

graywolf
-
Posts
675 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by graywolf
-
-
So even with the 128 Read errors on disk20 the rebuilt disk11 should be good?
What should I do about the 1 Current Pending Sector on disk20?
I'll have to get another 12TB drive for dual parity, I'll work getting another one
What would be best approach in future prior to replacing parity or data drives?
Ensure dockers don't stop
Ensure nothing writes to disks (downloads, etc)
What else?
-
Disk rebuild just finished 18hrs 35mins 35secs 128 errors
Disk11 returned to normal operation
Current diagnostics attached
Disk20 showing 1 Current Pending Sector
-
Disk11 showed error on Dashboard with 48 reallocated sectors and a bunch of raw read errors. Since I wanted to replace a 6TB with an 8TB drive I picked that one. Disk6 has 1 reallocated sector. Disk20 showed as Healthy on the Dashboard before the disk11 rebuild.
I have the original disk11, but there have been writes to the array.
-
Diagnostics attached.
So is the rebuild messed up and I need to try again?
Replaced a 6TB drive with an 8TB drive, currently 3.40 TB into the rebuild
-
I think I probably need to replace the SeaGate (Disk11) drive but unsure about the HGST (Disk6) drive.
Advice would be appreciated.
-
Another question.
If I stop the ddrescue Scraping Failed Blocks then mount the destination disk.
If I do the ddrescue fill command to find out what is corrupted, would I be able to unmount the destination disk and restart the ddrescue Scraping Failed Blocks if there are any files I still want it to try recovery?
Asking because it looks like it might be days still for the 2nd pass
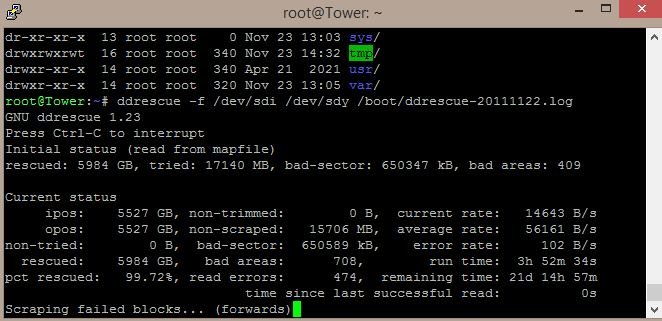
-
Once I'm done with ddrescue, it talks about being a good idea to run a file system check on the destination drive.
How do I do that for a XFS disk?
Do I mount it before the file system check or leave it unmounted?
About how long should a file system check run on a 6TB drive (if size of disk matters)?
-
Could I stop the ddrescue scraping failed blocks, then mount the destination drive to check on a couple files (and maybe copy them to another drive), then stop array, unmount the drive, and then restart ddrescue again?
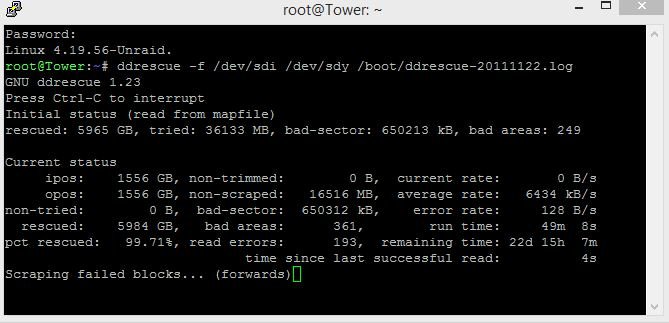
-
What should I do now at this point?
