
DanielCoffey
-
Posts
268 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by DanielCoffey
-
-
That is just what I needed, thank you. So just as with other Dockers, we can close the Docker window and the process inside it will carry on running. We can pop back later and reopen the WebUI and take a fresh peek at how it is getting on. Once it is completely finished we are free to stop the Docker if we want.
Cheers.
-
Please excuse the possibly idiot question but can I close the Docker command prompt window while the preclear is running (like you could with Screen) or must it remain open in order for the script to continue? On an 8Tb drive it will of course need to run for quite a while and this was not mentioned in the FAQ.
-
Good point, thanks. I will report back with what I receive.
-
Well I have to say I am REALLY impressed with WD's warranty support!
Despite changing the SAS-SATA cable, trying the drive on a new HBA card and deleting the partition, it still did its odd shutdown thing one time in four. It still showed a slower transfer rate between 0-1Tb and that odd wobble between 5-6Tb compared to all the other seven identical drives. All the time it still performed perfectly well as a functioning hard drive in that it never lost data.
First WD had me run their own SMART data collecting tool which the drive of course passed. They advised that they couldn't really accept the DiskSpeed Docker results as evidence in a Warranty case since it wasn't their own tool but agreed that it was clear the drive had "something odd" about it. They just turned round and said that I should send it in and they would just replace it with a new one.
Not bad service for a two year old drive (which of course has a three year warranty). I feel that their opinion was that it was simply not worth the effort of sending the drive to a technician to be examined and analysed. Just replace it and move on.
Customer happy? Yup.
-
There we go - tidied up my post.
I will be rerunning the script soon as I have swapped one WD Red 8Tb out of the array was it is behaving oddly on shutdown and the DiskSpeed docker showed it had odd behaviour and performance. Sadly WD are being very slow to acknowledge my Warranty case so I may have to escalate it on Monday.
-
It seems to be there now...
-
Cheers - I'll do that after the movie.
-
Hello folks - I need some help getting back into the web GUI of my array after a router change.
I used to have the typical FTTC Modem to wireless router running IPv6 and DHCP to a static address (192.168.1.202) to my unraid box. Accessing the web GUI via http://192.168.1.202 was fine.
I have just changed to a 4G modem/router running IPv4 (at the moment) and of course the DHCP server is not set up to issue static addresses yet. I quickly found the dynamic address the server had been assigned and accessed it via http://192.168.1.127 (this time) but immediately ran into a problem.
My Windows 10 desktop browser changed the 192.168.1.127 into the "long" address that the box seemed to be using.
It gave the Server Not Found error : We can’t connect to the server at 47451451017659140b69fc701f291711f8f06834.unraid.net.
What do I need to change or reset in order to gain access to the web GUI again please? I do have a monitor on the server and I do have PuTTY.
-
I can answer the last part... no, you don't have to set Tunables to default before using the tool. The first test is performed using "current". It then takes a peek at "default". Only then does it start probing the possible values that may affect the performance.
If you want to set the values back to Default at any time, simply go to the Disk Settings page and delete the value in the fields that say "User Defined" and hit Apply. It will automatically reset them to Default for you.
-
 1
1
-
-
Good point, thanks. Now I have taken that drive off and also changed one of the SAS-SATA cables, I will observe the array. If it does it again I'll replace the card. Fortunately I can replace it like for like as I am not saturating it at all.
-
I have completed an Extended SMART test on the drive that has been giving me issues. Please could someone have a look at the results to see if there is anything that would indicate issues with the drive.
The drive itself is not in the array now so I am free to pull it and submit it for warranty replacement but I would like to know if there is something I could point a finger to in the SMART report rather than just relying on the DiskSpeed results.
The data on the drive has never been compromised (as far as I am aware) but it really hates shutting down (and I do recall one or two lockups on boot a fair while ago which may be related).
-
I agree the speed is odd but it is the one disk that seems to trigger the hard lock on power down or sleep. It is outside the array now and undergoing a full SMART test. My other Unassigned 8Tb is back in the array undergoing a rebuild.
