stuckless
Members
-
Joined
-
Last visited
-
Thanks I'll rebuild. This is the second time in 2 months that I'll be rebuilding the parity drive. Wish I fully understood why this was happening Thanks for help. Much appreciated.
-
I adjusted all the sata cables and power cables and rebooted. here's the new log. The drive is still disabled. Does that mean that the system thinks it is physically not there? mediaserver-diagnostics-20230109-1736.zip Thanks
-
By a power/connection issue, do you think it could be power supply issue? Bad cable? loose cable? I'll open up the box and reseat all the power connectors, and then re-run a diag and post it here. Thanks, Sean.
-
The SMART shows OK, and the last parity check (7 days ago) showed OK, but now the drive is showing READ errors and is disabled. About a month ago, I noticed the same issue, and I removed and then re-aded the partity drive and it added/rebuilt fine, but now I'm back to this again. Is this a bad disk? Something else goin on? Hopefully someone smarter than me can see something in the logs. Thanks for any help. mediaserver-diagnostics-20230108-0806.zip
-
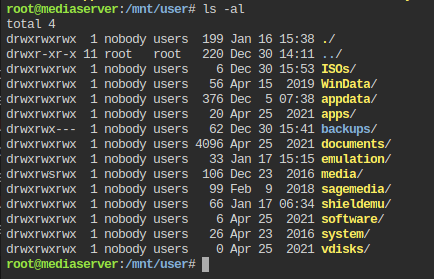
I realize this is an old topic, but I wanted to chime in with an alternate fix for this. First off, it's worth noting that on Ubuntu at least, this the default color for a directory that is set with world writeable permissions (ie, anyone can write to it). And while it's hard to read, on Ubuntu, it's easier to read than the unRAID web console implementation. My guess is that in linux they really want you to know that this folder is basically insecure. While you could use the color=never option, I actually like having color, just not this color. So this is what I did. 1. I made a backup of /etc/DIR_COLORS 2. I edited the /etc/DIR_COLORS (nano /etc/DIR_COLORS) and changed the lines STICKY_OTHER_WRITABLE 30;42 # dir that is sticky and other-writable (+t,o+w) OTHER_WRITABLE 34;42 # dir that is other-writable (o+w) and not sticky to STICKY_OTHER_WRITABLE 01;33 # dir that is sticky and other-writable (+t,o+w) OTHER_WRITABLE 01;33 # dir that is other-writable (o+w) and not sticky This file talks about what those numbers are, and they explain them in the comments before this section. # Below are the color init strings for the basic file types. A color init # string consists of one or more of the following numeric codes: # Attribute codes: # 00=none 01=bold 04=underscore 05=blink 07=reverse 08=concealed # Text color codes: # 30=black 31=red 32=green 33=yellow 34=blue 35=magenta 36=cyan 37=white # Background color codes: # 40=black 41=red 42=green 43=yellow 44=blue 45=magenta 46=cyan 47=white So you see that 34;42 is blue text on green background and changed it to bold (01) yellow (33) text with no background. 3. This changes this at the system level, but it likely will not survice a reboot, so, I made a backup of this file in the config area. cp /etc/DIR_COLORS /boot/config/DIR_COLORS.sean I don't reboot my unraid server very often, but, when I do, then then login and copy my backup from config to the /etc/DIR_COLORS. Although I haven't done this yet, and it'll likely be months before I actually verify this part. So now ls still shows me that those files are world writeable, but it's easier to read (for me). Given that these folders are created by unRAID is there an option in unRAID to never create world writeable folders? (because that would solve the problem as well, since they'd just show the normal blue)