

Rudder2
-
Posts
157 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by Rudder2
-
-
I agree also.
Googled this problem and this post popped up.
Here is another couple of post that looks to be the same problem.
-
15 hours ago, SimonF said:
My issue is not the same but may be from the bug see here https://forums.unraid.net/bug-reports/prereleases/disk-spin-up-r1174/page/2/?tab=comments#comment-17670
From reading there it looks possible the same issue but just every SAS drive in my array is creating a DEV a pond spin-down.
-
I have no idea if this is a plugin problem or an unRAID problem is why I'm putting it in general support.
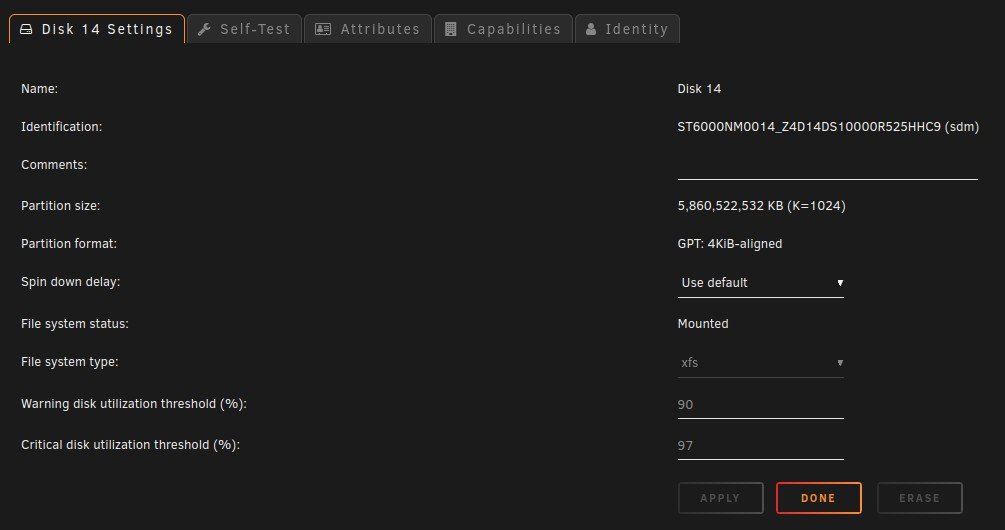
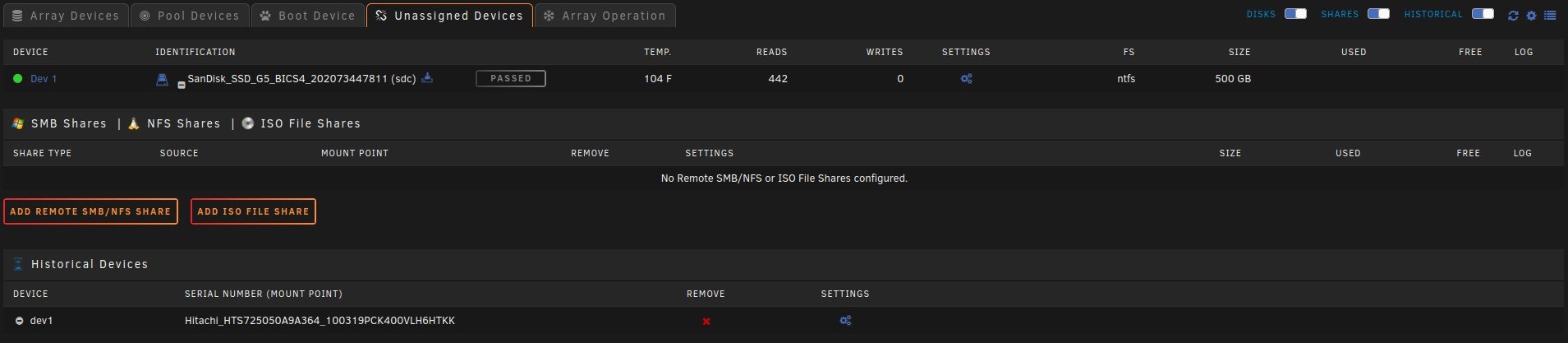
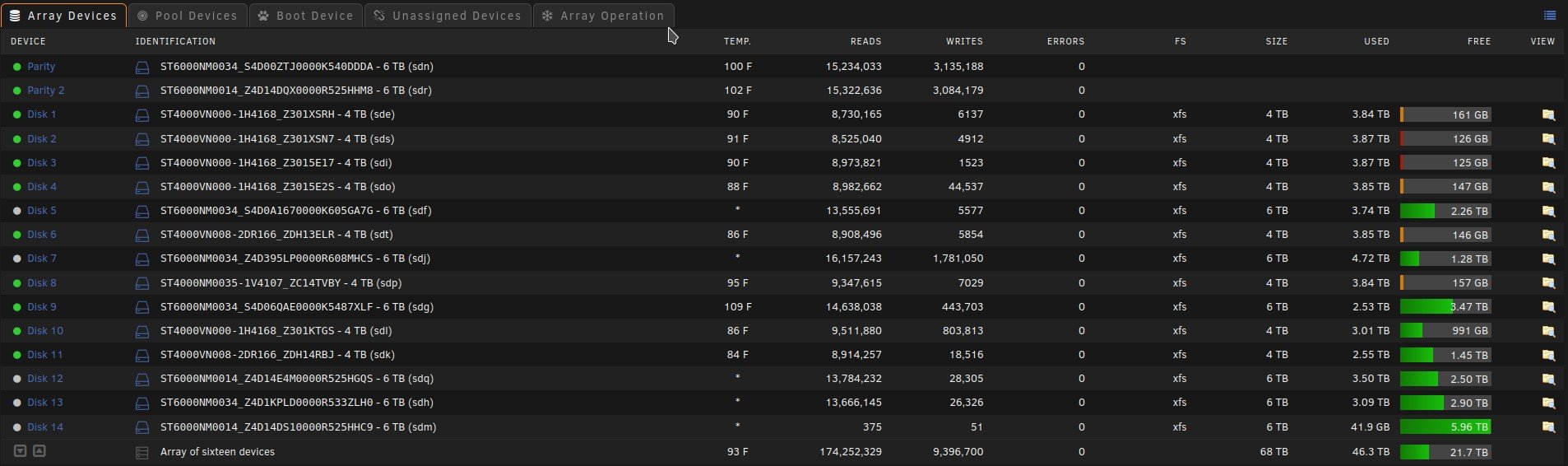
I have no idea when this started and what changed...It might of been when I moved from the old Preclear Disk plugin to the Unassigned Devices Preclear plugin. When a SAS drive spins down it is no longer controlled by the Main spinup/down by clicking the ball. Also the disk will perpetually be displayed as in standby even when it is spun back up by the server and a new Dev is added to unassigned devices Dashboard section in order of spindown where you can see the spun up and down, temp, and SMART status. The array works normally with out error. When rebooted it returns to normal till the SAS drives eventually spin down. The order of Dev2-Dev6 is the order that the SAS drives spun down. This only happens to my SAS drives and like I said before my array works normally with out error.
