Inshakoor
Members
-
Joined
-
Last visited
-
Thanks for all of the help on this. I ran the check with -L and the disk is now mounted and functional. I did a search for any folders with any variation of lost+found to see if anything was moved there but found nothing. I appreciate the help here.
-
Apologies for the delay on responding to this. Thank you very much for the reply. I ran the check filesystem without the -n and the results are below. It's asking to mount the filesystem to replay whatever log is having a problem. I stopped the array from MM and then I started the array normally, and I still got the same error "Unmountable: Unsupported or no file system" which I don't think counts as a successful mount of the file system. Is ther another way to mount the FS? If I run the repair with the suggested -L switch, how likely am I to cause corruption? I really appreciate your help. Phase 1 - find and verify superblock... Phase 2 - using internal log - zero log... ERROR: The filesystem has valuable metadata changes in a log which needs to be replayed. Mount the filesystem to replay the log, and unmount it before re-running xfs_repair. If you are unable to mount the filesystem, then use the -L option to destroy the log and attempt a repair. Note that destroying the log may cause corruption -- please attempt a mount of the filesystem before doing this.
-
Good evening, Earlier this week I hopped on Plex (hosted on Unraid) and noticed some shows were listed as Unavailable. I browsed to their paths on the Unraid share and sure enough, the files weren't there. I bounced Unraid and they were back. I figured I'd look at the logs the next day (it was late). The end of the week got busy and I forgot about it. During this time, a parity check started on schedule and stopped as it does for a nightly backup (this has been running for months) but due to the process taking too long, the parity check was canceled. Later that day (today), I go to watch another show tonight and same thing: some shows were listed as Unavailable and the files were missing on the share. This time I look at the Array Devices (5 18TB drives, 2 parity and 3 data) and disk 2 is showing "Unmountable: Unsupported or no file system". Disk 2 had about 13/14tb of 18tb used. Been running for some time (8-12 months). I searched the forum for similar issues and found a few but they're not exactly the same, or at least I didn't think they were. I'm a bit nervous since this morning's parity check didn't complete. I'd greatly appreciate some guidance on next steps with this. Below is a snippet from the syslog and attached is the full anonymous diagnostics. Thank you. Oct 1 21:51:39 URFS kernel: XFS (md2p1): Corruption of in-memory data (0x8) detected at xfs_trans_cancel+0xd6/0x114 [xfs] (fs/xfs/xfs_trans.c:1098). Shutting down filesystem. Oct 1 21:51:39 URFS kernel: XFS (md2p1): Please unmount the filesystem and rectify the problem(s) Oct 1 21:51:39 URFS kernel: XFS (md2p1): Failed to recover leftover CoW staging extents, err -5. Oct 1 21:51:39 URFS kernel: XFS (md2p1): Ending recovery (logdev: internal) Oct 1 21:51:44 URFS kernel: XFS (md2p1): Error -5 reserving per-AG metadata reserve pool. Oct 1 21:51:44 URFS root: mount: /mnt/disk2: can't read superblock on /dev/md2p1. Oct 1 21:51:44 URFS root: dmesg(1) may have more information after failed mount system call. Oct 1 21:51:44 URFS emhttpd: shcmd (116): exit status: 32 Oct 1 21:51:44 URFS emhttpd: /mnt/disk2 mount error: Unsupported or no file system Oct 1 21:51:44 URFS emhttpd: shcmd (117): rmdir /mnt/disk2 urfs-diagnostics-20231001-2154.zip
-
I know it's been a while but just wanted to chime in that this worked for me as well. Got the container ID, killed both instances that were running, went back to the GUI, stopped the container (deluge), and then did a force update. Worked great. Thank you!
-
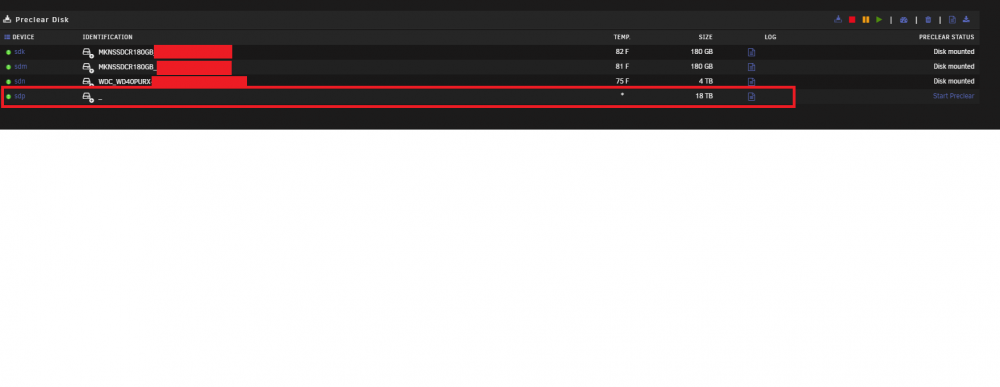
Good day, I just purchased 3 18TB WD HGST's (came with Molex to SATA power adapters to deal with Power Disable) so I can start replacing my 4TB WD Reds. The goal is to start with my 2 parity drives and then add the third for data (then pull out 4 of the 4TBs) as I am crazy low on space. My cached drives still have some large movie files on them because no single data drive has enough space for a file of that size to be move to. I'm using 2 SAS controllers with 8 ports each. I am using 15 ports (2 parity, 8 data, 2 cache, 3 for docker and VMs) currently and had one port free. On December 18th I hooked up the first 18TB drive, downloaded the Preclear plugin and kicked it off. It got through pre-read without issue but this morning I woke up to an email saying zeroing failed. In Unraid, I can't see the drive in the Dash or in Main but I can see it in Preclear, although it has very little data associated with (see attached). I'm not new to Unraid but have been lucky with very few problems and this is my first preclear failure. The logs show Dec 20 05:35:08 "No space left on disk" referencing the 18TB drive at '/dev/sdp'. I'm at a loss here since I can't see how it's out of space during a preclear, unless the drive loss connectivity during that time and this error is how it manifested the issue. I have 2 more of these to do and, as we all know, it takes quite some time to complete. I don't have any smart data since the drives are connected to SAS. I was thinking of rebooting the server and seeing if the drive shows back up and then using the CLI to pull smart info but I don't want to reboot yet in case I lose logging or anything related to this issue. I'd appreciate any assistance as to what might be going on with this process or any advice on what next steps to take. Thank you in advance. Attached are the preclear log .zip, anon diagnostics .zip, and a screenshot of the disk as seen in Preclear currently. URFS-preclear.disk-20211220-0755.zip urfs-diagnostics-20211220-0754.zip