



DanielCoffey
Members
-
Joined
-
Last visited
-
Thank you - in that case I will probably do a totally clean install when 7.0.xx drops to clean anything I have accumulated over the past few years. I assume the things I would be advised to back up would be my USB thumb drive, shares and users then screenshot the drive assignments and Docker parameters. My plugins are minor plus there are only two Dockers and no VMs.
-
I am interested in knowing whether routine Updates to Unraid (say from 6.12.13 to 6.12.14) perform a totally clean install of everything apart from the Docker Config and drive assignments or whether any hardware settings are retained? Would 6.12.xx to 7.0.xx be any different? The reason I ask is that I am still experiencing very slow Plugin and Docker updates despite asking for opinions on my network and router config. No consensus was reached and the issue seemed to start after an earlier Unraid update when I wasn't paying attention to the time taken. I am talking about 12 seconds to check a single plugin to see if there is an update and about 8 seconds to check a Docker for an update despite a quiet router and fast broadband. Recently I have noticed that when a Plugin actually does have an update, the step "Executing hook script: pre_plugin_checks" seems about as slow to execute as asking to refresh the list of plugins. If Unraid preserves some hardware and network settings between updates I am considering a full and clean reinstall when Unraid 7 arrives although setting up my Dockers again is something I don't have a lot of experience with.
-
I assume you were looking at the 4Gb B800Pi SLC model instead of the B600Sc MLC, yes?
-
Names lookup instantly too.
-
Now that was very revealing, thank you. My unraid server seems to be set up for IPv4 but my Windows machine is IPv6 so I get different results depending which machine I ping/traceroute from. hub.docker.com is 100% packetloss on both machines since I suspect the server does not respond to pings. Both machines get partial results from traceroute/tracert. Each line of traceroute is slow to appear, regardless of which machine I run it on. raw.githubusercontent.com pings perfectly on both machines but Unraid is slow to start pinging. With traceroute, the Windows PC gets most of the hops normally but Unraid is again slow to start the traceroute, loses one, picks up again and then drops the thread. Any thoughts as to the issue? If told how, I could attempt to turn on IPv6 on the Unraid box.