Here are some pictures and my diagnostics:
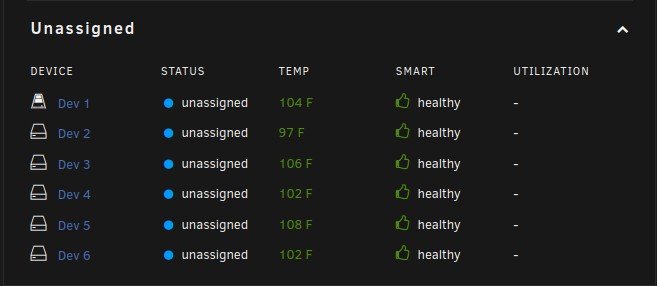
Dev2 - Dev6 are my SAS drives in my array in the order that they spundown.
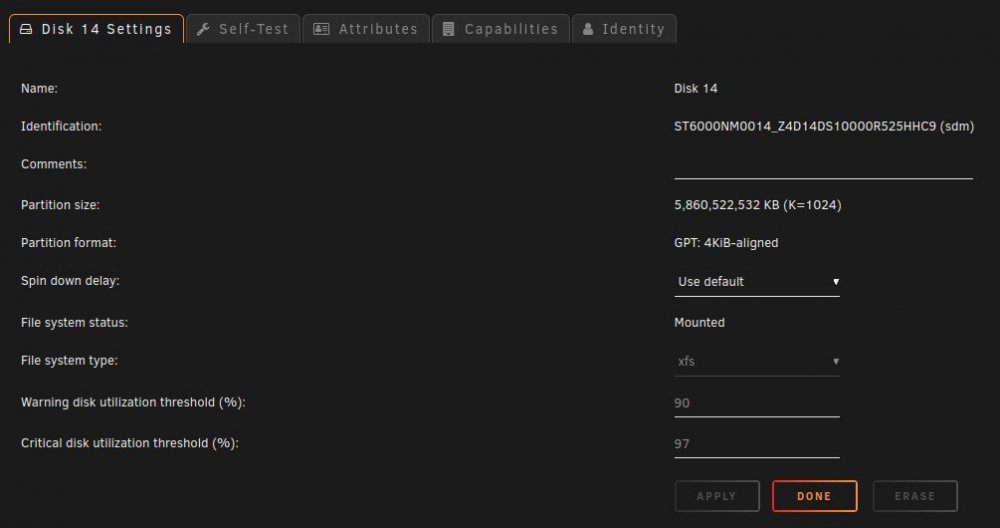
Disk 14 is a SAS Data Disk and it's the Same as Dev 2 under unassigned devices.
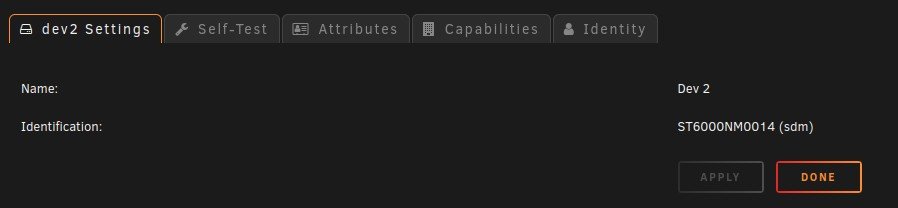
Notice Dev2 is also SDM like Disk 14.
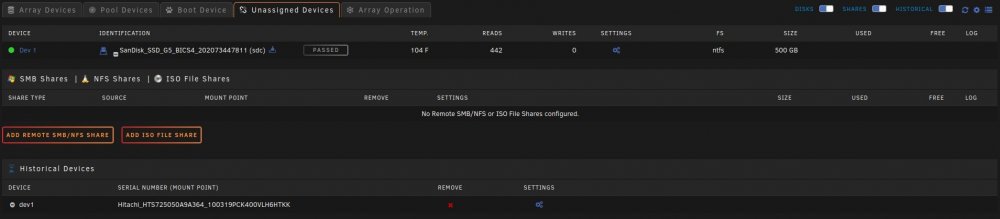
Unassigned Devices tab under Main doesn't show this phenomena.
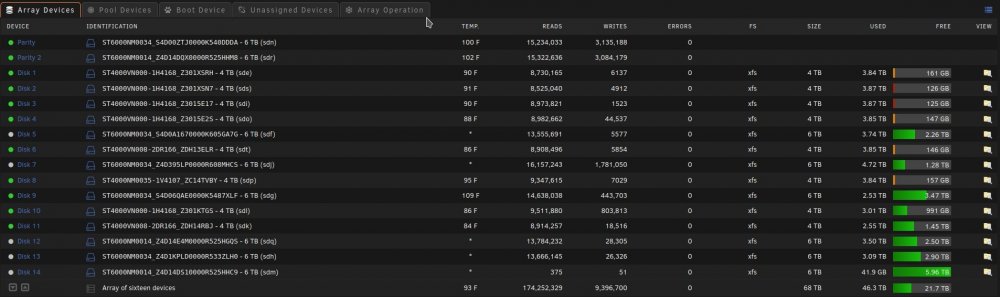
As you can see the Temps aren't even shown here but they are shown under Unassigned devices Dashboard section.
It's not a problem now but think it needs to be looked into. Want anything else to help diagnose this just let me know.
Thank you for your time and help ahead of time. Y'all rock!
-
I too am having this problem. Stopped VM Manager in settings in order to move all my VMs to a new NVMe drive installed just for VMs. When I started the VM Manager I ran in to this problem.
Log Entry:
root: /mnt/apps/system/libvirt/libvirt.img is in-use, cannot mount
Output of requested commends:
:~# fuser -s "/mnt/user/system/libvirt/libvirt.img" :~# :~# losetup -j "/mnt/user/system/libvirt/libvirt.img" :~# :~# fuser -c /mnt/user/system/libvirt/libvirt.img /mnt/user/system/libvirt/libvirt.img: 3604 3766m 6260c 6578c 8214 8215 8367 9023 10355 12704 12705 12706 12767m 13068 13069 13070 13071 13072 14181m 16701m 17871 17873 17905 17906 17907 17908 20952 32970c 40041 :~#
Those PIDs also corresponds to every docker container I have running at the time. As my server is in use at this time I cannot reboot or stop docker to try to fix.
Here is my Diagnostics. Need anything else just ask. Happy to help any way I can. I won't be able to try to get VM Manager back up for a couple hours and I will check here before I try just in case there is anything you want me to do.
-
Yup, My whole server is 100% stable since I removed that 9305-24i and put the 3 old cards back in. My onboard network card was even unstable when it was installed. There really had to be something wrong with that card. Lucky it didn't destroy my server.