-
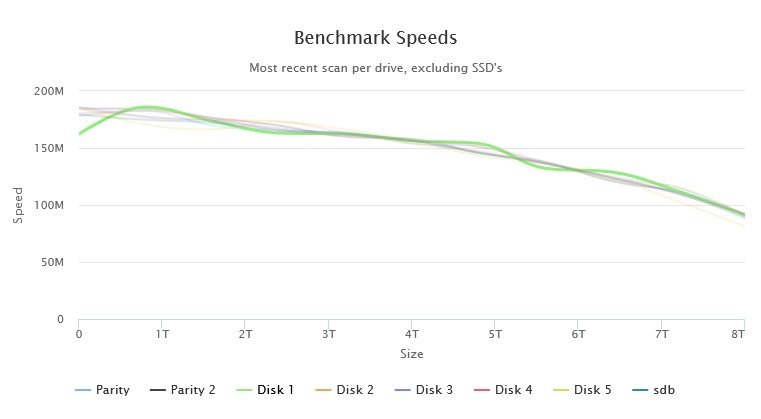
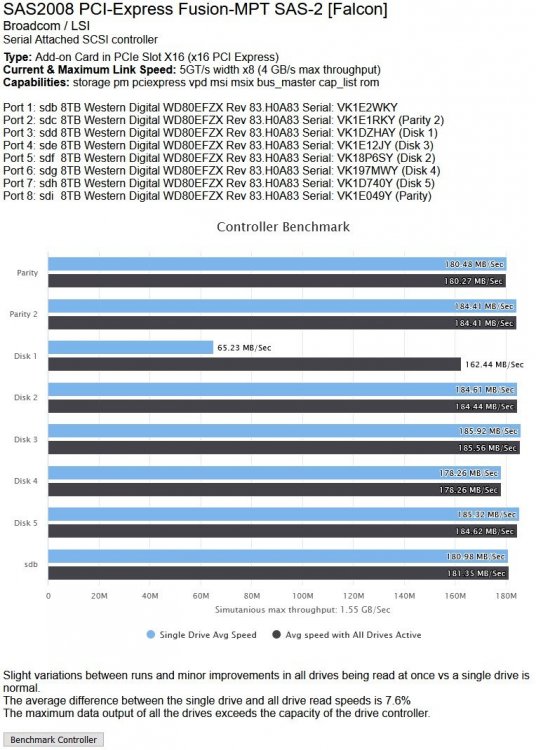
I have run multiple tests, yes. The really low result was a one-off and the c.162Mb/s was its regular result which coincides with the highest speed I can get on the beginning of a parity check.
I don't think my 8 drives are even close to saturating the 9201-8i I have as it allows 4Gb/s transfer and the eight drives are less than half of that.
I will be pulling that drive today anyway once the rebuild completes and I can write to the array again.
-
1 hour ago, jbartlett said:
Perform a benchmark on it every week or so to see if it returns an identical test. If it does return an identical test over the span of a month, it may just be how that drive is.
The problem is that the server locks up on about every four shutdowns/sleeps and drops Parity 1 and Disk 1 every time. I was looking for anomalies and spotted that Disk 1 stood out under the DiskSpeed tests. I have my own thread started about the dropouts and have added the DiskSpeed results to it.
-
An update - the array did its party trick again today with Disk 1 and Parity 1 being dropped. I had changed the SAS-to-SATA cable to those two disks earlier and all seemed well. However about four sleep/wake cycles later, the array froze and became totally non-responsive again. I had to hard power off to regain control. I don't have logs I am afraid.
