jmcskis
Members
-
Joined
-
Last visited
-
Thanks. Resetting the docker seemed to have fixed it.
-
I recently started getting a "bad parameter" execution error when I try to start the docker. I did recently update to 7.2.5 so don't know if it's maybe an issue with the latest stable release? I have the docker routed through binhex-delugevpn (I think I followed spaceinvader's video when I originally set it up), but it hasn't given me issues in the past. tower-diagnostics-20260507-1829.zip

-
Thanks. Looks like everything is back to normal.
-
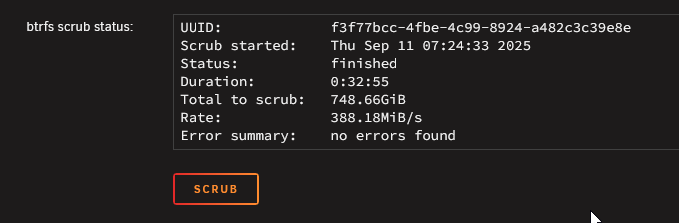
I double-checked the SATA cables and didn't get any errors when I rebooted. Ran another scrub, and didn't find any errors. Looks like I just need to re-create the docker .img is all I need to do?
-
I think I've worked out that at least part of the file system on my cache pool is corrupted, and I need to reformat and restore from a backup. Before I go down that path, though, I want to confirm with the community that my thinking is correct and I haven't missed anything else. What Happened: A few days ago, I performed a safe shutdown for some routine maintenance (just removing dust and stuff, no hardware changes). When I booted back up, everything seemed normal until the system started throwing a bunch of BTRFS errors and I/O errors. I wasn't able to grab the diagnostics before I shutdown, but did grab the syslog syslog-20250908-1352.txt When I saw the errors, I performed a clean shutdown, rebooted into safe mode, and ran diagnostics tower-diagnostics-20250908-2032.zipand was seeing different BTRFS errors this time. Based on what I could find on other threads related to BTRFS errors, I ran a scrub of the cache pool, which ran with ~6000 corrected errors and no failed errors, but no other issues with the scrub as far as I can tell. Thinking that had fixed the problem, I performed a clean shutdown, confirmed all hardware connections were secure, and rebooted as normal. After booting up, only part of my dockers started and the others can't be started. The syslog is showing a handful of BTRFS errors still, which I'm understanding to be corruption errors based on the diagnostics after the latest reboot tower-diagnostics-20250908-2225.zip Hoping this can be fixed with a reformat and restore.
-
Thanks, @JorgeB. Looks like things are back up and running.
-
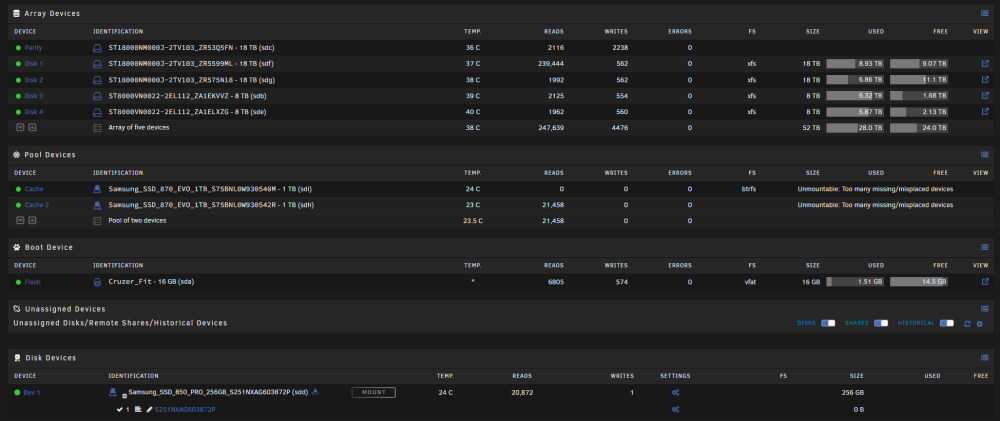
Right, I knew there were some corrupts, which was part of my reason for swapping out drives. Given the corrupts should I have recreated the pool from the start instead of trying to replace drives? Just to make sure I've got my steps right for recreating the pool: Copied the data I could to the array (I did copy my docker.img but I know it's better to just recreate the .img file) Backed up appdata using CA Backup Disable docker Set