




kjarri
Members
-
Joined
-
Last visited
Everything posted by kjarri
-
That worked, I also switched the usb drives just to be safe. After booting with the bare minimum I tested the whole config folder and everything worked perfectly without issues. Not sure what was causing the issues to begin with. Thanks for the help.
-
the issue is still ongoing, restarts do not fix it. I've attached the syslog from when the incident started. syslog-20250730-224047.txt
-
Hey hey, I'm having an issue with my unraid server. I noticed it when docker containers where not reachable and I was unable to open up the GUI to figure out the issue. The console works on the server itself. Tried unplugging most of the hard drives since some older posts mentioned it happening after a hard drive failed but that does not seem to work for me. I've attached the diagnosis file that I have now, forgot to save it before rebooting. Any help is greatly appreciated. heimanas-diagnostics-20250730-2340.zip
-
Hey JorgeB, Yes, that seems to be because the Log partition is full. And it seems to be that the docker logs are filling up the partition: Any way I can find out why?
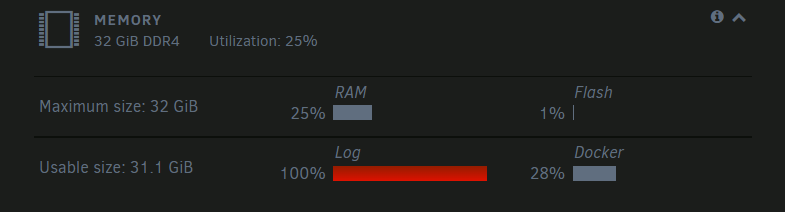
-
Hello, I seem to be having an issue with my system. I've been having some problems and weird behaviour with some of my docker container but now I need some help. It seems like at the moment the log is compleatly filled up, only a little after 24 hours after restarting the system. I don't want to restart the system right away because I want to find out what is causing the fill up, if I have some misconfigured container or something like that. Also, I have an error on my docker page: I tried looking for answers about this and one thread talked about ata errors causing the docker file to be corrupted. I had that issue two weeks ago so I was wondering if I had to rebuild my docker file or if the issue is related to the log issue. I have attached the diagnostic file here so hopefully that helps finding the issue. Here is the post with the ata errors and the diagnostic files Thanks. heimanas-diagnostics-20220812-1126.zip
-
After running two parity checks the second one came up with no errors. So the issue was likely some faulty connection with the cables and then just needing a parity check to fix the issues left. Here is the diagnostic report if you want to verify or if you find any other issue i'm missing. heimanas-diagnostics-20220803-1722.zip
-
Thanks, I'll do that. I'll make sure to not reboot the system and grab the diagnostics if I get some errors in the second check. It will take at least 24 hours to run each check so there will probably not be any news for a while.
-
Okay, I have run memtest for around 1 hour now and the first pass completed without any error. I'll keep on going maybe one more pass but is seems like the memory is not an issue at this point. If no errors are detected by memtest, should I try a correcting parity check and then another parity check to see if the errors are gone?
-
No, I have not run a memtest on this system at all. However the ATA error has not come up in the last 30 min so hopefully that issue is solved. Should I memtest right away or do some parity check first?
-
Ahh okay, I'll let the non correcting parity check run for a little bit to see if the ATA error comes up again. However, is it not concerning that the incorrect sectors now are not the same sectors that where faulting and corrected before the reboot? Or fx. sector 0 was incorrect before the reboot and after the reboot, even though that sector should have been corrected? Yes, I got that solution before knowing more of the downfalls of this approach. Am working on increasing the capacity of the system to decommission the drives and the USB enclosure completely.