As fair warning, be careful to get your cards from reliable sources. Even if they are expensive they can still be not a reliable source. Lucky for me the seller took back the card and returned my money. I contacted LSI and they said the S/N didn't exist in their system so I think I got a stolen card.
-
18 hours ago, trurl said:
Unlikely. Probably it was created there at some time when cache wasn't accessible.
Than how was my VMs still in tract on the libvert.img that was on my array. I thought the same as you and figured I would have to restore the monthly backup of the file but I didn't since the file on the array was the same as the file that disappeared from my Apps Cache Pool. I know for a fact the file was on that SSD the day before I stated my rebuild. Just strange.
It's working fine now. Just have to RMA my 9305-24i for an other one and try again.
-
OK, This is solved. Rebuilt the disk fine. A load like this would crash the LSI 9305-24i card so 100% verified it was the card..
As for the "No Virtual Machines installed" error for some reason my server moved the livert.img to the array even though it was set to Apps Cache pool only. I moved the libvert.img back to the Apps Cache Pool and my VMs came back up. This is odd and I've never experienced this before.
Thank you for your help again and I'm sorry for the miss understanding with the eMail being not helpful.
-
On 12/25/2021 at 3:43 AM, JorgeB said:
In this case the syslog is the main source, so it's the same, what I mentioned didn't help much was the array health email you posted earlier.
Thank you for clarification.
I just downgraded to my old HBAs and I'm rebuilding the disabled disks one at a time. The first disk should be done in 24 hours and then I will do the second disk. Thank you for your help. I've determined I received a bad LSI 9305-24i card after all my testing. I will try to get another one someday and try to do this upgrade again as I need the PCIe slots for a second video card.
Any suggestion for a LSI 24i card or is the 9305-24i I purchased previously usually a good card.
I also noticed when I restarted my array for the rebuild my VM service says "No Virtual Machines installed." Is this normal during a rebuild?
-
32 minutes ago, JorgeB said:
Dec 23 13:16:33 Rudder2-Server kernel: mpt3sas_cm0: SAS host is non-operational !!!!Same issue.
So there is not more information in the Diagnostics file than the logs? I must of totally not understood your comment. I though the Diagnostics file would give you more information about the problems.
-
Can someone please review the diagnostics file and try to give me a better explanation of what's going on? I was finally able to get diagnostics before the server locked up. The file is posted above.
-
Finally was awake when I received the notification of the server error and got a diagnostic before it locked up! It's in the process of erroring so bad it locks up. Here it is.
-
Nope, it locked up again this morning. Same errors. The first time it disconnected was @ 0148 AM, then @ 0407 AM the next day, staid up for 45 hours after the changes I made above, then disconnected @ 0637. I'm sure it's not my board. The old HBAs worked fine. When I installed the new one this started a week after installation.
-
OK, so yesterday I removed all my PCIe cards and reinstalled them. Made some changes in the BIOS, I enabled 4x,4x,4x,4x bifurcation for the NVMe PCIe slot and enabled Isoc. Last night the server didn't lockup and there is no HBA Disconnect or read errors in the logs. I will let it run like this for a couple days and if it doesn't lock up I will start rebuilding my disabled disks.
I also noticed my NVMe performance is slightly better. I bought a high quality PCIe NVMe card which will be here soon also.
Will keep y'all posted.
-
The system started locking up and throwing errors 32 hours ago. The new HBA has been in for a week and the new NVNe for 6 weeks to a 2 months. That's all the changes to the server in 2 years.
Could a cheep NVMe PCIe card conflict with the new HBA? Can't remove NVMe since I moved all my app data to it is the problem or I would to that for testing.
The NVMe is on CPU 1 PCIe bus and the HBA is on CPU 2 PCIe bus.
-
It is enabled...That's how I keep getting logs. You said:
23 hours ago, JorgeB said:23 hours ago, Rudder2 said:Does this help with anything?
Not really since we can't see what caused the errors, like trurl mentioned safest option is to rebuild using spare disks.
So basically the logs are worthless is what I get from that statement. I'm happy I didn't rebuild the disks as I would of been SOL when the system locked up again
-
OK, so my server locked up again last night. I haven't had this problem till I stalled the new HBA and NVMe card so I'm going with that and not going to suspect my hardware. The most recent changes are most likely the cause no matter how crazy. This SuperMicro server is rock solid usually...Has been since I put it in to service 2 years ago as an upgrade from my i7 tower that ran out of resources.
Dec 18 04:07:06 Rudder2-Server kernel: mpt3sas_cm0: SAS host is non-operational !!!!
Dec 18 04:07:07 Rudder2-Server kernel: mpt3sas_cm0: SAS host is non-operational !!!!
Dec 18 04:07:08 Rudder2-Server kernel: mpt3sas_cm0: SAS host is non-operational !!!!
Dec 18 04:07:09 Rudder2-Server kernel: mpt3sas_cm0: SAS host is non-operational !!!!
Dec 18 04:07:10 Rudder2-Server kernel: mpt3sas_cm0: SAS host is non-operational !!!!
Dec 18 04:07:11 Rudder2-Server kernel: mpt3sas_cm0: SAS host is non-operational !!!!
Dec 18 04:07:11 Rudder2-Server kernel: mpt3sas_cm0: _base_fault_reset_work: Running mpt3sas_dead_ioc thread success !!!!
Dec 18 04:07:11 Rudder2-Server kernel: sd 1:0:0:0: [sde] Synchronizing SCSI cache
Dec 18 04:07:11 Rudder2-Server kernel: sd 1:0:2:0: [sdg] tag#3349 UNKNOWN(0x2003) Result: hostbyte=0x01 driverbyte=0x00 cmd_age=5s
Dec 18 04:07:11 Rudder2-Server kernel: sd 1:0:2:0: [sdg] tag#3349 CDB: opcode=0x7f, sa=0x9
Dec 18 04:07:11 Rudder2-Server kernel: sd 1:0:2:0: [sdg] tag#3349 CDB[00]: 7f 00 00 00 00 00 00 18 00 09 20 00 00 00 00 00
Dec 18 04:07:11 Rudder2-Server kernel: sd 1:0:2:0: [sdg] tag#3349 CDB[10]: e8 0b e7 c0 e8 0b e7 c0 00 00 00 00 00 00 01 00
Dec 18 04:07:11 Rudder2-Server kernel: blk_update_request: I/O error, dev sdg, sector 3893094336 op 0x0:(READ) flags 0x0 phys_seg 32 prio class 0....
