

tidusjar
-
Posts
53 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by tidusjar
-
-
38 minutes ago, E-ManN said:
thanks tidusjar ... that was it ... in OMBI radaar settings I set the default availability to "in cinemas" ... working now. 🙂
as for the DB setup ... I'll try again to get the other 2 OMBI DBs on the Maria DB server.
Has anyone got all 3 of thier OMB DBs running on maria DB server under MYSQL .. if so I would like to pick your brains on the setup.
thanks,
E
All users that are running a MySQL setup that i've spoken to are running all three databases under MySQL and not a split.
The migration guide only really will migrate you from all 3 SQLite databases to MySQL and not just two. It might be worth reaching out on the Ombi discord.
-
As I mentioned previous I wouldn’t recommend running Ombi with different databases. But that’s your choice.
regard radarr, check your log file, ensure you have enabled it in the settings and ensure you have set a default availability
-
2 minutes ago, E-ManN said:
HI Guys,
lots of docker update this morning on my URAID SErver in lncluding OMBI, Plex, Sonarr & radarr. I updated all and now OMBI keeps gettign stuck at the setup Wizard. Not sure what is going on here as prior to the updates OMBI was setup and working. When I try to launch the OMBI GUII is quikyl displays the OMBI LOGON screen before going into the wizard .... nto matter what I enter in the wizard it keeps looping back to the starting page of the wizard.
I've searched the NET but have not seen a sloution to fix this. I woul really hate to have to start all over from scratch as my OMBI server has a maria DB server backed ... lots of work to start all over again.
- Plex version V# 4.76.1
- Sonarr V# 3.0.8.1507
- Radaar V# 4.1.0.6175
- OMBI V# 54d8..f74a - not entirely sure as I cannot luanch it ... this version # I grabbed from the update e-mail alert from my UNRAID server
- MARIA DB V# MySQL version: 5.5.5-10.5.16-MariaDB-log
any help or suggestions would be much appreciated.
thanks,
E
are you sure Ombi is looking at the correct MySQL database? Maybe jump on the Ombi support discord. Might be easier to help there -
And it's happened again this morning, docker containers are failing to start (and have stopped). New drive I guess?
-
11 minutes ago, JorgeB said:
Jun 14 14:41:57 Server kernel: ata7.00: disabledIt dropped again, did you replace both cables? Power and SATA. If that doesn't help try a different SATA port or replace the device.
I only did the SATA cable. I've now switched SATA ports and different power cable. It now seems to be working, i'll check over the next few days
-
 1
1
-
-
9 minutes ago, JorgeB said:
Jun 14 08:00:08 Server kernel: ata7.00: disabledCache device dropped offline, check/replace cables and if it comes back post new diags after array start.
Just replaced the cable, started back up and things are running for now. But like i mentioned it keeps happening.
Update: Actually things are behaving quite strangely like nothing can write to the cache now -
Any sort of tests I can do to see what's wrong?
-
After restarting I now have the following:
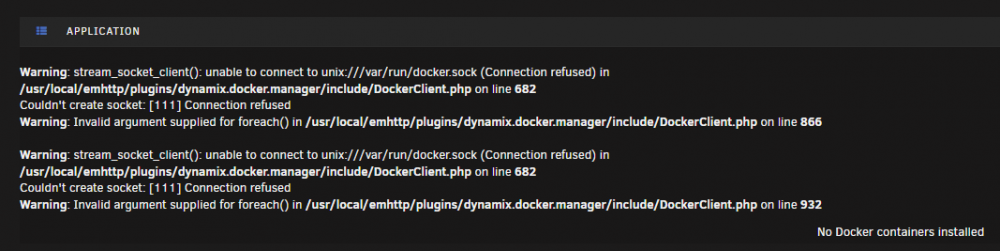
Server logs are attached for this instance
-
So this issue has been happening on and off for the past few months.
What seems to happen is that all of a sudden my docker containers would just become unresponsive and not work. Stopping or Restarting the containers would show an error message in the UI saying something along the lines of 'Service failed to start' with no other information.
Sometimes a reboot of the server would fix this, other times i'd need to disable docker, delete the `docker.img` and reinstall the containers.
Today this has happened again and seems to be becoming more frequent, so i'm hoping someone is able to point me in the right direction of what I can do to resolve this.
