




Jax
Members
-
Joined
-
Last visited
Everything posted by Jax
-
Thanks for all of the assistance. All of my user shares and dockers are back.
-
Thanks for looking into my issue. I've restarted the array in normal mode and it appears that the shares are back, but the docker service failed to start: I've attached the latest diag.tc-nas-01-diagnostics-20211026-0701.zip
-
Hi, I increased the docker .img size from default for no particular reason... just did it because I had the space at the time. Anyway, I just rebooted and it gets even "better". ALL shares are gone now - disk shares AND user shares. Post reboot diag attached. tc-nas-01-diagnostics-20211025-2010.zip
-
SS of the "Shares" tab:
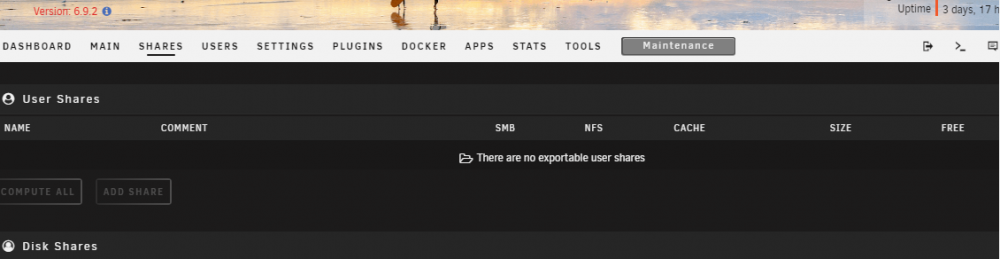
-
Hi, this just happened literally minutes ago. I've been having issues with my Unraid server and a corrupt file system on disk 2 for a while now. I ran the fixdisk utility and it came back with a whackload of files in the lost+found folder. Long story short is that I decided to rather than go through the thousands of files and folders, that I would re-import the data to the array. Anyway, my server has been busy, pulling over 3TB of data in the past few weeks and fast forward to just now when I realized that my cache drive was full. So (stupid?) me started a mover, then went to the share that was the culprit of the full cache and set the cache method to "no". Upon hitting "apply", I was greeted with "Share Deleted" instead of the usual blip and return to the share window with the new setting. I went back and looked at my other shares and they are ALL gone! Only disk shares remain. HELP!!!!! 🙂 Is everything gone? Is there a way to restore the shares/configuration? Diagnostics attached. tc-nas-01-diagnostics-20211025-1346.zip