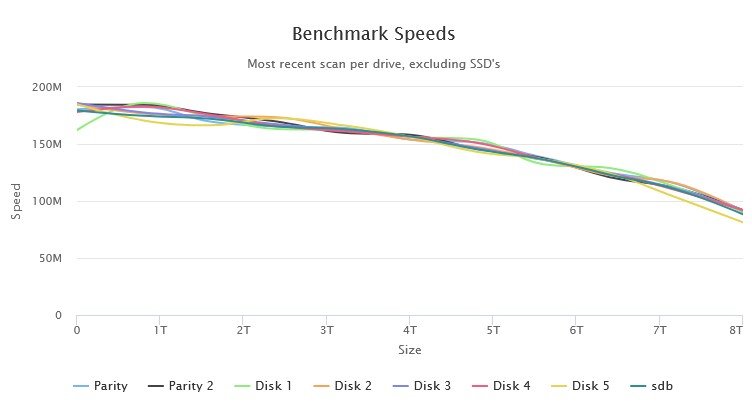
Earlier I had run the DiskSpeed docker and it did show anomalous behaviour on Disk 1 (see pics below) so despite the SMART report seeming clean I shall be performing a Parity rebuild then taking that disk out of the array.
I have one unassigned disk which I shall clear of my scratch backups and bring it in to replace Disk 1.
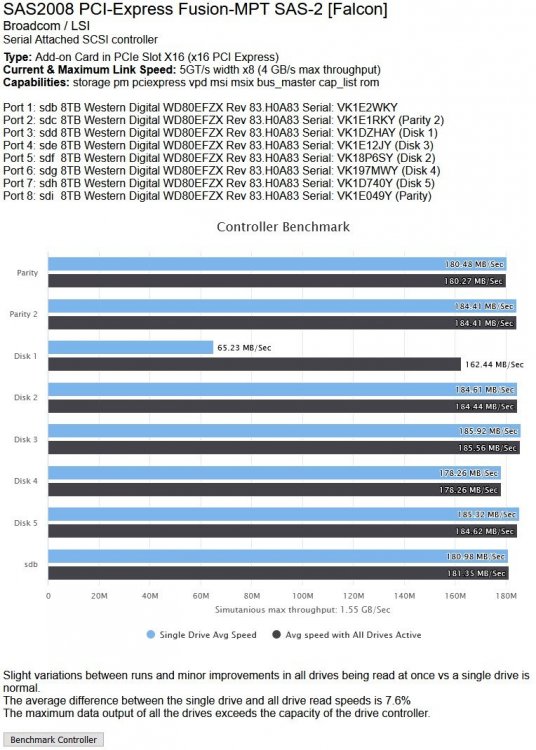
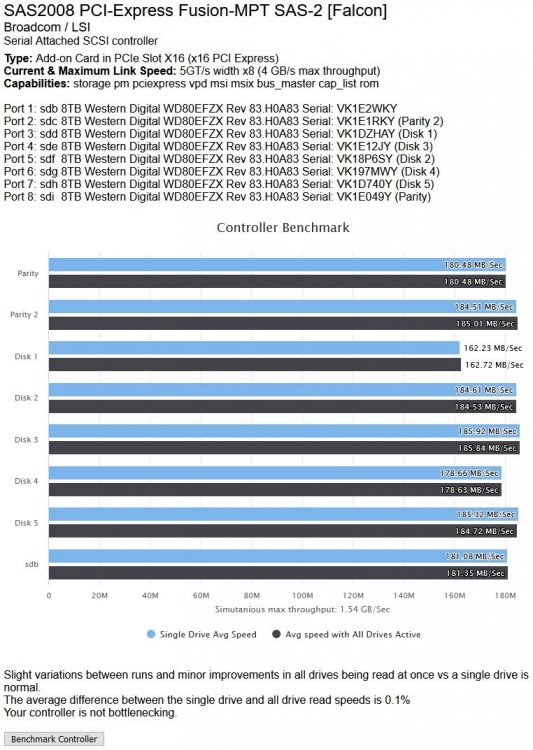
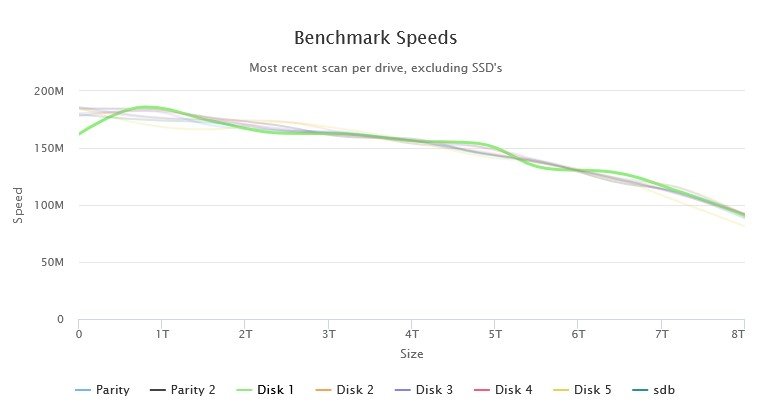
-
Hmm... do I need to be concerned about Disk 1 in this array? All drives are 8Tb WD Reds of the same age...