Server diagnostics are attached, currently the `Docker Service failed to start.` at this point i'm probably going to have to delete the docker image and start again.
If there is any other information I can provide please let me know.
-
1 minute ago, elcapitano said:
June 3'rd and my setup is still sending out e-mail with just username/password - hope it continues.
I think it’s just they have enforced the use of App Passwords for this sort of thing
-
1 minute ago, elcapitano said:
Anyone using gmail with ombi?
We might have a problem after May 30 . .
We will need to use an e-mail client or app that supports OAuth 2.0 (https://oauth.net/2/) as using the username/password combination will no longer be sufficient. https://support.google.com/accounts/answer/6010255
Thanks for the headsup!
-
19 minutes ago, Emanuel87 said:
anyone? is there no support for the Ombi container?
There is, I don’t always see the messages on here.
I suggest you jump on the Ombi discord and we can try and assist you with your proxy issue
-
39 minutes ago, hikewv said:
Ombi affected by log4j?
Nope!
-
13 minutes ago, Littleolme said:
I've recently reinstated my Plex server after having it in mothballs for 9 months due to a move. Now that it is back up and running, and I've updated everything, Ombi seems to have an issue where I must restart it every other day or so because it stops responding to requests. Everybody can login, you can search for videos, but upon submitting a request Ombi never responds back that the request was submitted and it never shows up as requested. A stop and start of the container fixes the issue. Is this a known issue?
Looking at the log I see a few red highlighted lines: "Microsoft.Data.Sqlite.SqliteException (0x80004005): SQLite Error 5: 'database is locked'."
Hey,
You have run into a limitation in SQLite, Ombi is a very DB heavy application and SQLite is not really meant for websites/apps.
What i'd recommend you do is migrate over to using MySQL as a database for Ombi (you can easily spin up a MariaDb docker container)
There is a guide on the docs website, also see here: https://docs.ombi.app/info/alternate-databases/#why-mysql
-
 1
1
-
-
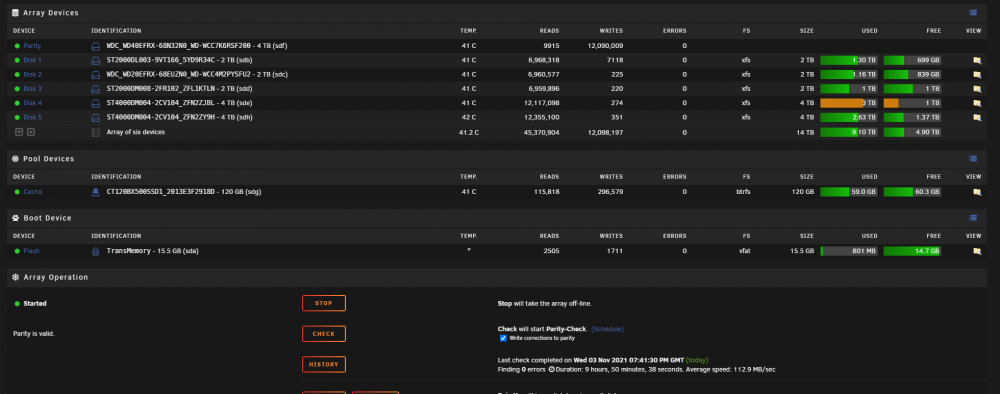
1 minute ago, trurl said:
Unassign, reassign was unnecessary. I mention that because if you had started the array with it unassigned, it would have become disabled and start rebuilding it after you reassigned it.
Ok that's good to know
-
Nope, the only shares present are my ones
-
Oh wow, I unassigned the drive, re-assigned it and now it's mountable and everything seems normal?

