




johmei
Members
-
Joined
-
Last visited
Everything posted by johmei
-
I'm gonna go that route then for sure. Thanks very much for the input!
-
So I guess that means doing this over SMB really isn't ideal....I'll give a search and pursue that route.
-
I've been running my torrents such that the client runs on my primary system, and I save the actual data on unraid via an SMB share via a network mapped drive (that is to say, when I open a torrent and qBittorrent asks me where I want to save the actual data, I choose my unraid SMB share that is mapped to a drive letter). I'm starting to think....maybe this isn't such a great idea. Am I on the right path with that thought? If I am...what would be a suggested alternative method for torrenting on unraid? 🤔 Thank you kindly!!
-
Thank you!!
-
Thanks for the explanation there! And that's a really good point. While I was loosely throwing around the term formatting incorrectly, the one thing I do know is that formatting will always obliterate the data (or at least the index) and in this case, it doesn't matter (the clearing would have destroyed any data already). But I can see where if I was replacing a drive, and it finished rebuilding and this popped up, I could have made a mistake. So I feel better about it now! Thanks again so much!
-
Also, I feel REALLY stupid. The option to format them is RIGHT there in front of my face. I jumped to making a post WAY too fast which I usually avoid doing but....ughhh...the information is on the web, readily available, and I didn't bother checking. I am so sorry. 😕
-
My mistake; I used to do full formats that would take hours so that's where my mind was. Awesome, thanks! Could you elaborate on what these log entries mean? I'd like to understand them a bit better. Thanks again!!
-
Sometime last year or the year before I purchased 3 x 12 TB drives. I made two my new parity drives, and added the third one as a data drive. This year I discovered 18 TB drives were now the same cost as the 12 TB drives I purchased previously, and 12 TB drives were not that much cheaper, so I bought 2 x 18 TB to replace my 12 TB parity drives. All went well with that, but when I tried to add my 12 TB drives to the array as data drives I was greeted with that wonderful error after it spent over 12 hours formatting them both. So....things that are different; All my drives were previously connected to an LSI SAS2008 controller. It has a capacity of 8 SATA drives and since I just added 2 beyond that, my parity drives are now on the integrated controller, X370 Series Chipset SATA Controller. Those seem to be working fine and without issue. In fact, all the 12 TB drives aren't even on a different physical cable than they were previously...and I've heard that a bad cable can cause this issue. I've attached the Diag here. I could try again but I wanted to run it by some experts before I try again since I'm assuming if I try to add them again, it'll clear the drive again and will take another 12 plus hours to do so. Thanks so much! johnsnas-diagnostics-20230215-0922.zip
-
Hmmm....well I didn't change anything, but I did restart the entire server and it seems to be working? I guess it wasn't captured properly when it last started up *shrugs*. I still don't see the Nvidia audio in the device manager, but I don't need it so as long as that won't cause issues...I guess I'm okay
-
I'm at a complete loss here. I have an MSI X370 Gaming Carbon pro with a Ryzen 5 5600G. I was having trouble getting my NVIDIA card passed through but thanks to spaceinvader one's advanced GPU passthrough video, I got it working along with audio. Great! But I wanted to use the onboard realtek audio controller that the manual swears up and down it has (even though you won't see any mention of realteck in the below PCI device) but while I got it working without issue just a few days ago, I went to bootup my VM today and was surprised and confused to see no audio controller. I had to do some fiddling with the XML file for the video card to work, but I didn't for the audio....but now I'm guessing there is more I might have to do? I'm including my VM XML file below as well as my PCI Devices and IOMMU groups. Does anybody have any idea what might be going on? Please let me know if you want me to provide any specific information as well. Thanks so much!
-
Yeah, I'd definitely prefer to just let it build without writing to it in that case. Thanks!! Got ya. I'm gonna play it safe from this point forward!
-
Also, the extended smart test passed without any issues! So I'll go ahead and rebuild parity when I get home onto my new 18 TB...should I still refrain from writing to my server while rebuilding even if it's only 1 of the 2 parity drives?
-
All sounds good, thanks! I'll still probably replace it one at a time because I'm paranoid, but it's good to know it would be fine either way! Thanks again!
