




Kai3D
Members
-
Joined
-
Last visited
-
When I reboot my server some of the disks become unavailable. This has happend since the beginning. the only way for me to get the disks back is to shutdown the server, wait a few seconds (or minutes in case of the diagnostics) and start the server by pushing the power button. It is not a big inconvenience but slightly annoying and I fear that at one point it might cause some data loss, when fore example the array is able to start due to only one (ore two) missing drives. the before reboot diagnostics are before the second reboot (shutdown, wait, power-up) and the after diagnostics after that. Is there a way to slow down the reboot to keep this from happening, a BIOS setting or anything else I can do? After Reboot.zip Before Reboot.zip
-
Here is the command output. root@Speicher:~# ls -lah /mnt total 16K drwxr-xr-x 16 root root 320 Jan 9 16:13 ./ drwxr-xr-x 20 root root 420 Jan 9 16:19 ../ drwxrwxrwt 2 nobody users 40 Jan 8 23:30 addons/ drwxrwxrwx 1 nobody users 46 Jan 9 04:40 cache/ drwxrwxrwx 9 nobody users 161 Jan 9 15:59 disk1/ drwxrwxrwx 6 nobody users 91 Jan 9 04:40 disk2/ drwxrwxrwx 6 nobody users 91 Jan 9 04:40 disk3/ drwxrwxrwx 4 nobody users 47 Jan 9 04:40 disk4/ drwxrwxrwx 4 nobody users 46 Jan 9 04:40 disk5/ drwxrwxrwx 4 nobody users 47 Jan 9 04:40 disk6/ drwxrwxrwx 7 nobody users 115 Jan 9 04:40 disk7/ drwxrwxrwt 2 nobody users 40 Jan 8 23:30 disks/ drwxrwxrwt 2 nobody users 40 Jan 8 23:30 remotes/ drwxrwxrwt 2 nobody users 40 Jan 8 23:30 rootshare/ drwxrwxrwx 1 nobody users 161 Jan 9 15:59 user/ drwxrwxrwx 1 nobody users 161 Jan 9 15:59 user0/While deleting the lost + found I managed to disable all disks except disk1 from all shares. Now everything appears to be back.
-
After doing a file system repair I have gotten back the files from the original folder, but some new files have gone missing in the share. The repair moved some jellyfin metadata into the lost + found which I deleted because they can be regenerated easily. The files in the Dump folder have been uploaded after the mentioned reboot after which the first files went missing (I didn't notice yet). I can copy them over again but I feel still unsure about other files being there. speicher-diagnostics-20260109-1618.zip
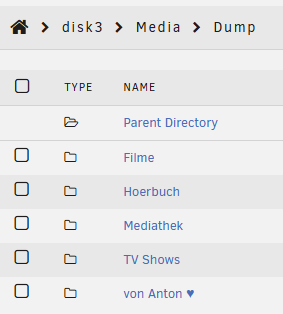
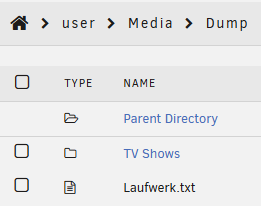
-
I now usually shutdown the server and boot it again after about 2-5 min when I need to reboot. the drives affected vary but include both expander and mainboard SATA ports. I will do another reboot soon just to get the diagnostics. until than only the missing folder is relevant as I don't think they are related.
-
Here is the output of that command: root@Speicher:~# ls -lah /mnt total 16K drwxr-xr-x 16 root root 320 Jan 8 23:31 ./ drwxr-xr-x 20 root root 420 Jan 8 23:37 ../ drwxrwxrwt 2 nobody users 40 Jan 8 23:30 addons/ drwxrwxrwx 1 nobody users 46 Jan 9 04:40 cache/ drwxrwxrwx 9 nobody users 161 Jan 9 04:40 disk1/ drwxrwxrwx 6 nobody users 91 Jan 9 04:40 disk2/ drwxrwxrwx 6 nobody users 91 Jan 9 04:40 disk3/ drwxrwxrwx 4 nobody users 47 Jan 9 04:40 disk4/ drwxrwxrwx 4 nobody users 46 Jan 9 04:40 disk5/ drwxrwxrwx 4 nobody users 47 Jan 9 04:40 disk6/ drwxrwxrwx 7 nobody users 115 Jan 9 04:40 disk7/ drwxrwxrwt 2 nobody users 40 Jan 8 23:30 disks/ drwxrwxrwt 2 nobody users 40 Jan 8 23:30 remotes/ drwxrwxrwt 2 nobody users 40 Jan 8 23:30 rootshare/ drwxrwxrwx 1 nobody users 161 Jan 9 04:40 user/ drwxrwxrwx 1 nobody users 161 Jan 9 04:40 user0/
-
Every time I reboot my server at least one of my hard drives is not recognized by UnRaid. When booting after a short time in which the server was turned off they get recognized. I'm running a combination of onboard SATA and a SATA expander to attach nine hard drives. How would I go about troubleshooting this behaviour? speicher-diagnostics-20260108-2337.zip
-
Recently I had the issue that all my shares where gone. Doing a quick google research revealed that a reboot might fix the problem and it seemingly did. Now a couple of days later I have found a folder that is empty in the share but has data in it when exploring the disk. In the parent directory in the share it shows 5 disks as being used. As I currently have about 20 TB of data on the Server I am unable to check for more missing folders. Here are some screenshots: How do I get my files back into the shares? speicher-diagnostics-20260108-2337.zip
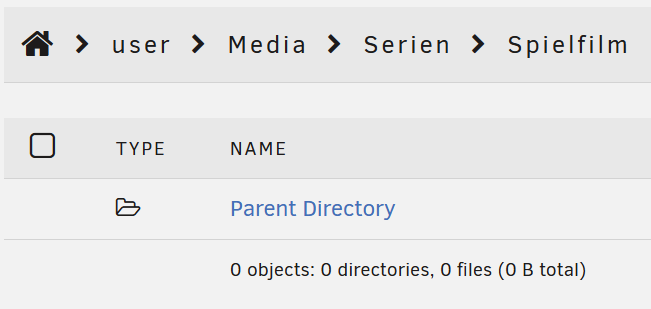
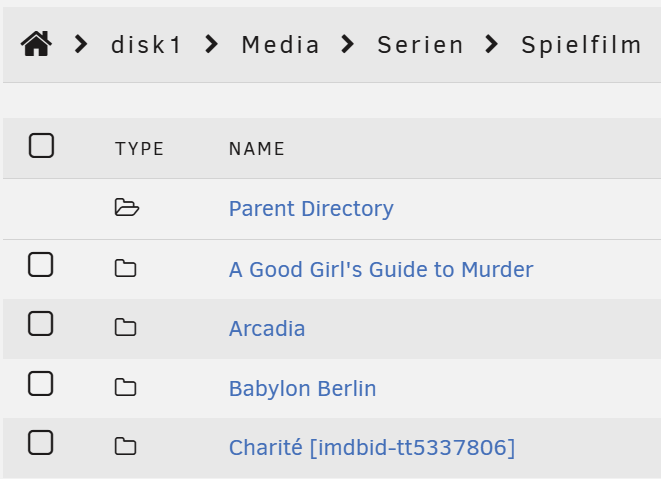
-
Don't forget to forward the UDP port of your Wireguard container
-
