




chooch
Members
-
Joined
-
Last visited
-
Awesome and I will give that a try. I like having 2 separate movie libraries in Plex so that way the DVD's and BLU-RAY's are not mixed together. I rarely watch anything in DVD anymore due to the lack of quality however some of the movies have not been made in Blu-ray yet so that is the best format I have for now.
-
My apologies for having Movies and movies written in my previous posts I changed everything to all capital letters so that way I never make that mistake. Here is the actual folder structure of my setup along with the docker mapping and it worked: /tv/mnt <-- /disk1/TV SHOWS/ /movies/disk1 <-- /mnt/disk1/TV SHOWS/ /movies/disk2 <-- /mnt/disk2/MOVIES/BLU-RAY/ /movies/disk3 <-- /mnt/disk3/MOVIES/BLU-RAY/ /movies/disk4 <-- /mnt/disk4/MOVIES/BLU-RAY/ /movies/disk5 <-- /mnt/disk5/MOVIES/BLU-RAY/ /movies/disk6 <-- /mnt/disk6/MOVIES/BLU-RAY/ /movies/disk6 <-- /mnt/disk6/MOVIES/DVD/ /config <--> /mnt/disk6/Docker/appdata/plex So if I just choose /mnt/user/MOVIES/BLU-RAY as the host path that will grab all files from disk2 to disk6 with the BLU-RAY folders?
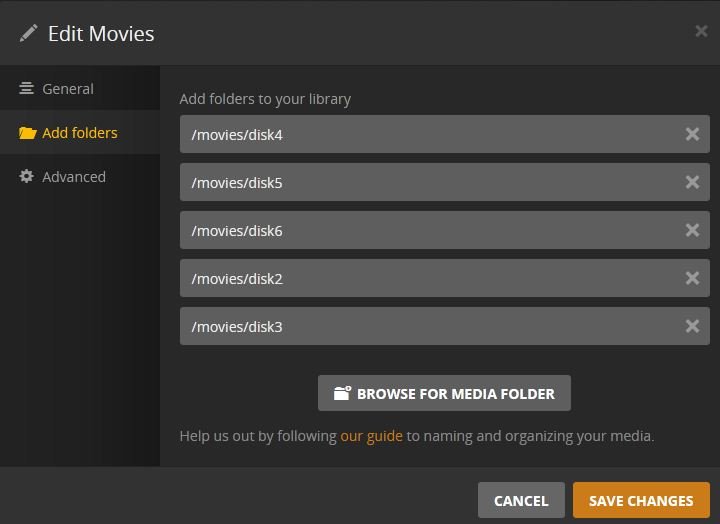
-
I don't think I actually have a host path of /mnt/user/Movies/Blu-ray since I never setup my unraid to have user share folders. I uploaded a picture of all my folders: My goal is just to add all my media from the different disks to Plex. My media is simple and setup as: /mnt/disk1/movies/blu-ray /mnt/disk2/movies/blu-ray /mnt/disk3/tv So I am thinking I just need to have 3 individual container paths for each of those and I will be OK.
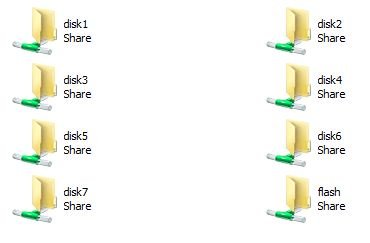
-
Thank you very much and I will read that faq. The one thing I noticed is the Plex docker did not like me using the same container path for 2 different hosts. For example: host :/mnt/disk1/Movies/Blu-ray with container path /bluray host :/mnt/disk2/Movies/Blu-ray with container path /bluray That gave an error and removed the docker from my unraid. So I guess going forward I will just name the container path to match the disk like /bluray1 and /bluray2. My initial concern with setting the container path to /bluray instead of /mnt/disk2/Movies/Blu-ray is I thought it might try to create that user share /bluray on my server. However now that I understand container path is basically the name my plex app sees that makes more sense.