all shares to not use cache Run mover From here I'm a bit unclear on the correct steps to follow, but think the process would be: stop the array unassign all pool devices restart the array stop the array set pool slots to 0 (trying to completely remove cache) restart array stop array set pool slots to 2 assign new drives to pool (sdh and sdi) restart the array format new drives to create new btrfs cache pool restore appdata recreate docker.img and restore dockers from templates copy any data back onto cache, as required
-
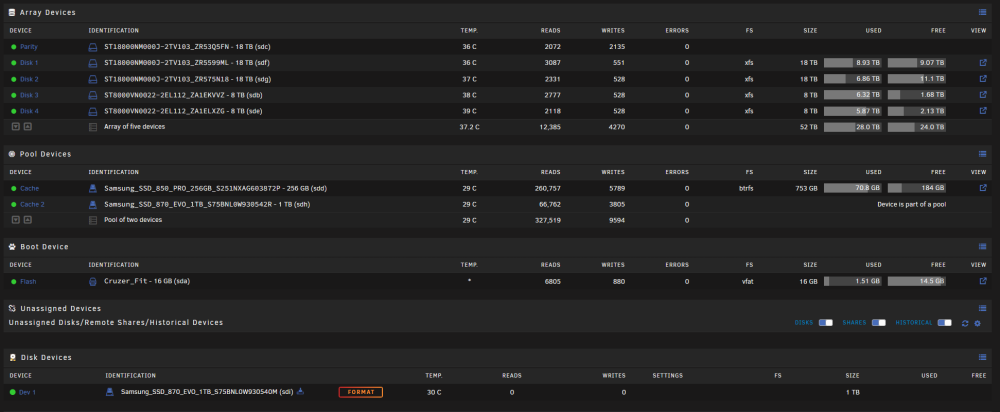
That appears to have done the trick. Although I think it's still expecting there should be 3 drives? New diags attached tower-diagnostics-20231216-0847.zip
-
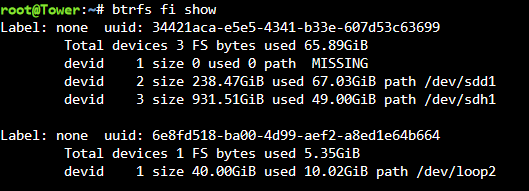
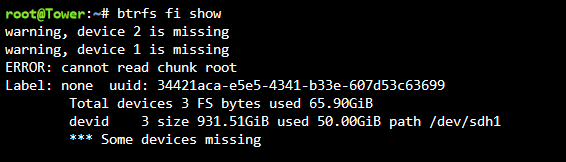
It seems to be expecting that I have 3 drives in the cache pool even though I never changed from a 2 drive pool. Is this suggesting that it's expecting /dev/sdd (currently unassigned) to be included as a 3rd drive in the pool?
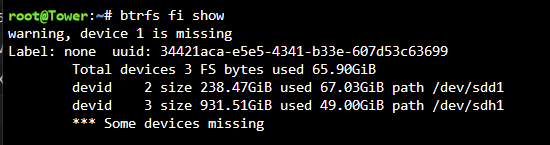
-
And that gives: sdd is unassigned and one of my old cache drives. sdh is the other new cache drive.
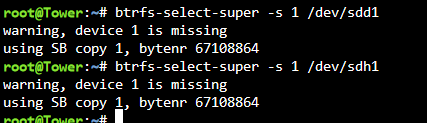
-
Here's what that gives me:

-
Looks like it can't find the drives?
-
I have a 2 drive cache pool and was trying to swap out both drives with new larger drives following this procedure: I missed the last step about stopping and restarting the array if I had replaced with a larger drive after the btrfs replace appeared to complete for the first drive. Instead I stopped the array and repeated the process to swap in the other new device. After I thought the btrfs replace process was complete for the second drive I was getting a "Unmountable: Invalid pool config" error. I stopped the array and swapped the old drive back into the cache pool hoping this would go back to what I thought was a working pool after the first disk swap. This gave me the same error again, so I stopped the array and swapped back to the new drive and restarted the array with the same error. I then rebooted the server and started the array. Now I'm getting an "UNMOUNTABLE: TOO MANY MISSING/MISPLACED DEVICES" error for the cache pool with the 2 new drives installed and I'm being told I need to format the drives. Unfortunately I forgot to grab my diagnostics before rebooting, but have included the diagnostics following the reboot. Is there any way to recover the data from the old cache pool configuration? I ran mover before swapping discs so I think my docker image and appdata should be the only info saved to the cache pool. If I can't recover the old data, what is the correct procedure to get my cache pool back up and running? tower-diagnostics-20231213-1931.zip
-
Yep. I called things quits right there until I could replace it.