Dec 18 04:53:14 Rudder2-Server kernel: sd 1:0:19:0: attempting task abort!scmd(0x00000000ece0b417), outstanding for 61440 ms & timeout 60000 ms
Dec 18 04:53:14 Rudder2-Server kernel: sd 1:0:19:0: tag#3361 CDB: opcode=0x35 35 00 00 00 00 00 00 00 00 00
Dec 18 04:53:14 Rudder2-Server kernel: scsi target1:0:19: handle(0x002c), sas_address(0x300062b2029915b4), phy(18)
Dec 18 04:53:14 Rudder2-Server kernel: scsi target1:0:19: enclosure logical id(0x500062b2029915a2), slot(8)
Dec 18 04:53:14 Rudder2-Server kernel: scsi target1:0:19: enclosure level(0x0000), connector name( )
Dec 18 04:53:14 Rudder2-Server kernel: sd 1:0:19:0: device been deleted! scmd(0x00000000ece0b417)
Dec 18 04:53:14 Rudder2-Server kernel: sd 1:0:19:0: task abort: SUCCESS scmd(0x00000000ece0b417)
Dec 18 04:53:16 Rudder2-Server kernel: md: disk2 read error, sector=5875745016
Dec 18 04:53:16 Rudder2-Server kernel: md: disk2 read error, sector=5875745024
Dec 18 04:53:16 Rudder2-Server kernel: md: disk2 read error, sector=5875745032
Dec 18 04:53:16 Rudder2-Server kernel: md: disk2 read error, sector=5875745040
Dec 18 04:53:16 Rudder2-Server kernel: md: disk2 read error, sector=5875745048
Dec 18 04:53:16 Rudder2-Server kernel: md: disk2 read error, sector=5875745056
Dec 18 04:53:16 Rudder2-Server kernel: md: disk2 read error, sector=5875745064
Dec 18 04:53:16 Rudder2-Server kernel: md: disk2 read error, sector=5875745072
Dec 18 04:53:17 Rudder2-Server kernel: md: disk2 read error, sector=5875743448
Dec 18 04:53:17 Rudder2-Server kernel: md: disk2 read error, sector=5875743456
Dec 18 04:53:17 Rudder2-Server kernel: md: disk2 read error, sector=5875743464
Dec 18 04:53:17 Rudder2-Server kernel: md: disk2 read error, sector=5875743472
Dec 18 04:53:17 Rudder2-Server kernel: md: disk2 read error, sector=5875743480
Dec 18 04:53:17 Rudder2-Server kernel: md: disk2 read error, sector=5875743488
Dec 18 04:53:17 Rudder2-Server kernel: md: disk2 read error, sector=5875743496
Dec 18 04:53:17 Rudder2-Server kernel: md: disk2 read error, sector=5875743504
Dec 18 04:53:19 Rudder2-Server kernel: md: disk2 read error, sector=5875745408
Dec 18 04:53:19 Rudder2-Server kernel: md: disk2 read error, sector=5875745416
Dec 18 04:53:19 Rudder2-Server kernel: md: disk2 read error, sector=5875745424
Dec 18 04:53:19 Rudder2-Server kernel: md: disk2 read error, sector=5875745432
Dec 18 04:53:19 Rudder2-Server kernel: md: disk2 read error, sector=5875745440
Dec 18 04:53:19 Rudder2-Server kernel: md: disk2 read error, sector=5875745448
Dec 18 04:53:19 Rudder2-Server kernel: md: disk2 read error, sector=5875745456
Dec 18 04:53:19 Rudder2-Server kernel: md: disk2 read error, sector=5875745464
Dec 18 04:53:19 Rudder2-Server kernel: md: disk2 read error, sector=5875745472
Dec 18 04:53:19 Rudder2-Server kernel: md: disk2 read error, sector=5875745480
Dec 18 04:53:20 Rudder2-Server kernel: md: disk2 read error, sector=5875744704
Dec 18 04:53:20 Rudder2-Server kernel: md: disk2 read error, sector=5875744712
Dec 18 04:53:20 Rudder2-Server kernel: md: disk2 read error, sector=5875744720
Dec 18 04:53:20 Rudder2-Server kernel: md: disk2 read error, sector=5875744728
Dec 18 04:53:20 Rudder2-Server kernel: md: disk2 read error, sector=5875744736
Dec 18 04:53:20 Rudder2-Server kernel: md: disk2 read error, sector=5875744744
Dec 18 04:53:20 Rudder2-Server kernel: md: disk2 read error, sector=5875744752
Dec 18 04:53:20 Rudder2-Server kernel: md: disk2 read error, sector=5875744760
Dec 18 04:53:20 Rudder2-Server kernel: md: disk2 read error, sector=5875744768
Dec 18 04:53:20 Rudder2-Server kernel: md: disk2 read error, sector=5875744776
Dec 18 04:53:22 Rudder2-Server kernel: md: disk2 read error, sector=5875743992
Dec 18 04:53:22 Rudder2-Server kernel: md: disk2 read error, sector=5875744000
Dec 18 04:53:22 Rudder2-Server kernel: md: disk2 read error, sector=5875744008
Dec 18 04:53:22 Rudder2-Server kernel: md: disk2 read error, sector=5875744016
Dec 18 04:53:22 Rudder2-Server kernel: md: disk2 read error, sector=5875744024
Dec 18 04:53:22 Rudder2-Server kernel: md: disk2 read error, sector=5875744032
Dec 18 04:53:22 Rudder2-Server kernel: md: disk2 read error, sector=5875744040
Dec 18 04:53:22 Rudder2-Server kernel: md: disk2 read error, sector=5875744048
Dec 18 04:53:22 Rudder2-Server kernel: md: disk2 read error, sector=5875744056
Dec 18 04:53:22 Rudder2-Server kernel: md: disk2 read error, sector=5875744064
Dec 18 04:53:24 Rudder2-Server kernel: md: disk2 read error, sector=5875744232
Dec 18 04:53:24 Rudder2-Server kernel: md: disk2 read error, sector=5875744240
Dec 18 04:53:24 Rudder2-Server kernel: md: disk2 read error, sector=5875744248
Dec 18 04:53:24 Rudder2-Server kernel: md: disk2 read error, sector=5875744256
Dec 18 04:53:24 Rudder2-Server kernel: md: disk2 read error, sector=5875744264
Dec 18 04:53:24 Rudder2-Server kernel: md: disk2 read error, sector=5875744272
Dec 18 04:53:24 Rudder2-Server kernel: md: disk2 read error, sector=5875744280
Dec 18 04:53:24 Rudder2-Server kernel: md: disk2 read error, sector=5875744288
Dec 18 04:53:24 Rudder2-Server kernel: md: disk2 read error, sector=5875744296
Dec 18 04:53:24 Rudder2-Server kernel: md: disk2 read error, sector=5875744304
Dec 18 04:53:24 Rudder2-Server kernel: md: disk2 read error, sector=5875744312Locked up here. Wish there was away to get Data before this thing locks up. It seams to only happen wee hours of the AM. When scheduled tasks are happening with the server. How do I diagnose this with out being able to get diagnostics?
-
OK, another piece of the puzzle...
My PCIe NVMe card disconnected at the same time wiping out the play history of many shows that was stored on those 2 disks. I've been using the PCIe NVMe for a couple months now with no trouble. The Plex SQLite3 DB time out errors happen at the same time as my HBA wasn't able too communicate.