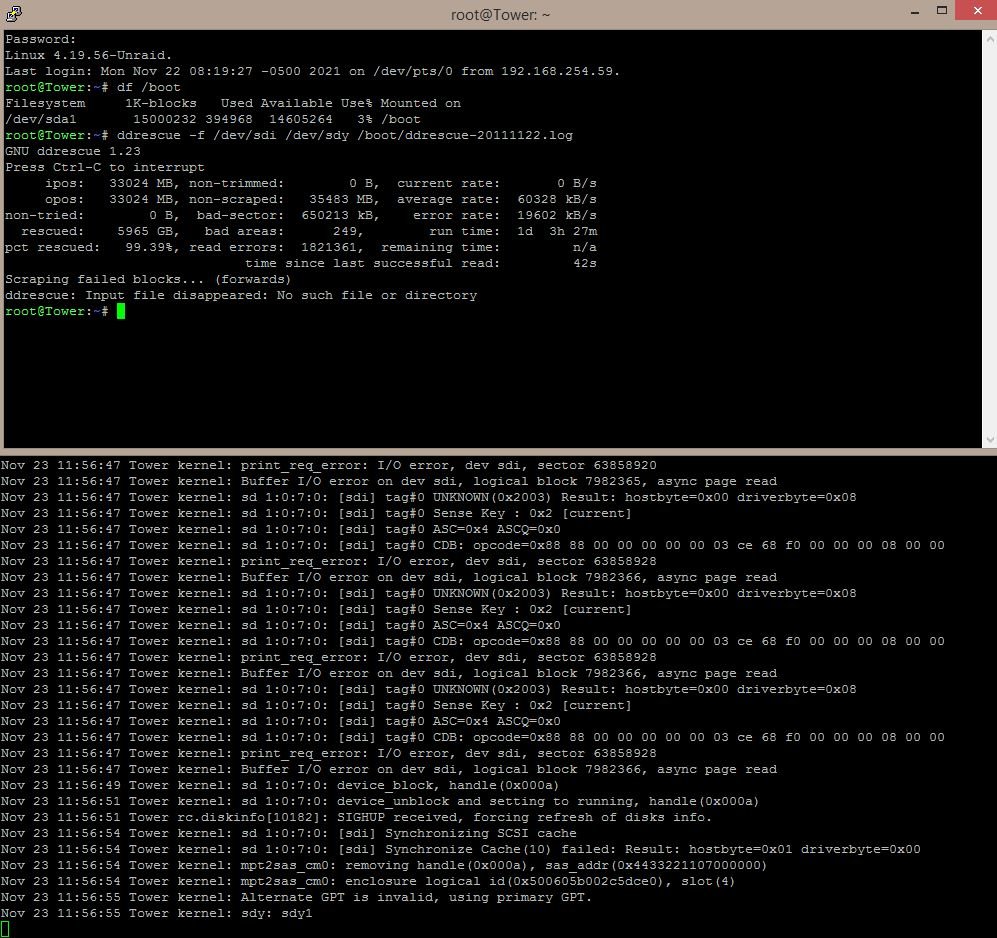
ddrescue: Input file disappeared: No such file or directory
looks like the source disk went offline?
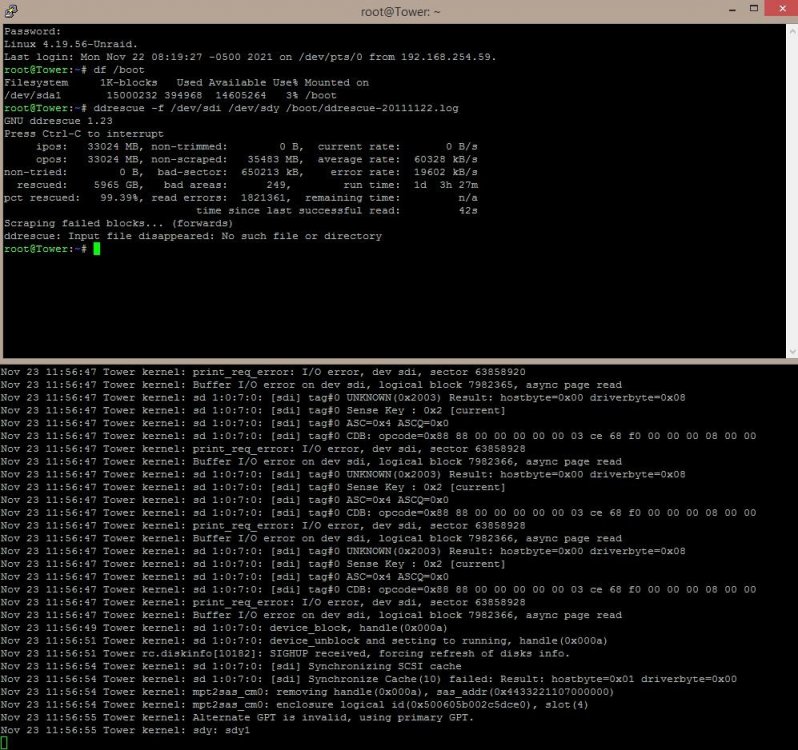
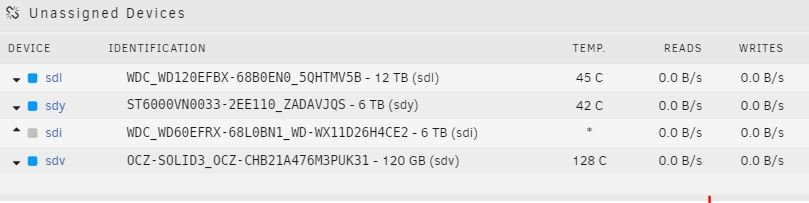
-
"ddrescue -f --fill=- ~/fill.txt /dev/sdY /boot/ddrescue.log"
What if a bad sector did not have any file(s)? does it create a file and fill it with the text?
