two together is causing the problem. any ideas of what i can do here? bus='0x04' is the USB controller i am wanting to pass through. my XML for the vm: my log for the vm starting: System Information Model:Custom M/B:Micro-Star International Co., Ltd. Z590 PRO WIFI (MS-7D09) Version 1.0 s/n 07D0910_L31E243506 BIOS:American Megatrends International, LLC. Version 1.90 Dated 06/06/2023 CPU:11th Gen Intel® Core™ i9-11900KF @ 3.50GHz HVM:Enabled IOMMU:Enabled Cache:L1 Cache: 384 KiB, L1 Cache: 256 KiB, L2 Cache: 4 MiB, L3 Cache: 16 MiB Memory:32 GiB DDR4 (max. installable capacity 64 GiB) Network:eth0: 1000 Mbps, full duplex, mtu 1500 Kernel:Linux 6.1.79-Unraid x86_64 OpenSSL:1.1.1v pcserver-diagnostics-20240404-0237.zip

-
just reading up a bit and now am questioning if this is the source of my problem? this is how im powering every drive in my case thru a 750w PSU if this is likely the reason for the issue, can someone recomend me a proper or better alternative to use for 6 drives?

-
just checked on the status of the parity sync and its 67% done going 141mbps. so that looks normal but the log says this now as i thought the issues just keeps shifting to every ata, now at number 6. it cant be that every cable is messed up right?
-
Hey all, I been having an odd one the past few days regarding my drives. First i noticed one drive was making some noise during a scheduled parity check. I looked at the server and noticed it was only going at like 5mbps for the check when i usually hit around 120-150mbps. I saw the log and it said it was one of my white label WD shucked drives. so i thought maybe its just crapping out on me. removed it from the array and tried again parity sync with it unassigned. now the same log error appeared on a new seagate drive... at least this time the speed started about 70mbps now at 140, but it cant be the drive. something else is going on here and im not sure what. this is what the log looks like during parity sync. the only thing the changed between the attempts was first it was ata5, and once unassigned it became ata2. i have attached my diagnostics. i tried unplugging all cables and putting them back but got the same results System Information Model:Custom M/B:Micro-Star International Co., Ltd. Z590 PRO WIFI (MS-7D09) Version 1.0 s/n 07D0910_L31E243506 BIOS:American Megatrends International, LLC. Version 1.90 Dated 06/06/2023 CPU:11th Gen Intel® Core™ i9-11900KF @ 3.50GHz HVM:Enabled IOMMU:Enabled Cache:L1 Cache: 384 KiB, L1 Cache: 256 KiB, L2 Cache: 4 MiB, L3 Cache: 16 MiB Memory:32 GiB DDR4 (max. installable capacity 64 GiB) Network:eth0: 1000 Mbps, full duplex, mtu 1500 Kernel:Linux 6.1.82-Unraid x86_64 OpenSSL:1.1.1v pcserver-diagnostics-20240401-2125.zip
-
So this code 43 issue just began happening to me tonight at random. i tried a bunch of things i found online about it and this helped me get back video... does anyone know why this starts happening? or a better solution than unplugging and replugging the hdmi cable each time? exact same situation as Shan, disable and enable or uninstall of the device goes back to code 43 after a few seconds.
-
so an update after putting tape on the third pin of the power input on disk3 things have stayed up now for 19 hours. I have been running my vm for gaming, running torrents, plex, and doing a parity check. no crashes knock on wood. im going to assume the problem was the WD white label with that power pin. just wanted to come back and let yall know incase anyone else runs into this in the future.
-
could this have something to do with that drive being a WD white label that was shucked and it has a 3.3v pin? disk 2 was the same but i put tape over the third pin after it was not recognized on initial install. the tape solved that drive. when i put in disk 3, also a shucked white label, it was recognized immediately without having to cover that pin so i never did. perhaps if i remove the drive add the tape on the pin like the other it will function as intended.
-
it just crushed on me now with the original 2 sticks of ram. It happened while launching a game inside my windows vm. Could it have something to do with the vdisk being shared on an nvmie drive that im also using as my cache? idk what to do or try here is the latest log syslog-.log
-
is it possible that the 4 sticks of ram messed with the communication to the disk you mentioned? the server seems to be running ok with the original two ram sticks. i might get some bigger sized pair of sticks to replace these and to avoid installing 4. any advice?
-
hmm thats interesting. here you go pcserver-diagnostics-20240224-1341.zip
-
I have removed the two sticks of ram and left the original two in, so far no crash with an up time of 4 hours and counting. does the syslog specify the ram was the issue?
-
ok so i ran the test overnight and the memory passed with 0 errors. i noticed the ram config were as follows and i was not using these settings because i had xmp enabled at the time of the crash. (that was running at 2933 speed) IMG_0850.HEIC so perhaps the crash was caused by the ram being pushed harder than it could handle? when the test finished i went into my bios and checked to see if i had the same basic ram config and NOT with the xmp settings. IMG_0852.HEIC i also noticed that IOMMU had been disabled again so i enabled it. with the ram settings that passed the memtest i started unraid again and tried to run my windows vm again but the hdmi connected to my gpu did not pass the signal even though i reenabled IOMMU. my screen changes from the initial unraid linux load scroll text to a black screen as if the vm was going to come thru but then it just says no signal. i tried to stop the vm but it would not and i needed to use the force stop option to close it. so i am able to run unraid but not my vm. what should i do? EDIT/ i was able to get back in my vm by unbinding and rebinding my video card to the vfio. the strange thing is now the offical unraid logo does not appear before loading the vm.. it just goes to black screen, no signal and then im in windows. if none of this seems like a major issue i am fine with testing this new ram setting on the system until a new crash happens. once that happens i have the syslog server going to capture the log and i could come back here with that info. worst case scenario i just remove the two new sticks of ram i installed and go with the old setup that didnt have an issue. let me know if that sounds like a good plan of action. thanks yall Double Edit// so the system just crashed... here are the logs from the server syslog.log
-
i setup syslog server after posting this thread as i saw others say this is a way to check crash logs. i am currently running Memtest86 but it looks like it gonna be a while to complete. i did recently add another kit of identical ram to my system so maybe thats the issue? hopefully the test shows more.