I'm starting to wonder is PCIe NVNe card device are good. Maybe I need to get a more expensive one. I got a cheapy one for testing and it worked so well I moved all my app data and VM disks to it. After that I noticed Ransom dips in performance but never under 1600 MB/s till I install my new HBA. Now I see NVMe performance dips to 500MB/s.
Do you think upgrading to a Asus HYPER M.2 X16 GEN 4 CARD Hyper M.2 x16 Gen 4 Card (PCIe 4.0/3.0) would be better and ditch the cheapy card? Or go back to SATA SSDs and ditch NVMe in PCIe card slot.
Any thoughts would be appreciated.
-
I see this in the Log.
Dec 17 01:48:22 Rudder2-Server kernel: mpt3sas_cm0: SAS host is non-operational !!!!
Dec 17 01:48:23 Rudder2-Server kernel: mpt3sas_cm0: SAS host is non-operational !!!!
Dec 17 01:48:24 Rudder2-Server kernel: mpt3sas_cm0: SAS host is non-operational !!!!
Dec 17 01:48:25 Rudder2-Server kernel: mpt3sas_cm0: SAS host is non-operational !!!!
Dec 17 01:48:26 Rudder2-Server kernel: mpt3sas_cm0: SAS host is non-operational !!!!
Dec 17 01:48:27 Rudder2-Server kernel: mpt3sas_cm0: SAS host is non-operational !!!!
Dec 17 01:48:27 Rudder2-Server kernel: mpt3sas_cm0: _base_fault_reset_work: Running mpt3sas_dead_ioc thread success !!!!
Dec 17 01:48:27 Rudder2-Server kernel: sd 7:0:0:0: [sde] Synchronizing SCSI cache
Dec 17 01:48:27 Rudder2-Server kernel: sd 7:0:16:0: [sdu] tag#4179 UNKNOWN(0x2003) Result: hostbyte=0x01 driverbyte=0x00 cmd_age=0s
Dec 17 01:48:27 Rudder2-Server kernel: sd 7:0:16:0: [sdu] tag#4179 CDB: opcode=0x85 85 06 20 00 00 00 00 00 00 00 00 00 00 40 e5 00
Dec 17 01:48:27 Rudder2-Server kernel: sd 7:0:16:0: [sdu] tag#4180 UNKNOWN(0x2003) Result: hostbyte=0x01 driverbyte=0x00 cmd_age=0s
Dec 17 01:48:27 Rudder2-Server kernel: sd 7:0:16:0: [sdu] tag#4180 CDB: opcode=0x85 85 06 20 00 00 00 00 00 00 00 00 00 00 40 98 00
Dec 17 01:48:27 Rudder2-Server kernel: sd 7:0:10:0: [sdo] tag#4182 UNKNOWN(0x2003) Result: hostbyte=0x01 driverbyte=0x00 cmd_age=1s
Dec 17 01:48:27 Rudder2-Server kernel: sd 7:0:3:0: [sdh] tag#4181 UNKNOWN(0x2003) Result: hostbyte=0x01 driverbyte=0x00 cmd_age=5s
Dec 17 01:48:27 Rudder2-Server kernel: sd 7:0:3:0: [sdh] tag#4181 CDB: opcode=0x28 28 00 90 b8 a9 e8 00 04 00 00
Dec 17 01:48:27 Rudder2-Server kernel: sd 7:0:10:0: [sdo] tag#4182 CDB: opcode=0x7f, sa=0x9
Dec 17 01:48:27 Rudder2-Server kernel: blk_update_request: I/O error, dev sdh, sector 2428021224 op 0x0:(READ) flags 0x4000 phys_seg 128 prio class 0
Dec 17 01:48:27 Rudder2-Server kernel: md: disk9 read error, sector=2428021160
Dec 17 01:48:27 Rudder2-Server kernel: sd 7:0:10:0: [sdo] tag#4182 CDB[00]: 7f 00 00 00 00 00 00 18 00 09 20 00 00 00 00 01
Dec 17 01:48:27 Rudder2-Server kernel: sd 7:0:10:0: [sdo] tag#4182 CDB[10]: 0a bc 51 10 0a bc 51 10 00 00 00 00 00 00 00 20
Dec 17 01:48:27 Rudder2-Server kernel: md: disk9 read error, sector=2428021168
Dec 17 01:48:27 Rudder2-Server kernel: blk_update_request: I/O error, dev sdo, sector 4475080976 op 0x0:(READ) flags 0x0 phys_seg 4 prio class 0
Dec 17 01:48:27 Rudder2-Server kernel: md: disk9 read error, sector=2428021176
Dec 17 01:48:27 Rudder2-Server kernel: md: disk0 read error, sector=4475080912
Dec 17 01:48:27 Rudder2-Server kernel: md: disk9 read error, sector=2428021184
Dec 17 01:48:27 Rudder2-Server kernel: md: disk0 read error, sector=4475080920
Dec 17 01:48:27 Rudder2-Server kernel: md: disk0 read error, sector=4475080928
Dec 17 01:48:27 Rudder2-Server kernel: md: disk9 read error, sector=2428021192
Dec 17 01:48:27 Rudder2-Server kernel: md: disk0 read error, sector=4475080936
Dec 17 01:48:27 Rudder2-Server kernel: md: disk9 read error, sector=2428021200
Dec 17 01:48:27 Rudder2-Server kernel: md: disk9 read error, sector=2428021208
Dec 17 01:48:27 Rudder2-Server kernel: md: disk9 read error, sector=2428021216
Dec 17 01:48:27 Rudder2-Server kernel: md: disk9 read error, sector=2428021224
Dec 17 01:48:27 Rudder2-Server kernel: md: disk9 read error, sector=2428021232
Dec 17 01:48:27 Rudder2-Server kernel: md: disk9 read error, sector=2428021240
Dec 17 01:48:27 Rudder2-Server kernel: md: disk9 read error, sector=2428021248
Dec 17 01:48:27 Rudder2-Server kernel: md: disk9 read error, sector=2428021256
Dec 17 01:48:27 Rudder2-Server kernel: md: disk9 read error, sector=2428021264
Dec 17 01:48:27 Rudder2-Server kernel: md: disk9 read error, sector=2428021272
Dec 17 01:48:27 Rudder2-Server kernel: md: disk9 read error, sector=2428021280
Dec 17 01:48:27 Rudder2-Server kernel: md: disk9 read error, sector=2428021288
Dec 17 01:48:27 Rudder2-Server kernel: md: disk9 read error, sector=2428021296....