It has a consistent slow spot at the start of its platters and more wobbles than the rest of the disks. In addition when I benchmarked the controller, the first run through showed a VERY low result for it (so much so that DiskSpeed thought the controller was saturated). I redid the Benchmark and the result is consistent between tests now. I have also attached the Quick SMART for that drive.

-
Please could someone explain to a beginner how to use the syslog server in 6.7.2?
I can see where the option to turn it on or off is located but I don't know how to use it properly. I wouldn't mind pointing the logs to the cache or even an unassigned device but don't understand how to use it.
For my issue above, I have fitted a brand new SAS-SATA cable, thinking that Paroty 1 and Data 1 were on the same cable but discovered that the two drives that dropped each time before were the first two drives on each of the two SAS ports on the card.
I would like to have the syslog running to catch it when it next does it.
-
In the X2M machine in my signature I am running into a repeated problem when stopping the server with the same two drives dropping.
At the point where it is trying to unmount drives, the server locks and pegs all cores on the CPU at 100% (according to the unraid UI). No matter how long I leave it, I have to perform a hard power down to regain control of the machine. This of course deletes the logs.
Once I power the server back up the UI reports Parity 1 and Data 1 are emulated and I have to stop, unmount them, restart, stop, remount them then rebuild.
It doesn't do it every time, just about once in, say, four shutdowns. It is ALWAYS those two drives.
The drives are on my LSI SAS9201-8i which has two 4:1 SAS to SATA cables. Is it more likely to be the cable or the card? I never see the other two drives on that cable being dropped.
-
Yes it will. Parity has to match or exceed the largest data drive, so a 10Tb Parity would be the smallest you should use.
-
WD Reds are designed for continuous use. I too have had a WD Red 8Tb be RMAd on first use. The SMART stats showed terrible issues.
Decide how important it is for you to have the array available because if you just throw the untested drive in, write to it and then discover it was bad, you may have array downtime while the issue is fixed, especially if you did not have Parity yet.
I would agree with the preclear test times of about 20 hours as my 8Tb Reds take 17h30 for a parity check.
-
Version 4.1 Beta 2 Xtra Long Test completed...
-
 1
1
-
-
My server is back up (17h45m for a rebuild of two drives) so here is the Short v4.1 BETA 2 test result. An Xtra-Long test is now started.
-
Ugh - brought my server up this morning and it has dropped two disks (Parity 1 and Data 1 - probably loose cable). I'll have to rebuild Parity before running the script. I'll report back when that is done.
-
My non-nvme server is available for a long test too once you do. I am in the UK timezone so probably won't spot the new version till later but I'll keep an eye open.









[Support] binhex - Preclear
in Docker Containers
Posted · Edited by DanielCoffey
Here's a tip based on personal experience... make sure the array is not due to go to sleep while the Preclear is running. In my case it watched the array for 30 minutes, decided all was quiet, ignored the unassigned devices and shut down. Oh poop! Time to start over I guess.
EDIT : well colour me impressed! When I woke the array, the Preclear docker simply resumed from where it had left off and was up and ticking by the time I reopened the WebUI.