-
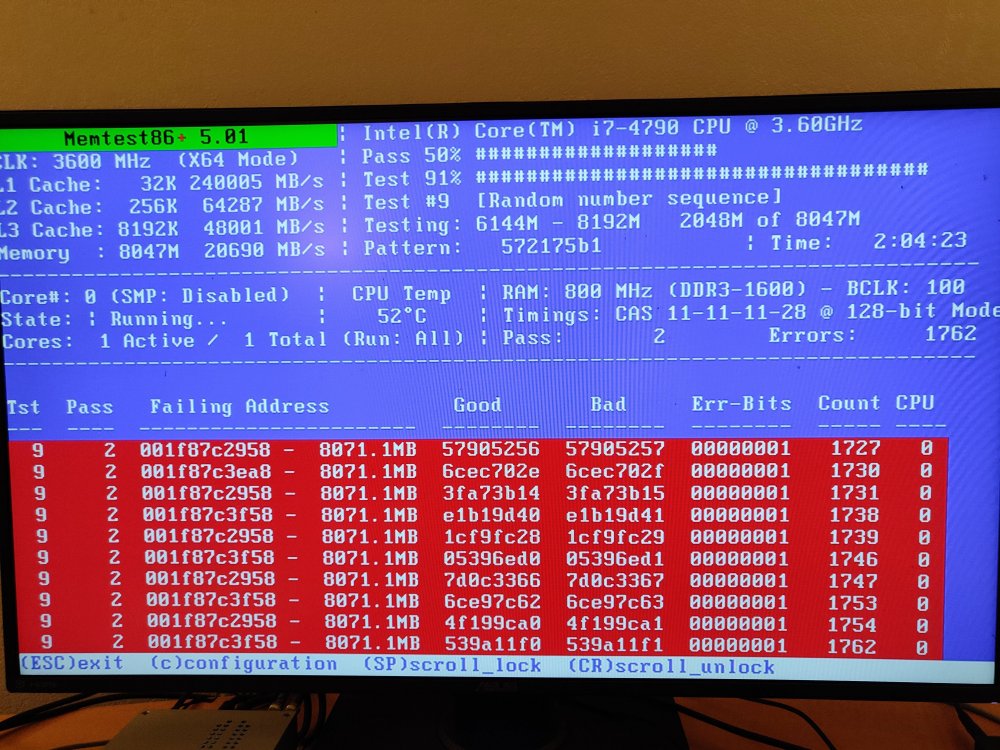
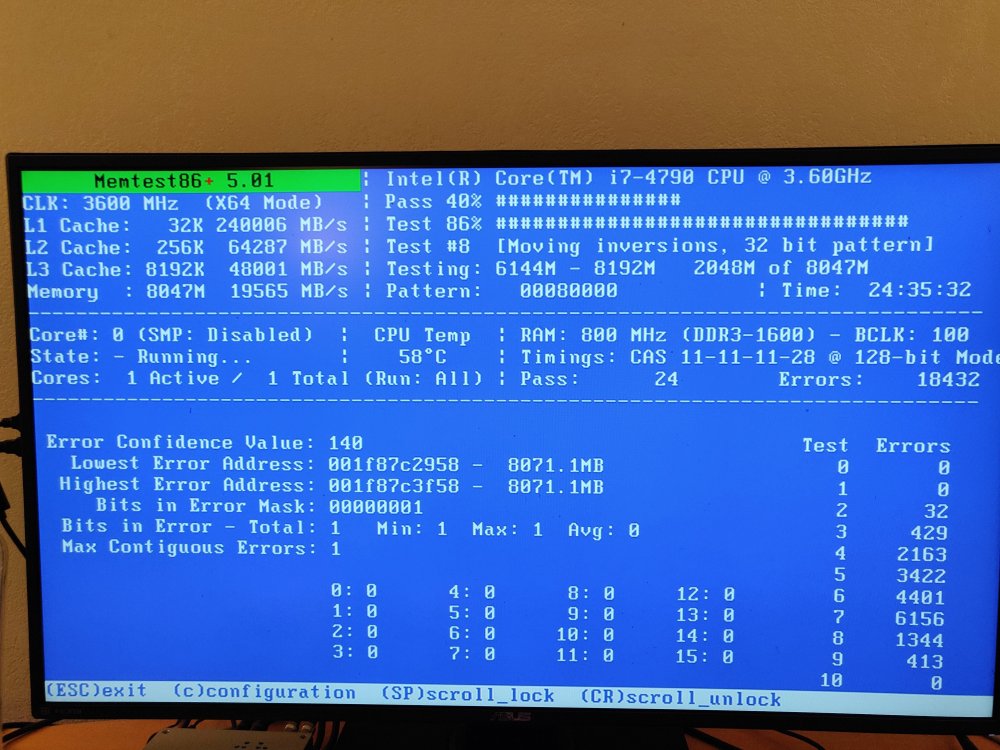
Thanks. After forcing a reboot, I was able to get the parity rebuilt and moved on to replacing data drives. Same thing again, everything froze up partway through, forced a reboot, got the drive replaced fine. Moved on to preclear my next drive and what do you know...things freeze up again. Ok, time to check everything. Did the usual checks of all my connections, ran a check on the flash, etc. After searching a bit more, it seems like my RAM could be at fault so I ran a memtest and oh boy. Given that I'm getting 1000's of errors, I'm guessing that I found my issue... I did pull diagnostics before my server hung up on me the last time. Not sure if there's anything in there that would tell me I have failing RAM. tower-diagnostics-20220216-1250.zip