




STEX20
Members
-
Joined
-
Last visited
Everything posted by STEX20
-
Hi Jorge, the rebuild finished without problems, after that i have written multiple TB of Data to the Array (including the Drive which started this Thread) and no Problems occured. I will mark your last post as "solution" since the Problem didn't return after the rebuild. Maybe it was just a loose connection. Thanks anyways and i will post again if i have any further problems.
-
Thanks Jorge! I started the array and disk 15 (emulated) was shown as empty, which i guess is okay, since the file copied at the moment of the error wasn't written completely and therefore removed. No worries, i can copy it again from the old storage. As i wrote in my first post the copy had just begun writing to this disk as the error occured. Since i didn't see anything else wrong i stopped the array, unassigned disk 15, started and stopped the array again and re-assigned the disk back to the slot of disk15. now its rebuilding, which will take some time (approx. 11 hours) i will reply again after the rebuild is done and i have copied some data on the disk15. If it fails again i would first swap both PCIe x1 SATA-controllers with each other and see what happens, and then would change the SATA Cable if the Problem persists. If i find something i'll let you know, right now i have to wait for the rebuild to finish.
-
New diagnostics after reboot attached. Pulled the SATA controller, cleaned the contacts, plugged it back in Reseated the SATA connectors on both the controller and harddisks in question. Inspected Cables for visible damage to the SATA Cables --> found none Reseated the power connectors on the harddisks in question. After Reboot the harddrives are (read) error-free in the Web UI. But the disk15 is still marked with red X Is it safe to start the array and try to write some data (will this change the status of disk15? SMART is readable again) or should i do another diagnostic step before? Thanks! unraid-diagnostics-20240520-1856.zip
-
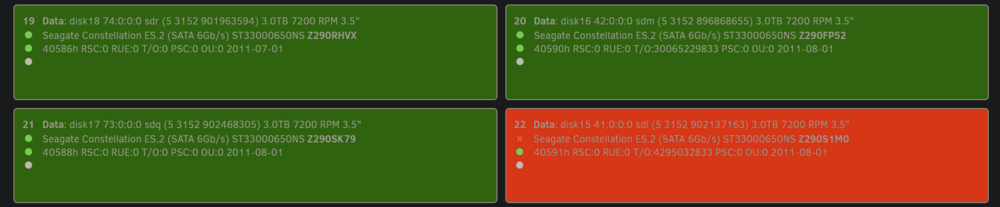
I don't have the calculations i did before purchase at hand at the moment, but i added all of the maximum currents of all harddrives together and it was approximately 250 watts @12V for the harddrives. I compared the currents for 5V and 12V with the specs of the power supply and decided to go one step bigger (850W vs 750W) to be on the safe side regarding the currents, since harddrives take the maximum of power when they are spinning up. I would think that a problem with the amount of power supplied would show while bootup (all disks spinning or starting) and not while (in this instance) 22 of 26 disks were spun down and hardly using any power (in the range of 0,5W per Disk) from the supply. Before i put any Data on it i tried multiple times to boot the machine and the power supply did this without any problems. Controller Issue: yes that could be possible. 2 of the 4 controllers are PCIe x4 and 2 of them are PCIe x1 attached due to limitations of the slots on the MB. But they are all of the same brand (MZHOU - Chipset ASM1166). These were mentioned somewhere in the Forums as working and ASPM compatible. The SATA Connections are as follows: The 20TB Toshibas are connected directly to the MB. 1. Controller ASM1166 (PCIe x4) -> half of the WD Red Pro and half of the WD Red - 6 harddrives total 2. Controller ASM1166 (PCIe x4) -> half of the WD Red Pro and half of the WD Red - 6 harddrives total 3. Controller ASM1166 (PCIe x1) -> half of the Constellation ES.2 and half of the Constellation ES.3 - 5 harddrives total 4. Controller ASM1166 (PCIe x1) -> half of the Constellation ES.2 and half of the Constellation ES.3 - 5 harddrives total Edit: I just saw that the disk15 shows 4295032833 Command Timeouts in the Disk Location Plugin. I guess thats just another clue to what happened, but i don't know if its visible in the diagnostics: and the disk16 is reporting 30065229833 Command Timeouts, both are on the same SATA Controller. The other two: disk17 and 18 are on the other x1 Controller, and have no timeouts reported. Can i shutdown the system to check the Cables and the reseat the Controller in the PCIe Slot? And the System isn't able to show any SMART values for the errored drives:

-
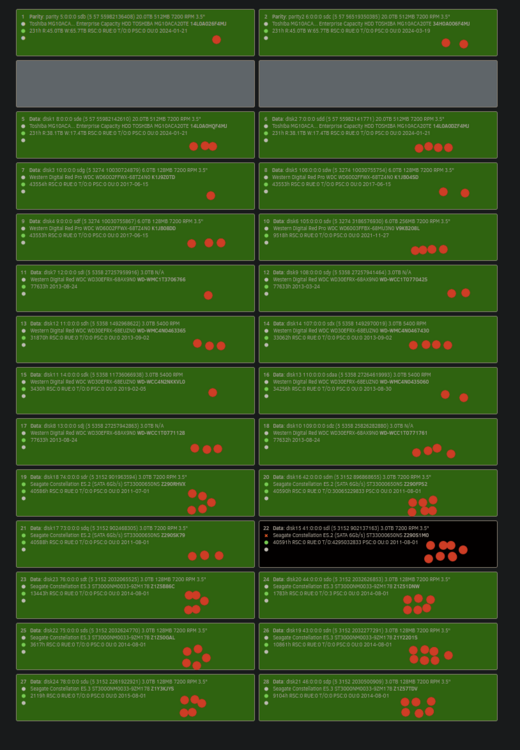
Hi Jorge, thanks for your reply. yes, i am using power splitters in the following configuration: My power supply comes with 5 plugs for Drive connections 1 Cable with Molex Only (x4) 2 Cables with 4x SATA 2 Cables with 3x SATA I purchased 3 splitters: 1x Molex -> 5x SATA since the Molex connector is generally good for up to 10 A of current while the SATA connectors are only good up to 1,5 A Number of red Dots - Connection to power Supply 1x Molex -> 5 SATA (4 used) 1x Molex -> 5 SATA (4 used) 1x Molex -> 5 SATA (5 used) 4x SATA direct (4 used) 4x SATA direct (4 used) 3x SATA direct (3 used) 3x SATA direct (3 used) so the failed & emulated drive is on Connection with 7 Dots - direct to power Supply with supplied Cable by Manufacturer and the other errored drives are on Connections 3, 5 and 6, so only one of the errored Drives is actually connected to a Splitter cable. All of the Molex - Splitter Drives (total 13 Drives) are connected to one Plug on the Power Supply. As you can see in the Picture i distributed the Hard drives across the Power Connections as best as i could. Thanks!
-
Hi, i have recently joined the Unraid Community and built my first Unraid Server with the following Components: Unraid Version 6.12.10 Asus Prime H770 Plus D4 - new Intel Core i5-12400 - new 16 GB Crucial DDR4 (2x8GB) - previously used 4x ASM1166 PCIe -> 6x SATA Cards - new Corsair RM850x Power Supply - new Boot-Stick: Transcend JetFlash 32 GB USB3 Stick connected to USB 2 header on Mainboard Cache Drives (currently not used - will change when initial copy of data is finished): 2x WD Red SN700 2TB - new Parity Drives: 2x Toshiba 20TB - new - connected to onboard SATA Array Drives: 2x Toshiba 20TB - new - connected to onboard SATA 4x WD Red Pro 6TB - previously used 8x WD Red 3TB - previously used 4x Seagate Constellation ES.2 3TB - previously used 6x Seagate Constellation ES.3 3TB - previously used All of the previously used Harddrives were running in one of multiple Synology or QNAP NAS in one of Multiple RAID 5 or RAID 6 configurations. My migration Path is as following: Start with the 4x 20TB Drives and use 2 of them as Parity, use the other 2 for the initial Array creation and copy the Data from one of my NAS to the new Unraid Server When first NAS is empty remove the drives and put them in the Unraid Server, expanding the Array after clearing and formatting Use the expanded Space to copy the data off the next NAS and so on until all Data is on the Unraid Server and all of the old NAS are shut down. This worked fine for multiple days. Today, while copying more Data, i got the Alert that "Disk 15 is in error state (disk dsbl)" and has 2048 Errors shown in the web interface. This disk was just used by Unraid for the first time since clearing and formatting and apparently had written about 2-3 GB. At the same time, 3 other Disks (all of the Seagate Constellation ES.2 3TB variety, as the failed Disk itself) thew errors too (each 1974 Errors in the web interface), but they had not been written to (yet) after formatting. I have 2 Spare 3 TB Disks (I think they are Constellation ES.3 - but i have to check) which are not installed in the Unraid Server at the moment. Currently the Disk 15 is emulated according to the Web interface, but if i click on the Icon to show the disk contents there is no Folder under /mnt/disk15 What would be the best way to continue from here? I have stopped copying data to the Array ATM, since i want to resolve the problem first before making it worse. Why are the other Disks of the same Model showing signs of Errors too if they haven't been used yet? Are the Seagate Constellation ES.2 Drives not compatible with Unraid? The questionable Drives are connected to two different ASM1166 Cards. Thanks for your advice! unraid-diagnostics-20240520-1306.zip