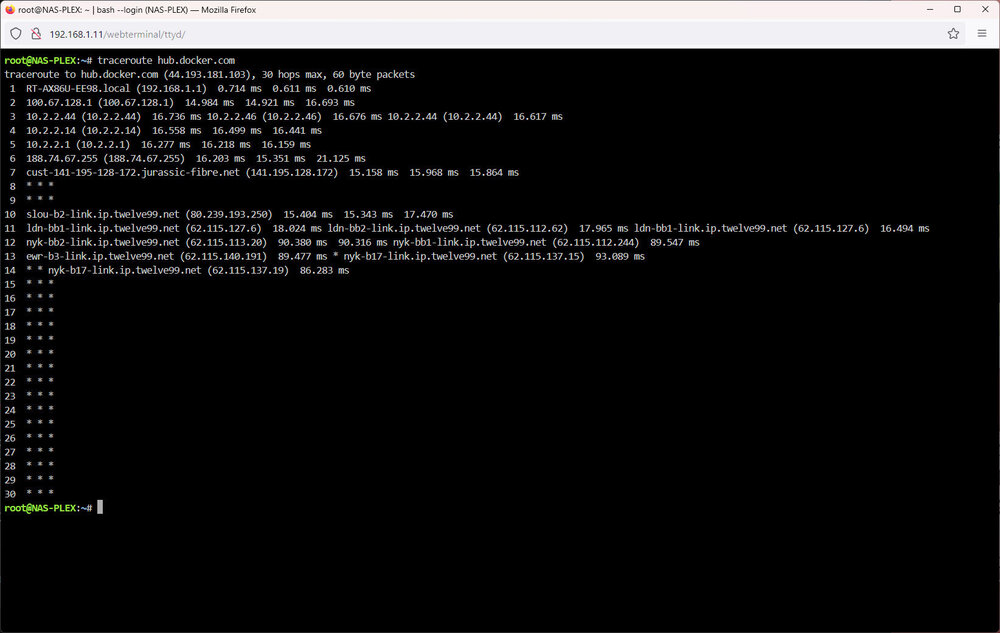
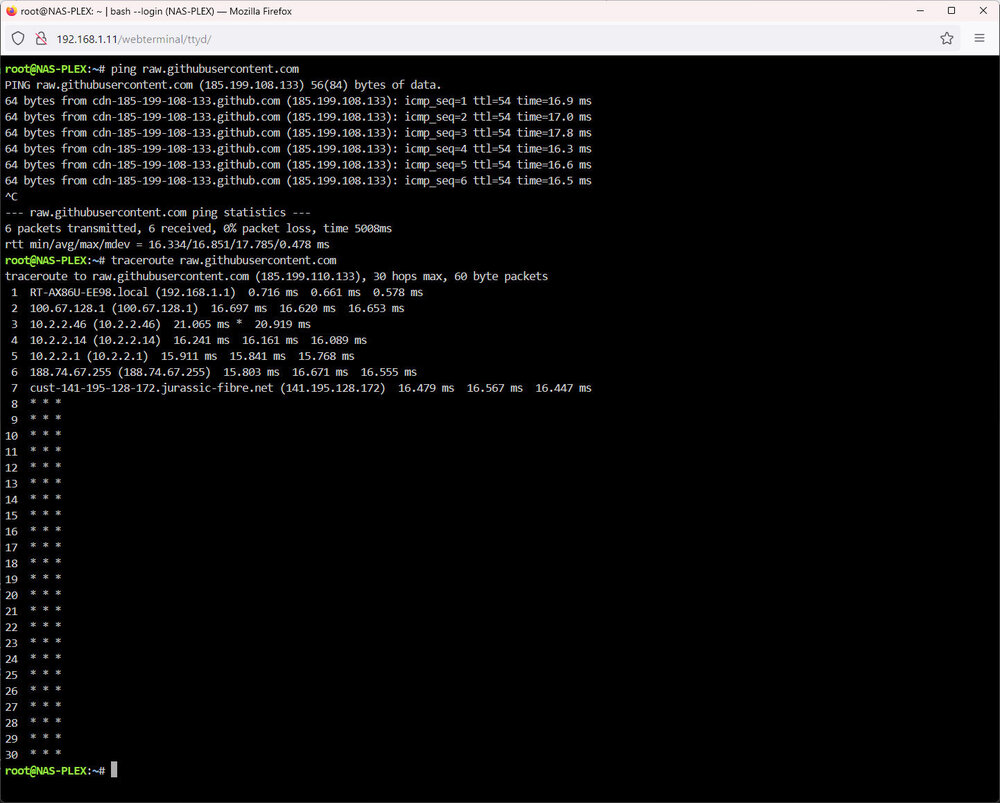
-
Update 03 September : I have downloaded and created a Trial USB stick and added the exact same plugins. There was no change to the time taken to Check for Updates. Still 36 seconds for 6 plugins. That hopefully eliminates anything inside the UNRAID box as the issue. I don't have any easy way to connect to a wifi hotspot without reconfiguring my router as an access point and totally messing my home network. Is there a listing of the server address that the Check for Updates contacts so that I can ping and tracert to it from the UNRAID box?
-
Thank you for the idea. Are there instructions for doing this without messing up my main flash drive (which I have just remembered is installed internally on a header... means pulling out the box to get at it)? I have already loaded unraid in safe mode before and it made no difference.
-
I am still having issues with slow plugin checking and would appreciate some thoughts on the cause. I can add that it is consistent, 24s to check two Dockers and 36s for 6 plugins. I can ping from the server to Google DNS and get 16ms responses as normal. Asking for OS Updates is instant and fast. Docker Updates are fast. It is just the checking that is slow. Could it be an issue of my ISP resolving just the checking server? Is there an address I can ping to test it?
-
Just an update. I have reset back to 8.8.8.8 and 8.8.4.4 for my DNS and rebooted both my server and router/switch. I am still getting slow responses for each plugin when checking for updates. When I open a command prompt in the UI and ask unraid to tell me the dns server it responds fine. Ping works quickly too. I still don't know why the plugins are so slow to check for updates however.
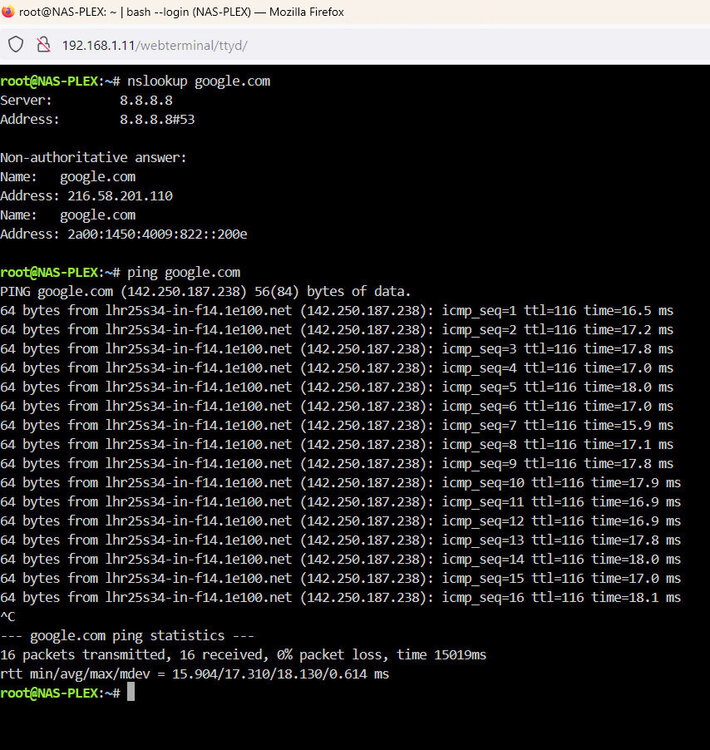
-
Any routers or switches with a mains transformer (wall wart) should be fine to put on a normal 4-way adapter and then put that into the UPS... but you may have to modify the plug of the adapter so that it fits into the UPS.