-
I read that after ddrescue completes it's thing that "After the clone is complete you can mount the destination disk manually"
What would be the command to do that? I don't have UD plugin installed
And would mounting the disk be the same as adding it to the array? (no parity currently)
-
Interesting. Just to clarify, if a video file did play, the visible corruption would be because of the bad blocks anyways and not the addition of the text from the ddrescue fill cmd? Otherwise, is there another method other than adding the text with the ddrescue --fill to correlate the bad blocks with the files?
-
so "ddrescue -f --fill=- ~/fill.txt /dev/sdY /boot/ddrescue.log" will add the text inside the file that has bad blocks but if I understand correctly, that shouldn't matter for any type of file (txt, pdf, jpg, mkv, etc) since that file is corrupted anyways and would not open/play correctly. Is that correct?
-
I set it up last month, prior to Nov 6th Parity Check which ran without issue.
Never saw anything for Disk18 until the Parity-Resync when I tried to replace the Parity drive with a larger drive.
Unfortunately stuff had written to the array during that process so the old parity drive wouldn't be usable.
-
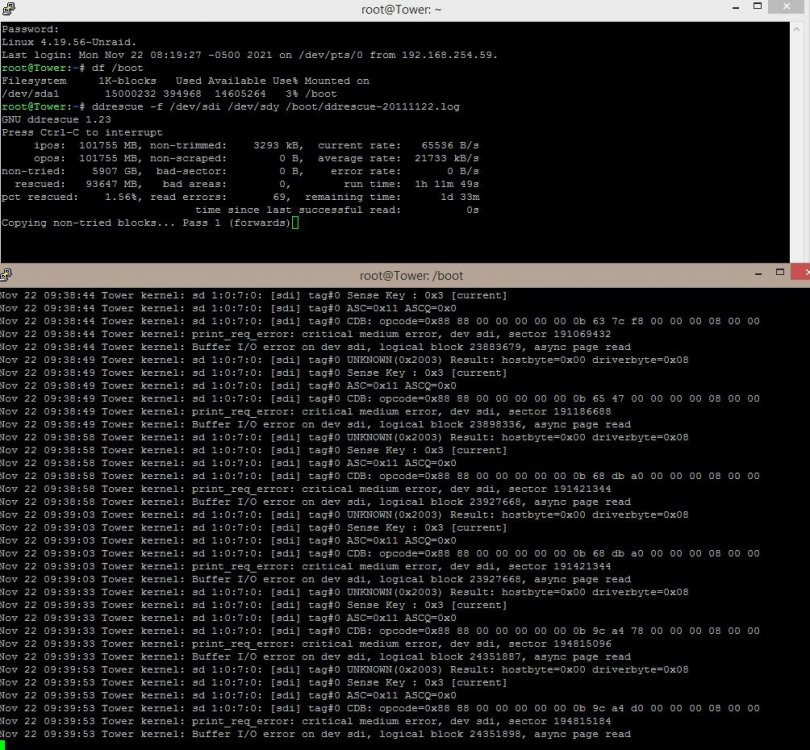
Running ddrescue.
is there a good link that tells me what the different labels mean?
Some are obvious but others not.
i.e. non-trimmed = space that is bad during 1st pass? But that doesn't seem to match what I get when I subtract the rescued ammount from the opos number. Also, Bad Sectors and Bad Areas and Error rate are 0 but have 76 read errors.
-
There were writes unfortunately. So running without parity.
I have never used ddrescue and don't want to screw up more.
It says that "Both source and destination disks can't be mounted"
So what is the best way to unmount disk18?
With disk18 unmounted, can the rest of the array be running?
Does the destination drive (precleared) need to be formatted first?
-
Disk18 (sdg) is getting tons of these. Happened when trying to put in a larger parity drive.
that didn't work and other disks were written to so the old parity drive isn't good.
Any way to pull data from the drive or identify what isn't recoverable? -
Did power down, then restarted server. Since no parity, I put in a new drive and am trying to copy the contents of Disk18 to Disk23 (unBalance Copy) now to see what I can get. Still getting read errors from disk18.
Attaching current diagnostics file
any help/advice would be greatly appreciated
or if there is a better/faster process than unBalance Copy to transfer what I can from disk18 to disk23
-
Additional info.
It looks like a smart report was not available for Disk18 in the Diagnostics.