Dec 17 02:48:22 Rudder2-Server kernel: md: disk1 read error, sector=2032663968
Dec 17 02:48:22 Rudder2-Server kernel: md: disk1 read error, sector=2032663976
Dec 17 02:48:22 Rudder2-Server kernel: md: disk1 read error, sector=2032663984
Dec 17 02:48:22 Rudder2-Server kernel: md: disk1 read error, sector=2032663992
Dec 17 02:48:22 Rudder2-Server kernel: md: disk1 read error, sector=2032664000
Dec 17 02:48:25 Rudder2-Server emhttpd: spinning down /dev/sdu
Dec 17 02:48:25 Rudder2-Server emhttpd: spinning down /dev/sdr
Dec 17 02:48:25 Rudder2-Server emhttpd: spinning down /dev/sds
Dec 17 02:48:25 Rudder2-Server emhttpd: spinning down /dev/sdq
Dec 17 02:48:25 Rudder2-Server emhttpd: spinning down /dev/sdl
Dec 17 02:48:26 Rudder2-Server emhttpd: read SMART /dev/sdu
Dec 17 02:48:26 Rudder2-Server emhttpd: read SMART /dev/sdr
Dec 17 02:48:26 Rudder2-Server emhttpd: read SMART /dev/sds
Dec 17 02:48:26 Rudder2-Server emhttpd: read SMART /dev/sdq
Dec 17 02:48:26 Rudder2-Server emhttpd: read SMART /dev/sdl
Dec 17 02:48:31 Rudder2-Server emhttpd: spinning down /dev/sdh
Dec 17 02:48:31 Rudder2-Server emhttpd: spinning down /dev/sdt
Dec 17 02:48:32 Rudder2-Server emhttpd: read SMART /dev/sdh
Dec 17 02:48:32 Rudder2-Server emhttpd: read SMART /dev/sdt
Dec 17 02:48:32 Rudder2-Server kernel: sd 7:0:18:0: attempting task abort!scmd(0x000000004ec028bd), outstanding for 61441 ms & timeout 60000 ms
Dec 17 02:48:32 Rudder2-Server kernel: sd 7:0:18:0: tag#4199 CDB: opcode=0x35 35 00 00 00 00 00 00 00 00 00
Dec 17 02:48:32 Rudder2-Server kernel: scsi target7:0:18: handle(0x002b), sas_address(0x300062b2029915b7), phy(21)
Dec 17 02:48:32 Rudder2-Server kernel: scsi target7:0:18: enclosure logical id(0x500062b2029915a2), slot(14)
Dec 17 02:48:32 Rudder2-Server kernel: scsi target7:0:18: enclosure level(0x0000), connector name( )
Dec 17 02:48:32 Rudder2-Server kernel: sd 7:0:18:0: device been deleted! scmd(0x000000004ec028bd)
Dec 17 02:48:32 Rudder2-Server kernel: sd 7:0:18:0: task abort: SUCCESS scmd(0x000000004ec028bd)
Dec 17 02:48:32 Rudder2-Server kernel: sd 7:0:18:0: [sdw] Synchronize Cache(10) failed: Result: hostbyte=0x03 driverbyte=0x00
Dec 17 02:48:36 Rudder2-Server kernel: sd 7:0:19:0: [sdx] Synchronizing SCSI cache
Dec 17 02:48:38 Rudder2-Server kernel: XFS: metadata IO error: 5 callbacks suppressed
Dec 17 02:48:38 Rudder2-Server kernel: XFS (md4): metadata I/O error in "xfs_da_read_buf+0x9e/0xfe [xfs]" at daddr 0xe9550910 len 8 error 5
Dec 17 02:48:38 Rudder2-Server kernel: XFS (md4): metadata I/O error in "xfs_da_read_buf+0x9e/0xfe [xfs]" at daddr 0x9b801c08 len 8 error 5
Dec 17 02:48:38 Rudder2-Server kernel: XFS (md4): metadata I/O error in "xfs_da_read_buf+0x9e/0xfe [xfs]" at daddr 0x2a3a6ad8 len 8 error 5
Dec 17 02:48:38 Rudder2-Server kernel: XFS (md4): metadata I/O error in "xfs_da_read_buf+0x9e/0xfe [xfs]" at daddr 0x118e62d40 len 8 error 5
Dec 17 02:48:38 Rudder2-Server kernel: XFS (md4): metadata I/O error in "xfs_da_read_buf+0x9e/0xfe [xfs]" at daddr 0xa4093f60 len 8 error 5
Dec 17 02:48:38 Rudder2-Server rc.diskinfo[11782]: SIGHUP received, forcing refresh of disks info.
Dec 17 02:48:49 Rudder2-Server kernel: XFS (md4): metadata I/O error in "xfs_da_read_buf+0x9e/0xfe [xfs]" at daddr 0xe9550910 len 8 error 5
Dec 17 02:48:49 Rudder2-Server kernel: XFS (md4): metadata I/O error in "xfs_da_read_buf+0x9e/0xfe [xfs]" at daddr 0x9b801c08 len 8 error 5
Dec 17 02:48:49 Rudder2-Server kernel: XFS (md4): metadata I/O error in "xfs_da_read_buf+0x9e/0xfe [xfs]" at daddr 0x2a3a6ad8 len 8 error 5
Dec 17 02:48:49 Rudder2-Server kernel: XFS (md4): metadata I/O error in "xfs_da_read_buf+0x9e/0xfe [xfs]" at daddr 0x118e62d40 len 8 error 5
Dec 17 02:48:49 Rudder2-Server kernel: XFS (md4): metadata I/O error in "xfs_da_read_buf+0x9e/0xfe [xfs]" at daddr 0xa4093f60 len 8 error 5
Dec 17 02:49:12 Rudder2-Server kernel: XFS: metadata IO error: 5 callbacks suppressed
Dec 17 02:49:12 Rudder2-Server kernel: XFS (md4): metadata I/O error in "xfs_da_read_buf+0x9e/0xfe [xfs]" at daddr 0xe9550910 len 8 error 5
Dec 17 02:49:12 Rudder2-Server kernel: XFS (md4): metadata I/O error in "xfs_da_read_buf+0x9e/0xfe [xfs]" at daddr 0x9b801c08 len 8 error 5
Dec 17 02:49:12 Rudder2-Server kernel: XFS (md4): metadata I/O error in "xfs_da_read_buf+0x9e/0xfe [xfs]" at daddr 0x2a3a6ad8 len 8 error 5
Dec 17 02:49:12 Rudder2-Server kernel: XFS (md4): metadata I/O error in "xfs_da_read_buf+0x9e/0xfe [xfs]" at daddr 0x118e62d40 len 8 error 5
Dec 17 02:49:12 Rudder2-Server kernel: XFS (md4): metadata I/O error in "xfs_da_read_buf+0x9e/0xfe [xfs]" at daddr 0xa4093f60 len 8 error 5
Dec 17 02:49:23 Rudder2-Server kernel: XFS (md4): metadata I/O error in "xfs_da_read_buf+0x9e/0xfe [xfs]" at daddr 0xe9550910 len 8 error 5
Dec 17 02:49:23 Rudder2-Server kernel: XFS (md4): metadata I/O error in "xfs_da_read_buf+0x9e/0xfe [xfs]" at daddr 0x9b801c08 len 8 error 5
Dec 17 02:49:23 Rudder2-Server kernel: XFS (md4): metadata I/O error in "xfs_da_read_buf+0x9e/0xfe [xfs]" at daddr 0x2a3a6ad8 len 8 error 5