-
Done, yeah it was XFS
I had to use the `-L` option as it was complaining
Phase 1 - find and verify superblock... Phase 2 - using internal log - zero log... ALERT: The filesystem has valuable metadata changes in a log which is being destroyed because the -L option was used. - scan filesystem freespace and inode maps... - found root inode chunk Phase 3 - for each AG... - scan and clear agi unlinked lists... - process known inodes and perform inode discovery... - agno = 0 - agno = 1 - agno = 2 - agno = 3 - process newly discovered inodes... Phase 4 - check for duplicate blocks... - setting up duplicate extent list... - check for inodes claiming duplicate blocks... - agno = 1 - agno = 2 - agno = 0 - agno = 3 Phase 5 - rebuild AG headers and trees... - reset superblock... Phase 6 - check inode connectivity... - resetting contents of realtime bitmap and summary inodes - traversing filesystem ... - traversal finished ... - moving disconnected inodes to lost+found ... Phase 7 - verify and correct link counts... Maximum metadata LSN (213:549485) is ahead of log (1:2). Format log to cycle 216. done -
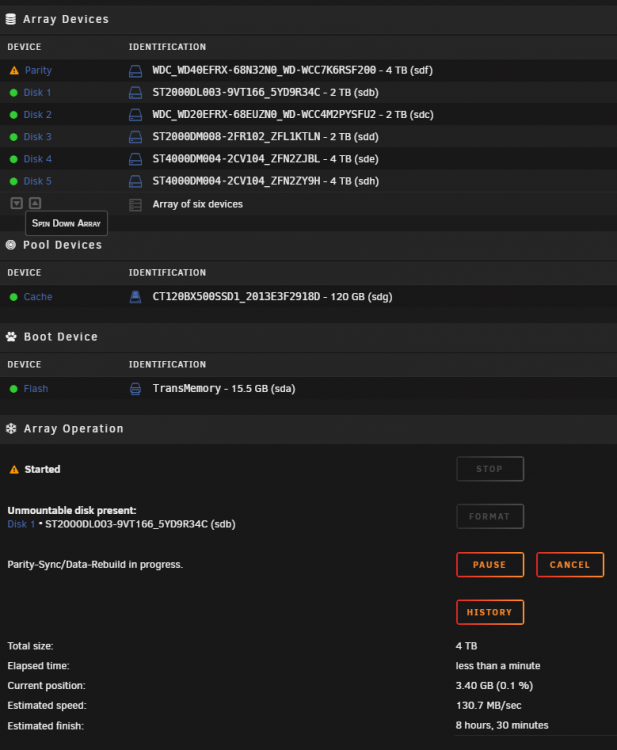
Sync finished with 0 errors. For some reason there's no File System Check available for disk1 now. The option is completely missing. It appears for all of the other disks
Here's a screenshot of Main
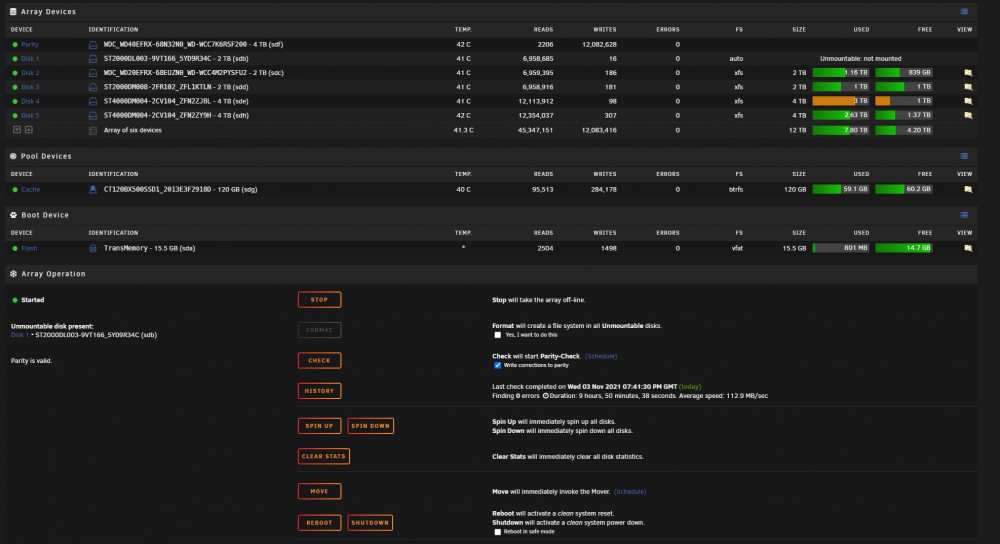
-
3 minutes ago, JorgeB said:
Once the sycn finishes run it again without -n or nothing will be done, did disk4 mount correctly?
