




stakacs
Members
-
Joined
-
Last visited
-
I have the same exact behavior as you have stated in this thread. Will be cool to find the solution.
-
/tmp was just a secondary issue I found that I thought was working perfectly before, at least when I set it up and verified it at the time Wiping my cache Is what stopped my crashing as far as I can tell, I didn't have to shut down dockers or anything else. Sorry if that wasn't clear
-
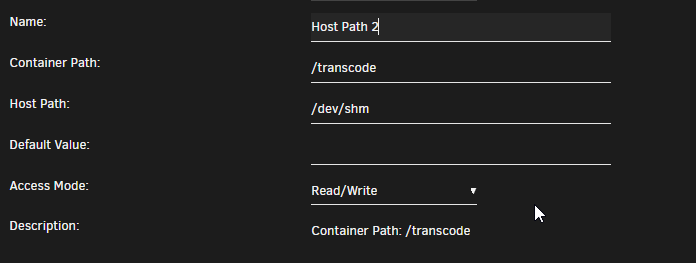
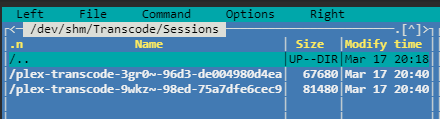
Want to start off with, I am a APE level with Unraid so take it or leave it, tell me I'm wrong ill tell you your write My server was unraveling every 3 to 10 hours, I dug around here on the forum and collected a few thoughts. 1. Cache Pool was new - I think? 2. I was rock solid on 6.8.0 for as long as it was out - Probably 1 million days uptime give or take 3. Someone somewhere was talking about having a corrupted cache after the update I decided to do a cache drive backup, then put the array in maintenance and do the old "Check Filesystem Status" which came up clean and said "Good to go buddy just send it!" then wiped it out and formatted it to XFS (have a 970 Evo Plus 2TB and dont care about pooling) Server has been up and running no problem since, 2+ days with one restart for fun I set up a bunch of plex streams to run overnight on repeat. When I woke up in the AM, I had a few streams drop out, and had alerts that my docker image was nearing full, then back to normal, then back to full again WTF mate??? I then started a few more streams, and noticed my docker image was again growing. I looked at where I had my docker pointed and there were no transcode files...Plex should be using /tmp/PlexRamScratch - which I make each time the array is started WTF mate??? This APE thought that /tmp was ram, maybe its not? smooth brain, but it definitely was not going where I wanted anyway, This nerd on another forum said to use /dev/shm and Boom goes the dynamite - Plex is no longer squatting in my docker img and is filling up ram real nice ❤️ You bye
-
Also having daily crashes - majority of my dockers die as they lose access to shares, which are disappearing server-diagnostics-20210313-1408.zip