Dec 17 02:49:23 Rudder2-Server kernel: XFS (md4): metadata I/O error in "xfs_da_read_buf+0x9e/0xfe [xfs]" at daddr 0x118e62d40 len 8 error 5
Dec 17 02:49:23 Rudder2-Server kernel: XFS (md4): metadata I/O error in "xfs_da_read_buf+0x9e/0xfe [xfs]" at daddr 0xa4093f60 len 8 error 5
Dec 17 02:49:38 Rudder2-Server kernel: sd 7:0:19:0: attempting task abort!scmd(0x00000000d232fe20), outstanding for 62078 ms & timeout 60000 ms
Dec 17 02:49:38 Rudder2-Server kernel: sd 7:0:19:0: tag#4200 CDB: opcode=0x35 35 00 00 00 00 00 00 00 00 00
Dec 17 02:49:38 Rudder2-Server kernel: scsi target7:0:19: handle(0x002c), sas_address(0x300062b2029915b8), phy(22)
Dec 17 02:49:38 Rudder2-Server kernel: scsi target7:0:19: enclosure logical id(0x500062b2029915a2), slot(12)
Dec 17 02:49:38 Rudder2-Server kernel: scsi target7:0:19: enclosure level(0x0000), connector name( )
Dec 17 02:49:38 Rudder2-Server kernel: sd 7:0:19:0: device been deleted! scmd(0x00000000d232fe20)
Dec 17 02:49:38 Rudder2-Server kernel: sd 7:0:19:0: task abort: SUCCESS scmd(0x00000000d232fe20)
Dec 17 02:49:45 Rudder2-Server kernel: XFS: metadata IO error: 5 callbacks suppressed
Dec 17 02:49:45 Rudder2-Server kernel: XFS (md4): metadata I/O error in "xfs_da_read_buf+0x9e/0xfe [xfs]" at daddr 0xe9550910 len 8 error 5
Dec 17 02:49:45 Rudder2-Server kernel: XFS (md4): metadata I/O error in "xfs_da_read_buf+0x9e/0xfe [xfs]" at daddr 0x9b801c08 len 8 error 5
Dec 17 02:49:45 Rudder2-Server kernel: XFS (md4): metadata I/O error in "xfs_da_read_buf+0x9e/0xfe [xfs]" at daddr 0x2a3a6ad8 len 8 error 5
Dec 17 02:49:45 Rudder2-Server kernel: XFS (md4): metadata I/O error in "xfs_da_read_buf+0x9e/0xfe [xfs]" at daddr 0x118e62d40 len 8 error 5
Dec 17 02:49:45 Rudder2-Server kernel: XFS (md4): metadata I/O error in "xfs_da_read_buf+0x9e/0xfe [xfs]" at daddr 0xa4093f60 len 8 error 5
Dec 17 02:49:53 Rudder2-Server emhttpd: spinning down /dev/sdo
Dec 17 02:49:54 Rudder2-Server emhttpd: read SMART /dev/sdo
Dec 17 02:49:56 Rudder2-Server kernel: XFS (md4): metadata I/O error in "xfs_da_read_buf+0x9e/0xfe [xfs]" at daddr 0xe9550910 len 8 error 5
Dec 17 02:49:56 Rudder2-Server kernel: XFS (md4): metadata I/O error in "xfs_da_read_buf+0x9e/0xfe [xfs]" at daddr 0x9b801c08 len 8 error 5
Dec 17 02:49:56 Rudder2-Server kernel: XFS (md4): metadata I/O error in "xfs_da_read_buf+0x9e/0xfe [xfs]" at daddr 0x2a3a6ad8 len 8 error 5
Dec 17 02:49:56 Rudder2-Server kernel: XFS (md4): metadata I/O error in "xfs_da_read_buf+0x9e/0xfe [xfs]" at daddr 0x118e62d40 len 8 error 5
Dec 17 02:49:56 Rudder2-Server kernel: XFS (md4): metadata I/O error in "xfs_da_read_buf+0x9e/0xfe [xfs]" at daddr 0xa4093f60 len 8 error 5
Dec 17 02:50:04 Rudder2-Server kernel: md: disk1 read error, sector=7657280264
Dec 17 02:50:04 Rudder2-Server kernel: md: disk2 read error, sector=7657280264
Dec 17 02:50:04 Rudder2-Server kernel: md: disk4 read error, sector=7657280264
Dec 17 02:50:04 Rudder2-Server kernel: md: disk5 read error, sector=7657280264
Dec 17 02:50:04 Rudder2-Server kernel: md: disk6 read error, sector=7657280264
Dec 17 02:50:04 Rudder2-Server kernel: md: disk8 read error, sector=7657280264
Dec 17 02:50:04 Rudder2-Server kernel: md: disk10 read error, sector=7657280264
Dec 17 02:50:04 Rudder2-Server kernel: md: disk11 read error, sector=7657280264
Dec 17 02:50:04 Rudder2-Server kernel: md: disk12 read error, sector=7657280264
Dec 17 02:50:04 Rudder2-Server kernel: md: disk13 read error, sector=7657280264
Dec 17 02:50:04 Rudder2-Server kernel: md: disk0 read error, sector=7657280264
Dec 17 02:50:04 Rudder2-Server kernel: md: disk29 read error, sector=7657280264
Dec 17 02:50:15 Rudder2-Server dhcpcd[2757]: br2: Router Advertisement from fe80::1:1
Dec 17 02:50:19 Rudder2-Server kernel: XFS: metadata IO error: 5 callbacks suppressed
Dec 17 02:50:19 Rudder2-Server kernel: XFS (md4): metadata I/O error in "xfs_da_read_buf+0x9e/0xfe [xfs]" at daddr 0xe9550910 len 8 error 5
Dec 17 02:50:19 Rudder2-Server kernel: XFS (md4): metadata I/O error in "xfs_da_read_buf+0x9e/0xfe [xfs]" at daddr 0x9b801c08 len 8 error 5
Dec 17 02:50:19 Rudder2-Server kernel: XFS (md4): metadata I/O error in "xfs_da_read_buf+0x9e/0xfe [xfs]" at daddr 0x2a3a6ad8 len 8 error 5
Dec 17 02:50:19 Rudder2-Server kernel: XFS (md4): metadata I/O error in "xfs_da_read_buf+0x9e/0xfe [xfs]" at daddr 0x118e62d40 len 8 error 5
Dec 17 02:50:19 Rudder2-Server kernel: XFS (md4): metadata I/O error in "xfs_da_read_buf+0x9e/0xfe [xfs]" at daddr 0xa4093f60 len 8 error 5
Dec 17 02:50:29 Rudder2-Server dhcpcd[2757]: br2: Router Advertisement from fe80::1:1
Dec 17 02:50:30 Rudder2-Server kernel: XFS (md4): metadata I/O error in "xfs_da_read_buf+0x9e/0xfe [xfs]" at daddr 0xe9550910 len 8 error 5
Dec 17 02:50:30 Rudder2-Server kernel: XFS (md4): metadata I/O error in "xfs_da_read_buf+0x9e/0xfe [xfs]" at daddr 0x9b801c08 len 8 error 5
Dec 17 02:50:30 Rudder2-Server kernel: XFS (md4): metadata I/O error in "xfs_da_read_buf+0x9e/0xfe [xfs]" at daddr 0x2a3a6ad8 len 8 error 5