-
Is that general rule about hotswapping true even if the MB bios has settings for hotswap support? I still would rather not risk it in the future so I'll probably abandon that regardless, but I'm just curious. I suppose if it has to be rebuilt anyway...I might as well have it rebuild onto the new 18 TB drive? I assume I should replace each parity drive only one at a time to reduce the risk of data loss should something go wrong? Thanks!! johnsnas-diagnostics-20230130-1159.zip
-
I currently have 2 x 12 TB parity drives, 1 x 12 TB data drive and 3 x 4 TB data drives (4 TB drives are by far the oldest). I am wanting to replace both 12 TB parity drives with 18 TB drives and either add the two 12 TB parity drives to the array as data drives, or replace two of the 4 TB drives with the 12 TB drives. I wanted to preclear my 18 TB drives so I plugged one into my system (I have a dock at the top that plugs into the MB, the other drives are all on an "LSI SAS2008 PCI-Express Fusion-MPT SAS-2 [Falcon] (rev 03)" controller)....the very second I did this, I received the follow errors in my notification bar. So I'm running an extended SMART test on the parity drive now but I just can't imagine there is any connection to plugging in that drive...is that possible or is it a coincidence? I have the errors below from the notification archive. 29-01-2023 20:23 Unraid array errors Warning [JOHNSNAS] - array has errors Array has 1 disk with read errors warning Parity disk - ST12000VN0008-2PH103_ZS80483R (sdc) (errors 2048) 29-01-2023 20:23 Unraid Parity disk error Alert [JOHNSNAS] - Parity disk in error state (disk dsbl) ST12000VN0008-2PH103_ZS80483R (sdc) alert Thanks!
-
I found the something. Apparently Crashplan Pro decided to dump 400 plus GBs of files in the appdata/CrashPlanPRO/conf/tmp directory. 😕 took some digging to find it and that definitely explains things. I used MC to delete them and the space is back. I also did an extended smart test and it said everything checked out. So I'm guessing everything is good, I just need to figure out wth Crashplan did that and stop it from doing that again. Thanks a ton for the help and reassurance on this!! It's very much appreciated!
-
That's the weird thing though....I have the mover scheduled for every week and I know I don't load up 500 GB or even close in a week. This has never happened before and I tried to manually invoke the mover and nothing. And when I try to view the pool....there's no data on there other than about 10-20 GB worth for my Docker Plugins and that includes a 10 GB for the docker image, at least not that I can see. I have no idea how it is saying there is no space on it. It makes no sense. It's never gotten even remotely close to filling up since I first fired this system up about 6 or 7 years ago. Any thoughts?
-
When you set something up so long ago...you really forget so many things 😕 I'm not exactly sure what information is needed, but I'll start with the Diag File. In my Dashboard, one of my cache drives in the pool is stating it has an error. I guess that has something to do with the issue but I thought the point of having a mirrored cache drives was that when one breaks, the other continues to function but that doesn't seem to be the case. I need to take care of this and I'm worried about losing data that is still on the cache that hasn't been moved yet. The cache is just acting weird and I'm worried about losing data, otherwise, I'd just be reading the manual and messing with stuff myself. Please advise and/or ask follow up questions as I know I left important information out. Samsung_SSD_850_EVO_500GB_S21HNXAG941287N is the first cache drive and Samsung_SSD_850_EVO_500GB_S21HNXAG643841J is the second cache drive (the one with the errors) Thanks so much johnsnas-diagnostics-20220219-0422.zip
-
Thanks very much for confirming this! While I hope there won't be a next time any time soon, I won't do maintenance mode if I have to again just in case I need access to my files!
-
I don't know what happened (I only know it was related to plugging in my old bad drives to try and pre-clear/test them again just out of curiosity) but unraid decided that my first parity disk was bad or something 🙄 (it's brand new and went through no less than 1 full preclear) so I learned a lesson there. But I started the array in maintenance mode and hit sync with the intention of it helping to shave some time off, without realizing I actually needed to access some data before the 17 hours that I'd have to wait without mounting the array. Is there a safe way to not have to start the parity sync over and still mount the array? Or will I have to start over? And if I do, how do I do that safely? I assume I would simply cancel the parity-sync, and then start the array only not in maintenance mode this time? Thanks so much!
