




mdoom
Members
-
Joined
-
Last visited
-
Sort of a two part question here... I'm using this plex docker on unraid. Latest versions of everything. So, whenever I have large movies added to my Media folder and Plex finds it, it seems to fully lock up Plex for awhile until it is done importing it. I've dealt with this for way longer than I care to admit... but in searching this forum I found some recommendations to others with similar issues, that i should make sure appdata path in the docker is set to /mnt/cache/ instead of /mnt/user. And sure enough, I checked and I currently am setup with /mnt/user. So my first question, since appdata share is set to cache only, what impact does this really have? Second question, I tried updating this from /mnt/user/ to be /mnt/cache/ and now plex won't start and continuously crashed. Getting a "unraid failed to create uuid file" errors over and over. It says it keeps outputting crash reports too, but when checking the folder in appdata for crash reports, nothing new is there. I deleted and re created the image as well to just try that. No luck. For now I switched back to /mnt/user since it 'works'. I welcome any advice though
-
Hey, I just recently started using this specific container, and having an issue that I'm hoping someone can point me in the right direction. My goal: Use Nvidia GPU in the docker with OpenCL. I've setup my docker appropriately to pass in the GPU UID and all that, and confirmed that the docker itself has visibility to the GPU. (confirmed with nvidia-smi) However when running a project that has tasks that expect Nvidia OpenCL processing, (i'm running Primegrid in particular) I'm getting computational errors. When I check stderrgpudetect.txt file, I'm seeing: "beignet-opencl-icd: no supported GPU found, this is probably the wrong opencl-icd package for this hardware" Which, tells me its trying to use Intel OpenCL. Is there something additional that would need to be installed to use Nvidia? Any guidance is greatly appreciated.
-
So, now that I'm home and able to better play with it.. I wanted to provide an update. First and foremost, I apologize, turns out, I wasn't even using linuxserver container. I thought I had switched everything to linuxserver, however i still was running a version by needo, which apparently hasn't been updated in a very long time. I switched to linuxserver, mono is on 5.10 and all is well!
-
Thats good to know, I did do a "check for updates" this morning before I left home and said no updates for the container at all. I'll just purge my image tonight after work and grab a fresh copy. I'm re-assured that you said it'll pull latest version. The odd part is I know I have re-setup Sonarr before (new container) many times since 3.10 Mono has been out, but oh well. Hopefully if anyone else having same problem they can be helped by this too!
-
Good question. I guess I don't know for sure, but I know mine currently has 3.10. I'm away from home currently, but I will try a clean install of the container to see what happens. It may just be that since it pulls the latest when its installed, that then it never gets updated over time without an explicit update in the container.
-
I was curious how to go about upgrading the version of Mono in this docker? There has been a bug with Mono 3.10 that is preventing nzb's from successfully being grabbed. details found at: https://forums.sonarr.tv/t/xmlexception-syntax-error/18599/11 So far the solution of upgrading Mono has been working for others. I'm just not sure what to do for the docker version.
-
Agreed. Truly safest option. Thanks again!
-
Well @johnnie.black, thank you very much!! That executed successfully, i restarted array (still in emulation mode for the disk) and it comes up perfectly now. I'll probably go ahead and move all data off to other drives and then rebuild back to original drive as 'empty'. Or i'll just rebuild now back to it. Either way, I think I'm good now more or less.
-
restarted array in maintenance mode, tried command, got this fun warning. Wanted to double check before I did anything else. Should I proceed with adding -L flag?
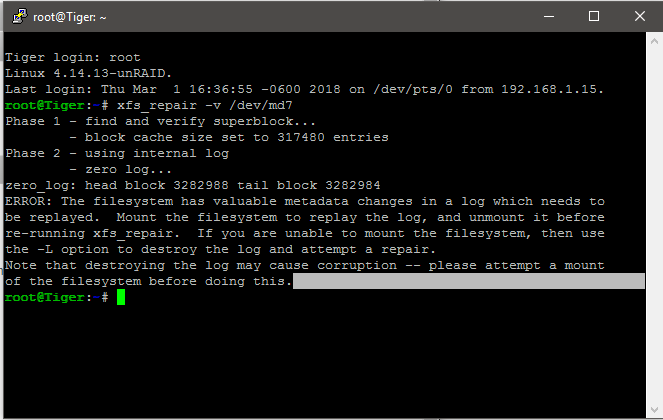
-
It was mounted. Oops! I unmounted and stopped/started again and still says it again, but it isn't mounted in UD. Here is latest Diagnostics. tiger-diagnostics-20180301-1742.zip
-
So I did go ahead and just start array with it emulating that disk. However it still shows as "Unmountable: No file system" for Disk 7, even when its emulating.
-
Its been in my array for over two years. Its a basically full 8 TB drive. Haven't had any issues at all with it. Just after the power outage yesterday that led to unclean shutdown (apparently my UPS backup is dead too...) , it now shows up as unmountable when the array starts. If it comes to rebuilding the filesystem, I guess I dont entirely know what that all entails.
-
With array stopped, (this is drive in disk 7 spot), I change drop-down from the hard drive to "no" for disk 7, and then in the GUI under "Unassigned Devices" I am able to click "Mount". Then via terminal I just was navigating to /mnt/disks/.... etc. and can browse all data without issue.
-
Good call. :-) Thank you! I just added it.
-
So, had some crazy events yesterday. Long story short, had an unclean shutdown of my unraid. Last night I quickly got it back up and running but just enough to click start and go, didn't pay much attention to anything. This morning I noticed it was doing Parity check, which is expected after unclean shutdown, but then noticed that one of my data drives in my array said "Unmountable: No file system". Now I'm home from work today and trying to fix this. I've searched forums a decent amount, and see several had similiar issues specific to cache drives in upgrading to 6.4 release candidates, but I'm on full 6.4 version, and it is a data drive. When I stop the array, I am able to mount the drive and explore it and see all my data via a terminal. But even after that, starting it back up in the array still gives same error. I'm just looking for guidance on next steps to try to correct it so I can get everything working. I thought about maybe trying New Config, but wasn't sure if that'd do it or not. I also wasn't sure what state my parity was in since it ran over night doing parity check before I cancelled it while one drive was in this state. I am running a dual parity setup as well. I haven't yet, but I also thought about starting array just with the drive "missing" to test if i could see all of the data via parity. Thank you in advance EDIT: added Diagnostics zip tiger-diagnostics-20180301-1657.zip