Ok will do,
As far as I'm aware disk4 is now in a correct state and no longer emulated too
-
23 minutes ago, JorgeB said:
No, check filesystem.
-Tools -> New Config -> Retain current configuration: All -> Apply
Then start array to begin a parity sync (or check parity is already valid before array start and then run a correcting check).
Filesystem check output:
Phase 1 - find and verify superblock... Phase 2 - using internal log - zero log... ALERT: The filesystem has valuable metadata changes in a log which is being ignored because the -n option was used. Expect spurious inconsistencies which may be resolved by first mounting the filesystem to replay the log. - scan filesystem freespace and inode maps... - found root inode chunk Phase 3 - for each AG... - scan (but don't clear) agi unlinked lists... - process known inodes and perform inode discovery... - agno = 0 - agno = 1 - agno = 2 - agno = 3 - process newly discovered inodes... Phase 4 - check for duplicate blocks... - setting up duplicate extent list... - check for inodes claiming duplicate blocks... - agno = 0 - agno = 1 - agno = 2 - agno = 3 No modify flag set, skipping phase 5 Phase 6 - check inode connectivity... - traversing filesystem ... - traversal finished ... - moving disconnected inodes to lost+found ... Phase 7 - verify link counts... No modify flag set, skipping filesystem flush and exiting.And Parity sync is now running
-
3 minutes ago, JorgeB said:
Don't think there would be much point in rebuilding disk4, since disk1 is corrupt a rebuilt disk4 would also be corrupt, best bet is to do a new config to re-enable disk4, as for disk1 you can run a filesystem check but most likely there won't be much of use there.
Ok
So replace disk1 then?
How do i do a new config to disk4? Is there a link on the wiki anywhere? -
I do not currently have any spare. Do we think disk 1 is dead?
-
Here you go
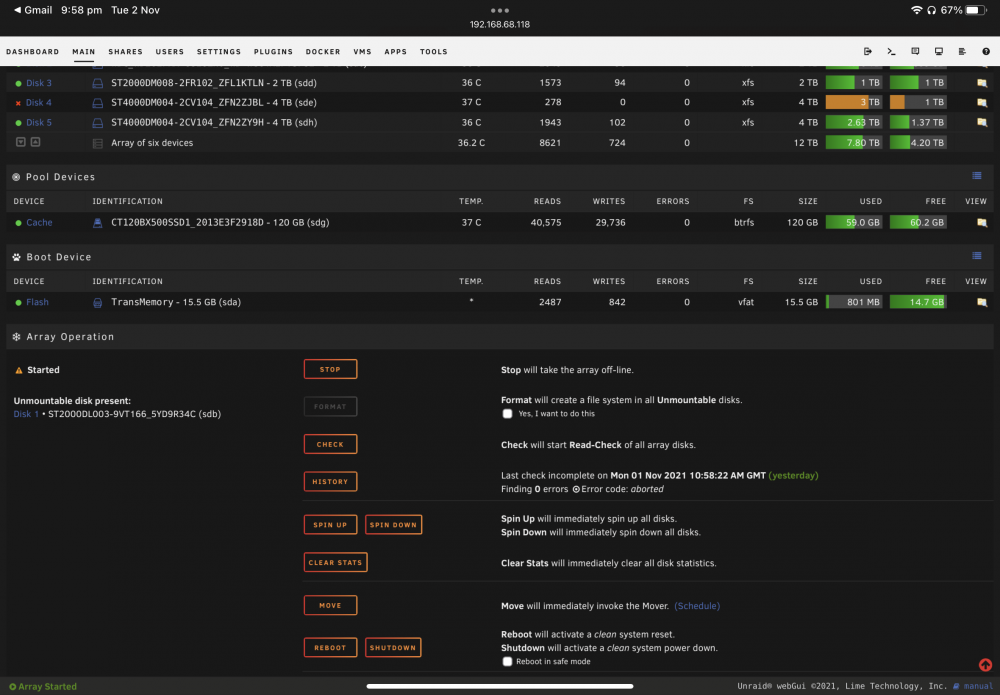








[Support] Linuxserver.io - Ombi
in Docker Containers
Posted
this sounds like the issue people have when they encounter the SQLite database locking. But there should be some logs in the logs folder that mention that Ombi cannot access the database.