-
Thanks so much for the reassurance on that! And for everything! I couldn't have confidently done this without your guidance and feedback! And thanks to everybody else also that chipped in and helped me on this issue. I greatly appreciate it! You're all awesome!
-
All the other drives did finish without errors luckily. It seems like this was a really close call. I'll be paying more attention to this stuff in the future and setup some alerts as trurl suggested. But I am concerned because the now failing disk was previously one of the two parity disks. Should I be concerned and if so, how can I verify the integrity of my data short of checking every single file in it's entirety?
-
Well it finished re-building and seemed to be successful but well....My Previous Parity 1 drive (RXYD) is my new Disk 1 and before I did the parity swap (the copy) I did an extended smart test on every drive and every drive (except for the known bad drives, P23S and RYB9) passed. After everything re-built, I received a read warning again for Disk 1 so I did an extended smart test again on all the drives in the new array and RXYD failed with 30% left (see smart log below). I went ahead and included a full diagnostics in case you wanna take a look also. The other extended tests are still running but it looks like I'll have to replace another drive as well so soon 😕 johnsnas-smart-20211018-1225.zip johnsnas-diagnostics-20211018-1809.zip
-
Okay it just did that because one disk was a bit behind. I'm now at the step where I have to start the Array but it's not exactly as described in the manual. The manual states, "The Start button will now be present, and the description will now indicate that it is ready to start a Data-Rebuild. Put a check in the Yes I want to do this checkbox (older versions: Yes, I'm sure), and click the Start button" But it doesn't say that it's ready to rebuild data. It's talking about expanding the file system of the data disks first and I don't see a check box. I'm assuming it's fine to just hit start and it will still do what it's supposed to, but just in case, I want to make sure so I've included a screenshot below. Both Parity drives have a green dot on them (the new 12 TB drives) just since that's cut out at the top. Thanks!! Well crap...things are not going as per the manual/instructions and I don't know what to do now (see attached image). I'm confused because it's still copying, but says it's not ready and that the content is being reconstructed? But that part isn't supposed to happen until after it's finished copying, right? So what is it doing? It shouldn't be reconstructing anything yet, right? Not sure what to do. MYR4 is one of my old parity drives also, I took a screenshot of everything before I started so that I would know which drives were where.
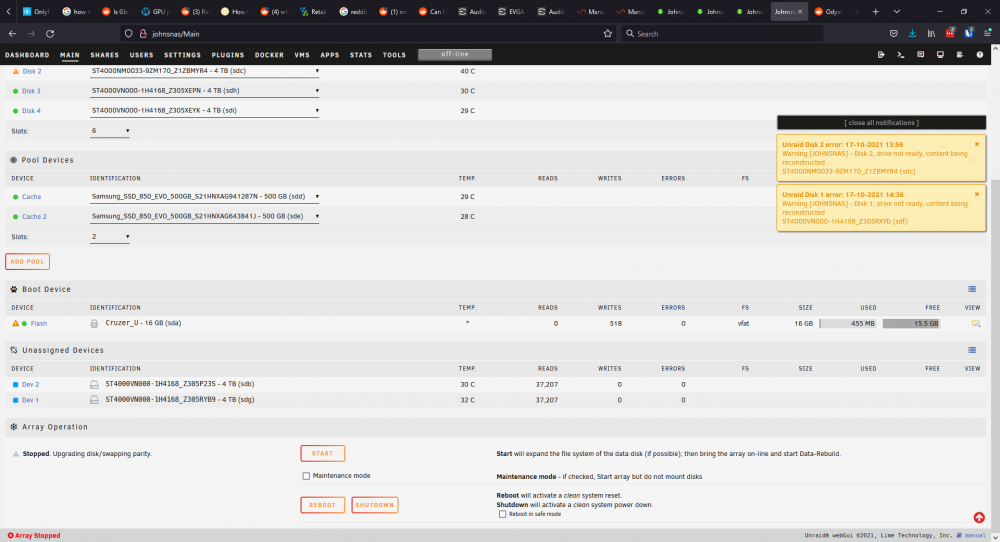
-
Awesome, thanks so much for verifying that! And thanks for the heads up/tip on that. I definitely wasn't planning on rebooting or powering down, but it's good to know it would have to start over anyway! I'll get this entire thing started as soon as these drives finish pre-clearing!