Tried doing it individually and got the attached which said: Smartctl open device: /dev/sdu failed: No such device
Also noticed that it looks like /var/log is at 100%
Quoteroot@Tower:/var/log# df
Filesystem 1K-blocks Used Available Use% Mounted on
rootfs 8158744 669184 7489560 9% /
tmpfs 32768 408 32360 2% /run
devtmpfs 8158760 0 8158760 0% /dev
tmpfs 8210092 0 8210092 0% /dev/shm
cgroup_root 8192 0 8192 0% /sys/fs/cgroup
tmpfs 131072 131072 0 100% /var/log
/dev/sda1 15000232 393904 14606328 3% /boot
/dev/loop0 8832 8832 0 100% /lib/modules
/dev/loop1 6016 6016 0 100% /lib/firmware
/dev/md1 5858435620 5370817808 487617812 92% /mnt/disk1
/dev/md2 5858435620 5389663876 468771744 92% /mnt/disk2
/dev/md3 5858435620 5383870316 474565304 92% /mnt/disk3
/dev/md4 5858435620 5399408132 459027488 93% /mnt/disk4
/dev/md5 7811939620 7327696028 484243592 94% /mnt/disk5
/dev/md6 5858435620 5372153508 486282112 92% /mnt/disk6
/dev/md7 5858435620 5375539600 482896020 92% /mnt/disk7
/dev/md8 5858435620 5370944128 487491492 92% /mnt/disk8
/dev/md9 5858435620 5371322200 487113420 92% /mnt/disk9
/dev/md10 5858435620 5373463284 484972336 92% /mnt/disk10
/dev/md11 5858435620 5370387596 488048024 92% /mnt/disk11
/dev/md12 5858435620 5376001688 482433932 92% /mnt/disk12
/dev/md13 5858435620 5408146252 450289368 93% /mnt/disk13
/dev/md14 5858435620 5373271592 485164028 92% /mnt/disk14
/dev/md15 5858435620 5371518072 486917548 92% /mnt/disk15
/dev/md16 5858435620 5312117804 546317816 91% /mnt/disk16
/dev/md17 5858435620 5310747332 547688288 91% /mnt/disk17
/dev/md18 5858435620 5335694900 522740720 92% /mnt/disk18
/dev/md19 7811939620 6899110408 912829212 89% /mnt/disk19
/dev/md20 5858435620 4946753272 911682348 85% /mnt/disk20
/dev/md21 5858435620 5187500852 670934768 89% /mnt/disk21
/dev/md22 5858435620 4941532744 916902876 85% /mnt/disk22
/dev/sdv1 117220792 16768 116158592 1% /mnt/cache
shfs 132792591640 120567661392 12224930248 91% /mnt/user0
shfs 132909812432 120567678160 12341088840 91% /mnt/user
/dev/loop2 41943040 2876936 37220056 8% /var/lib/docker
-
Was replacing Parity drive with a larger drive. Last Parity Check (11/6/2021) was good without errors.
Got messages that Disk18 (6TB) has tons of Read Errors and 6 Pending Sector errors.
Parity-Sync is still running (past 6TB)
I assume that the Parity-Sync is invalid?
Advice on how best to proceed?
-
On 6/20/2018 at 4:20 AM, flokason said:
Last Wednesday (13th of june) I noticed that my shows weren't automatically showing up in Plex
So I checked the SABnzbd and saw this error:
So the show is downloading, but it is not moving from the download file to the final destination
Everything should be uptodate at my serverUnraid 6.5.3
c/p from sickrage:
SickRage Info:
According to the Docker section in unraid, everything is up-to-date
I did not make any changes to the server what so ever, except I allow all the auto updating, both of the docker and unraid OS
Anyone else has this problem?
I'm having the same thing happen to me. Downloads but fails in post-processing.
I have touch the config settings for sabnzb or sickrage in ages.
-
Just got back home.
Red Ball - Drive 14 - Advice?
The SMART looks fine (I think)
What actions should I take?
Diagnostics file attached
tower-diagnostics-20180617-0909.zip
Looks like it occurred around Jun 13 04:37:37
-
1 hour ago, John_M said:
On the face of it "critical medium error" seems to suggest that disk14 has failed but, looking at its SMART report, it seems ok. The SMART does indicate a recent issue but it's more consistent with a failure to communicate with the host. The output from your HBA is too cryptic for me to decipher but what I would do is shut down and check/replace the cable or move to a different backplane slot and run an extended SMART test.
Thanks John_M.
Shut down
Checked cables
Start up
Running extended SMART test
We'll see how it goes (fingers crossed)
-





Can I upgrade from 6.7.2 to 6.12.8 directly? Any gotchas?
in General Support
Posted
I know I am far behind the times with upgrading unRaid. Anything I should be aware of in doing the upgrade?
Advice on best method to perform upgrade and what to do in order to perform backout if it goes wrong?
How long would an upgrade take?
Is the GO file still valid for setting up aliases and creating a tmp file to update crontab to run scripts (i.e. crontab /tmp/file)
Have array stopped before upgrading?
Any other tips to help it go smoothly?