-
Hey Jorge, Checked the cables and they all seemed secure. I tried switching the cables around in the system (power from one drive switched with the parity and the sata cable from another switched with the parity) just to test the cables. I seem to be still geting the same errors though. Here is the new diagnosing file: heimanas-diagnostics-20220801-1515.zip
-
Hello, I need some help with my server. I got some parity errors two weeks ago after an unclean shutdown. After reading many posts here I assumed everything should be fine and I just corrected the parity and did the parity check again and got no errors so I assumed everything was okay. Now during my monthly parity check I am getting more errors, I am up to 11.119 sync errors corrected so far. Now I am suspecting that something is wrong that needs investigating and was wondering if you could help me. What I suspect is that one of my 4 2TB drives in an external USB hard drive enclosure is failing. I am unable to run smart tests on them but I suspect they are failing since they are very old and I have used them for a long time. I have a hard drive ready to replace any of them if they are failing but for that I would need to know witch drive is the faulting one. However I have also found some errors in the logs that could be indicating the error but I can't understand what they are telling me: Aug 1 14:13:35 Heimanas kernel: ACPI BIOS Error (bug): Could not resolve symbol [\_SB.PCI0.SAT0.PRT0._GTF.DSSP], AE_NOT_FOUND (20200925/psargs-330) Aug 1 14:13:35 Heimanas kernel: ACPI Error: Aborting method \_SB.PCI0.SAT0.PRT0._GTF due to previous error (AE_NOT_FOUND) (20200925/psparse-529) Aug 1 14:13:35 Heimanas kernel: ACPI BIOS Error (bug): Could not resolve symbol [\_SB.PCI0.SAT0.PRT0._GTF.DSSP], AE_NOT_FOUND (20200925/psargs-330) Aug 1 14:13:35 Heimanas kernel: ACPI Error: Aborting method \_SB.PCI0.SAT0.PRT0._GTF due to previous error (AE_NOT_FOUND) (20200925/psparse-529) Aug 1 14:18:05 Heimanas kernel: ata1.00: limiting speed to UDMA/33:PIO4 Aug 1 14:18:05 Heimanas kernel: ata1.00: exception Emask 0x50 SAct 0x641000c2 SErr 0x4090800 action 0xe frozen Aug 1 14:18:05 Heimanas kernel: ata1.00: failed command: READ FPDMA QUEUED Aug 1 14:18:05 Heimanas kernel: ata1.00: failed command: READ FPDMA QUEUED Aug 1 14:18:05 Heimanas kernel: ata1.00: failed command: READ FPDMA QUEUED Aug 1 14:18:05 Heimanas kernel: ata1.00: failed command: READ FPDMA QUEUED Aug 1 14:18:05 Heimanas kernel: ata1.00: failed command: READ FPDMA QUEUED Aug 1 14:18:05 Heimanas kernel: ata1.00: failed command: WRITE FPDMA QUEUED Aug 1 14:18:05 Heimanas kernel: ata1.00: failed command: WRITE FPDMA QUEUED Aug 1 14:18:05 Heimanas kernel: ata1: hard resetting link Aug 1 14:18:15 Heimanas kernel: ata1: COMRESET failed (errno=-16) Aug 1 14:18:15 Heimanas kernel: ata1: hard resetting link I have attached the diagnosis file below, hopefully that helps finding out the issue. Thanks for the help in advance. heimanas-diagnostics-20220801-1418.zip
-
Hey, I'm wondering if anyone else is having an issue with requested movies and tv shows are not shown as available under the requested tab. I found many people having the same issue like this one: https://github.com/tidusjar/Ombi/issues/2626 In the end they all end up with updating the locale with this command sudo localectl set-locale LANG=en_US.UTF-8 exept my locale is already registered in the docker terminal: ~# locale LANG=en_US.UTF-8 LC_CTYPE="en_US.UTF-8" LC_NUMERIC="en_US.UTF-8" LC_TIME="en_US.UTF-8" LC_COLLATE=C LC_MONETARY="en_US.UTF-8" LC_MESSAGES="en_US.UTF-8" LC_PAPER="en_US.UTF-8" LC_NAME="en_US.UTF-8" LC_ADDRESS="en_US.UTF-8" LC_TELEPHONE="en_US.UTF-8" LC_MEASUREMENT="en_US.UTF-8" LC_IDENTIFICATION="en_US.UTF-8" LC_ALL= So I tried changing it to anything else with this command: LANG=en_IN.UTF-8 Then restarted the docker container. That did not work. So I tried updating the locale of my UnRAID mashine. That also did not work. So now I am at a loss because all articles and problems either lead to this fix. Has anyone experienced this or has an Idea about a fix? Running Unraid 6.7.1 and Ombi Latest