Dec 17 02:50:30 Rudder2-Server kernel: XFS (md4): metadata I/O error in "xfs_da_read_buf+0x9e/0xfe [xfs]" at daddr 0x118e62d40 len 8 error 5
Dec 17 02:50:30 Rudder2-Server kernel: XFS (md4): metadata I/O error in "xfs_da_read_buf+0x9e/0xfe [xfs]" at daddr 0xa4093f60 len 8 error 5
Dec 17 02:50:39 Rudder2-Server kernel: sd 7:0:19:0: attempting task abort!scmd(0x0000000018aeb544), outstanding for 61440 ms & timeout 60000 ms
Dec 17 02:50:39 Rudder2-Server kernel: sd 7:0:19:0: tag#4201 CDB: opcode=0x35 35 00 00 00 00 00 00 00 00 00
Dec 17 02:50:39 Rudder2-Server kernel: scsi target7:0:19: handle(0x002c), sas_address(0x300062b2029915b8), phy(22)
Dec 17 02:50:39 Rudder2-Server kernel: scsi target7:0:19: enclosure logical id(0x500062b2029915a2), slot(12)
Dec 17 02:50:39 Rudder2-Server kernel: scsi target7:0:19: enclosure level(0x0000), connector name( )
Dec 17 02:50:39 Rudder2-Server kernel: sd 7:0:19:0: device been deleted! scmd(0x0000000018aeb544)
Dec 17 02:50:39 Rudder2-Server kernel: sd 7:0:19:0: task abort: SUCCESS scmd(0x0000000018aeb544)
Dec 17 02:50:52 Rudder2-Server kernel: XFS: metadata IO error: 5 callbacks suppressed
Dec 17 02:50:52 Rudder2-Server kernel: XFS (md4): metadata I/O error in "xfs_da_read_buf+0x9e/0xfe [xfs]" at daddr 0xe9550910 len 8 error 5
Dec 17 02:50:52 Rudder2-Server kernel: XFS (md4): metadata I/O error in "xfs_da_read_buf+0x9e/0xfe [xfs]" at daddr 0x9b801c08 len 8 error 5
Dec 17 02:50:52 Rudder2-Server kernel: XFS (md4): metadata I/O error in "xfs_da_read_buf+0x9e/0xfe [xfs]" at daddr 0x2a3a6ad8 len 8 error 5
Dec 17 02:50:52 Rudder2-Server kernel: XFS (md4): metadata I/O error in "xfs_da_read_buf+0x9e/0xfe [xfs]" at daddr 0x118e62d40 len 8 error 5
Dec 17 02:50:52 Rudder2-Server kernel: XFS (md4): metadata I/O error in "xfs_da_read_buf+0x9e/0xfe [xfs]" at daddr 0xa4093f60 len 8 error 5Server Locked up here.
I cut out all the read errors to see if this helps.
-
I have SysLog Server set up. I forgot I did that. Must of done it when it first came out and forgot about it since my server has been humming along for so long. Is there anything in my logs that will be privet information? If not I can upload the last 36 hours of logs.
-
Good thing I have 4 spares sitting next to me Preclearded and ready.
-
OK, I just found in my eMail @ 0150 this morning while I was sleeping and the Parity Check was going:
Parity disk - ST6000NM0034_S4D00ZTJ0000K540DDDA_35000c50089007ad7 (sdo) (errors 40)
Disk 1 - ST4000VN000-1H4168_Z301XSRH (sde) (errors 1)
Disk 2 - ST4000VN000-1H4168_Z301XSN7 (sdn) (errors 47)
Disk 3 - ST4000VN000-1H4168_Z3015E17 (sdx) (errors 175)
Disk 4 - ST4000VN000-1H4168_Z3015E2S (sdp) (errors 117)
Disk 5 - ST4000VN000-1H4168_Z301KTFN (sdi) (errors 47)
Disk 6 - ST4000VN008-2DR166_ZDH13ELR (sdm) (errors 47)
Disk 7 - ST6000NM0014_Z4D14DS10000R525HHC9_35000c500634c8f23 (sdt) (errors 1594)
Disk 8 - ST4000NM0035-1V4107_ZC14TVBY (sdg) (errors 35)
Disk 9 - ST2000DL003-9VT166_5YD8BA87 (sdh) (errors 5178)
Disk 10 - ST4000VN000-1H4168_Z301KTGS (sdv) (errors 48)
Disk 11 - ST4000VN008-2DR166_ZDH14RBJ (sdw) (errors 48)
Disk 12 - ST6000NM0014_Z4D14E4M0000R525HGQS_35000c500634c6a1f (sdk) (errors 360)
Disk 13 - ST6000NM0034_Z4D1KPLD0000R533ZLH0_35000c50083450fbf (sdf) (errors 35)
Parity 2 - ST6000NM0014_Z4D14DQX0000R525HHM8_35000c500634c9033 (sdj) (errors 296)Does this help with anything?
-
I haven't had a problem before since my Rocket RAID debunkle back in April 2018. I was running 3 LSI 9210-8i cards for my 24 port backplate. I needed the PCIe 3.0 slots so I upgraded to an LSI 9305-24i card. I had no problems since installed it Friday Last week until today, the first parity check since the LSI card was installed.
I woke up this AM and my server was hard locked. I had to force a reboot and when unRAID came back up 2 Data drives were emulated. The Data is there. I'm scared to do anything because if I loose one more drive I'm up shits creek with no paddle. The last time this happened JorgeB had me run:
On 4/4/2018 at 6:01 PM, JorgeB said:-Tools -> New Config -> Retain current configuration: All -> Apply
-assign any missing disk(s)
check "parity is already valid" before starting the array
-start the arrayand it fixed my problem back then.
I have in my Parity History
2021-12-17, 01:51:32 2 hr, 51 min, 31 sec Unavailable Canceled 257
Once again, the way unRAID does logs is going to kill us here. It seams my server ALWAYS locks up when I have a problem.
Thank you for your time and help.
-
Squid assisted me with this years ago...I do weekly reboot...Been working flawlessly for years now!
-
I too want to upvote this. I have a SuperMicro server with SAS drives in it. Auto spin-down and spin-up would be nice.


[Support] Vault
in Docker Containers
Posted · Edited by Rudder2
I suck at spelling...
Does the Vault/File folder have to be on the cache drive or can it live on the array? I would prefer the protection for such data on the array.
Thank you for creating this unRAID template! I appreciate the work that the Devs do to make our OS AWESOME! Thank you for your time and help.