-
What is the difference in Container Path and Host Path? For example if I am adding movies from a location /mnt/disk2/Movies/Blu-ray do I want both Container path and Host path to be the same? My movie collection did show up in PlexUI when I made them the same so I figured I did something correct however just wanted some clarity on what each of those paths are for and if they should be identical. I do not have user shares setup on my unraid so there is no "movie" folder that spans across all the disks and I manage my movies disk by disk. I apologize in advanced if my questions are dumb however I have been using unraid for over 10 years now but never had any dockers installed. I tried searching for the difference between the two paths however wasn't able to find any specifics. If this is the wrong place to post then please let me know where is more appropriate since I am a newbie when it comes to dockers and Plex.
-
Until you experience issues, leave it be. Many people experience performance issues with Reiser, ranging from slow writes to complete lockups. If your system is running well, no need to switch. That is the reason I decided to convert to XFS. Normally it would take me around 20 minutes to copy a 20GB file to my server and recently it was taking taking a few hours because my disks were getting full. I read through all the posts and am in the process of converting to XFS. I am a very casual user and up until a week ago was running v5 of unraid. There seems to be a lot of different approaches and I ended up following RobJ's instructions for the most part with a few minor changes.
-
Thanks for the response and I appreciate the tip about formatting instead of --delete. Part of the reason I am doing it this way is that I physically have the drives from top to bottom on my server in order of Parity to disk6. They are front loading so I like to know the physical locations in case I would need to replace a drive. I don't use user shares and have different data on each disk (disk1 TV, disk2 Bluray, disk 3 DVD, etc.). So I wasn't sure if I could simply reassign them afterwards to correspond to the physical locations on my server if I did the method you mentioned earlier. Also, since disk 6 is new and a different model that will eventually become my parity drive once I am done with the coping. Then my old parity will become disk4 and I will be back to a 5 data drive server. I was worried I would mess something up with all the reassigning and figured while longer this would be a safe approach. I know there are easier ways to do this and you had a really good example earlier. That is where I seen to use rsync -avPX. But I barely make any changes to my server and up until this week was running v5. I just use mine to back up my media and the only reason I started making changes was because the extremely slow disk speeds of disk3 is making me go from RFS to XFS. The disk is nearly full and someone mentioned earlier RFS can be very slow when full. Time is really not an issue here and I was just trying to take the simple approach for someone who is not an expert with unraid and didn't want to mess anything up.
-
Thanks. Would it look something like this? rsync -avPX --delete /mnt/disk2/ /mnt/disk6/
-
Thanks for the responses trurl and garycase. I had another question and was hoping someone could help. I am currently moving the data from disk 1 -> disk 6 (new disk) using rsync -avPX. Then I will format disk1 as XFS and move the data back from disk6 using rsync -avPX. Next I want to do the same thing for disk2 and move the data to disk6 and then back after formatting to XFS. disk1 (RFS) -> disk6 -> disk1 (XFS) then disk2 (RFS) -> disk6 -> disk2 (XFS) My question is do I need to delete all the data on disk 6 before using the rsync -avPX from disk2? Or will that just copy over the existing data on disk 6 (disk1's old data from first transfer)?
-
This is the approach I am taking. I know it will take longer but I am not really in a rush. Plus I don't trust myself with all the reassigning, My current setup is: disk1: reiserfs 5TB disk2: reiserfs 5TB disk3: reiserfs 5TB disk4: reiserfs 2TB disk5: reiserfs 2TB disk6: XFS (Newly precleared drive 5 TB) I plan on using disk 6 as the temporary drive and will copy the data from disk 1 to it, reformat disk 1 to XFS, then copy the data back from disk 6. Then rinse and repeat for each other disk. Is this an OK approach? I started tonight using rsync -avPX /mnt/disk1/ /mnt/disk6/ When I added disk 6 it formatted to XFS since that is my default format and what I want all new drives to be. Is that OK? The reason I ask is because RobJ menioned is should not be XFS: My current copy rate using rsync seems to be around 36 MB/s. Is that typical? My most recent parity check was around 120 MB/s and my most recent preclear results were: Pre Read (105 MB/s), Zeroing (136 MB/s), and Post Read (48 MB/s)