-
Ignore the gigabit in/out sockets. That is merely intended to be a surge suppressor for your WAN cable to protect your router. Wall to Gigabit In. Gigabit Out to Router WAN. The only cable you need to connect for regular use is the "USB & Serial" one. That allows the UPS to communicate with your server. Be aware that the max load of the UPS is relatively small (550W) and being a discontinued product are you certain the battery is in good condition? I can't answer your second question as I only have the one server on my own UPS.
-
Which speed test docker would you recommend with a simple setup please? I have CA but there are a few to choose from.
-
I stopped the Docker process and edited the Network Settings to point to those OpenDNS addresses and rebooted the server but nothing changed. I entered Safe Mode, started the server and checked the time to update the Dockers and it was unchanged at 24s. I have reverted to the normal unraid mode and rebooted the server. but there is still no change - 36s to check plugins for update.
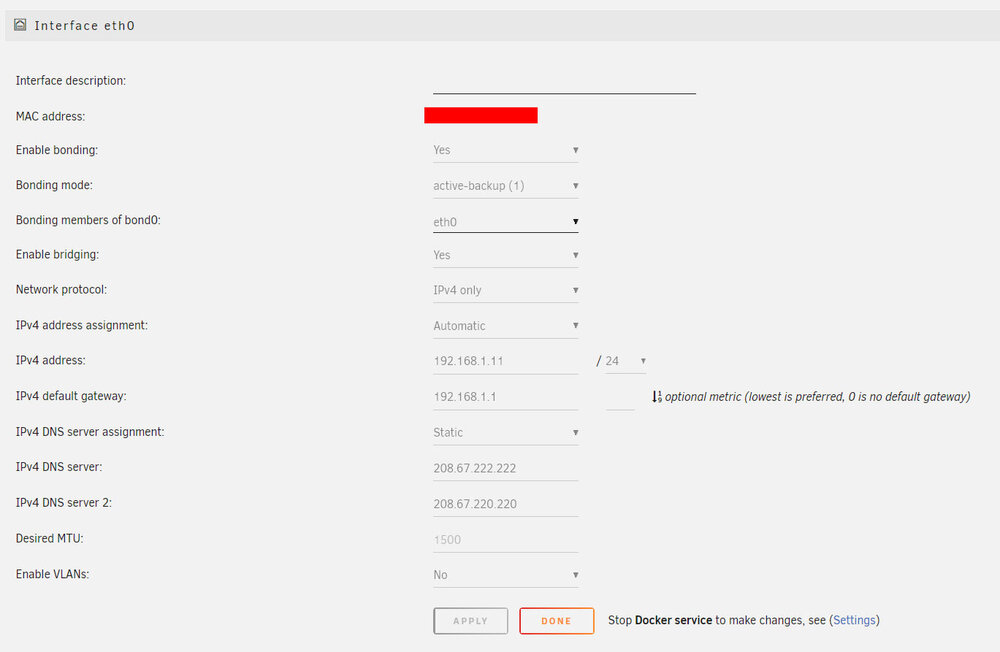
-
When manually Checking for Updates it is taking around 37 seconds to check 6 Plugins and 24 seconds to check 2 Docker Containers. Around a month or so ago it was fast and only took about 5 seconds but something changed during that time and it is consistently slow now. From searching the forum I believe it may be a DNS issue but I don't know how to troubleshoot it. Please could someone check my Diagnostics and advise what I should check or alter please? nas-plex-diagnostics-20240816-1612.zip
-
I will check, thank you. It is an ASUS H370 ITX board on the 2811 bios. I would have to connect a monitor to see what bios options were available but it could be well worth a rummage in the Sleep settings.