The extra parameters did the trick. Tank you. As you have suggested and therefore guessed correctly I am migrating from a Pi running Portainer and docker compose. With that setup it is quite easy to get everything running as I want to but I don't think having a Pi running just wireguard is worth it (also I need the Pi for 39C3).
-
First of all, I know that there is an integrated Version of Wireguard inside of unRAID. Yet there are arguments for different versions. I want to use the WG-Easy Container as I have used it before and it has a really nice and quick way of setting up clients including QR-Codes for phones. Also it lets me import my old WG-easy config from my Pi4. In case you don't know WG-Easy it is a GUI for Wireguard https://wg-easy.github.io/wg-easy/latest Now to my issue: I managed to get the container to run inside of unRAID docker but I have some issues regarding the network connectivity. [unhandledRejection] Error: WireGuard exited with the error: Cannot find device "wg0" This usually means that your host's kernel does not support WireGuard! at file:///app/server/chunks/nitro/nitro.mjs:5823:15 at process.processTicksAndRejections (node:internal/process/task_queues:105:5) at async WireGuard.Startup (file:///app/server/chunks/nitro/nitro.mjs:5821:5) { [cause]: 'Command failed: wg-quick up wg0\n' + '[#] ip link add dev wg0 type wireguard\n' + 'RTNETLINK answers: Operation not permitted\n' + 'Unable to access interface: Operation not permitted\n' + '[#] ip link delete dev wg0\n' + 'Cannot find device "wg0"\n' } Migrating database... ==================================================== wg-easy - https://github.com/wg-easy/wg-easy ==================================================== | wg-easy: v15.1.0 | | Node: v22.17.0 | | Platform: linux | | Arch: x64 | ==================================================== Migration complete Starting WireGuard... Starting Wireguard Interface wg0... Saving Config... Listening on http://0.0.0.0:51821 Config saved successfully. $ wg-quick down wg0 $ wg-quick up wg0Based on the error you can see that the network connection fails at the moment due to the inability to access wg0 as network adapter. There is a wg0 docker network but no Linux system network adapter. Can you help me with fixing this issue. I think it could be something like passing a network device from /sys/class/net/ (?) to the container. PS: I know that this topic is more related to Docker Containers than General Support but as I'm not a verified developer I cannot post in the forum. Feel free to move this topic to where it fits best.
-
I have mounted the disabled disk (the one time it was a data disk) separat from the array and all data was available. The same happend the one time I had to fix the file system on one of my disks. Data available but I'm unable to enable the disk and check its contents against the parity. A full disk write instead of a read was required to stop the data from being emulated. Also related but on a different note, will a parity check with "Write corrections to parity" enabled fix a disabled disk or do I have to remove the disk from array and re add it in order to rebuild. PS: I think I will buy a different HBA card as my current one only runs at 1.5G instead of 6G speed. The reliability also might benefit from this.
-
As the problem is intermittent , checking if the problem persists is not feasible (error frequency so far about 4 weeks in between). As I have access to the drive immediately after it becomes disabled, I'm starting to question if the cables could cause this error. All drives are mounted decoupled and the case has not been touched since at least 3 weeks (up time). For the time being, is there anything other than a full rebuild that i can do to fix the issue, specially when a data drive is affected?
-
There are 2 x Molex to 4 SATA cables in use. The crimped plug type not the over molding. Therefore I believe the power is highly unlikely to be the issue.
-
I have recently setup my first Unraid server with 9 (2 parity) array drives and 2 cache drives. Since I did so Less than two month ago I had drives being disable on three occasions. One time both parity drives were disabled the exact same moment and one time a data drive was disabled (although the content was still accessible when mounting it outside the array). Now one of the parity drives is disabled. I am of cause slightly annoyed by this because the only fix I found so far is to remove the disk from the array and rebuild onto itself. This takes about 40 h and uses a lot more energy than the server is already using (50W idle is quite high when considering German power prices). Is there a better way to fix this or a way to prevent it in the first place? speicher-diagnostics-20250907-1806.zip




