

MisterWolfe
-
Posts
88 -
Joined
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by MisterWolfe
-
-
The operative word was 'had'. Yes. Using the OpenVPN client. Under controlled circumstances to test the client.
Why are you surprised that someone is testing it? I haven't seen other test results from using the openvpn client plugin. I'm curious what others are seeing when they use it. If it's an insecure plugin, perhaps it should be noted somewhere.
-
I have a concern about the openvpn client on unraid.
Several times now I've noticed login attempts to my unraid server while connected to my VPN. My VPN blocks all port forwarding, so I'm not sure how they are connecting to me.
You can see a snippet below of the log file.
Mar 21 19:09:35 Tower in.telnetd[5987]: connect from 187.22.157.164 (187.22.157.164) Mar 21 19:09:35 Tower telnetd[5987]: ttloop: peer died: EOF Mar 21 19:11:55 Tower in.telnetd[7255]: connect from 221.138.84.57 (221.138.84.57) Mar 21 19:11:55 Tower emhttp: cmd: /usr/local/emhttp/plugins/dynamix/scripts/tail_log syslog Mar 21 19:12:01 Tower telnetd[7255]: ttloop: peer died: EOF Mar 21 19:13:49 Tower emhttp: cmd: /usr/local/emhttp/plugins/dynamix/scripts/tail_log syslog Mar 21 19:15:35 Tower in.telnetd[8908]: connect from 187.160.124.138 (187.160.124.138) Mar 21 19:15:38 Tower emhttp: cmd: /usr/local/emhttp/plugins/dynamix/scripts/tail_log syslog Mar 21 19:15:45 Tower login[8917]: invalid password for 'UNKNOWN' on '/dev/pts/2' from 'CableLink-187-160-124-138.PCs.InterCable.net' Mar 21 19:15:51 Tower login[8917]: invalid password for 'UNKNOWN' on '/dev/pts/2' from 'CableLink-187-160-124-138.PCs.InterCable.net' Mar 21 19:16:10 Tower php: /usr/local/emhttp/plugins/openvpnclient/scripts/rc.openvpnclient 'stop' Mar 21 19:16:12 Tower ntpd[1476]: Deleting interface #8 tun5, 10.8.0.113#123, interface stats: received=0, sent=0, dropped=0, active_time=866 secs
As soon as I disconnect from the VPN, the login attempts stop.
I've got a query in to my VPN provider asking about the attack surface presented when using their service.
I'm beefing up iptables, but my understanding is that while using a VPN with no port forwarding, there shouldn't be a way to route back to my server. This means that either the openvpn client or my VPN is exposing the unraid server to the world.
Has anyone else experienced this while connected to a VPN?
Thanks,
-
It was a reply to me. I discovered my error and deleted my post and he must have seen it before I removed it.
Excellent script. Works as expected when I try to run it from the proper spot.

That's expected, since the beta plugin is not compatible with Unassigned Devices. Please go to Settings>Preclear Disk Beta
gfjardim ... was that reply for me?
If so i do not understand what you are trying to tell me. I do not have a preclear disk beta tab within settings. FYI i downloaded the 'amended' version by 'search'ing for 'preclear' on the CA apps tab. It downloaded the new version (dated today) and the install script confirmed this but the plugin it installed still shows old timestamps and version number against it and hasn't got 'beta' anywhere to be seen. You know much better than me how these things work. I'm just happy to confirm that it does!!
-
Thanks. I just browsed the man page for sfdisk. -R has been depracated in 2.26/
"Since version 2.26 sfdisk no longer provides the -R or --re-read option to force the kernel to reread the partition table. Use blockdev --rereadpt instead"
edit: I modified the two instances of sfdisk -R in the preclear script with blockdev --rereadpt and the preclear is now running. I'll update as to the status when done in case there are any gotchas.
edit 2: I knew it wouldn't be that easy! It starts scanning and throws an error. I'll wait for a script update. I don't have spare hardware to run preclear on.
-
Good evening,
I'm having an issue running preclear on 2 new 4TB Seagate NAS drives.
The drives show when I do a preclear_disk.sh -l. When I run preclear_disk.sh /dev/sdx (x=drive slot) I get a message that the drive is busy.
I thought it might be a power issue so I moved the connectors to different power cables. It's a 750W supply, which should be good for the 10-11 or so drives I
have. No effect.
Using 6.2 beta 18.
I've included the output of the preclear below. Syslog attached.
Thanks!
root@Tower:/boot# preclear_disk.sh -l ====================================1.15 Disks not assigned to the unRAID array (potential candidates for clearing) ======================================== /dev/sdg = ata-ST4000VN000-1H4168_Z305RYB1 /dev/sdf = ata-ST4000VN000-1H4168_Z305RYKG root@Tower:/boot# preclear_disk.sh /dev/sdf sfdisk: invalid option -- 'R' Usage: sfdisk [options] <dev> [[-N] <part>] sfdisk [options] <command> Display or manipulate a disk partition table. Commands: -A, --activate <dev> [<part> ...] list or set bootable MBR partitions -d, --dump <dev> dump partition table (usable for later input) -J, --json <dev> dump partition table in JSON format -g, --show-geometry [<dev> ...] list geometry of all or specified devices -l, --list [<dev> ...] list partitions of each device -F, --list-free [<dev> ...] list unpartitions free areas of each device -s, --show-size [<dev> ...] list sizes of all or specified devices -T, --list-types print the recognized types (see -X) -V, --verify [<dev> ...] test whether partitions seem correct --part-label <dev> <part> [<str>] print or change partition label --part-type <dev> <part> [<type>] print or change partition type --part-uuid <dev> <part> [<uuid>] print or change partition uuid --part-attrs <dev> <part> [<str>] print or change partition attributes <dev> device (usually disk) path <part> partition number <type> partition type, GUID for GPT, hex for MBR Options: -a, --append append partitions to existing partition table -b, --backup backup partition table sectors (see -O) --bytes print SIZE in bytes rather than in human readable for mat -f, --force disable all consistency checking --color[=<when>] colorize output (auto, always or never) colors are enabled by default -N, --partno <num> specify partition number -n, --no-act do everything except write to device --no-reread do not check whether the device is in use -O, --backup-file <path> override default backup file name -o, --output <list> output columns -q, --quiet suppress extra info messages -X, --label <name> specify label type (dos, gpt, ...) -Y, --label-nested <name> specify nested label type (dos, bsd) -L, --Linux deprecated, only for backward compatibility -u, --unit S deprecated, only sector unit is supported -h, --help display this help and exit -v, --version output version information and exit Available columns (for -o): gpt: Device Start End Sectors Size Type Type-UUID Attrs Name UUID dos: Device Start End Sectors Cylinders Size Type Id Attrs Boot End-C/H/S Start-C/H/S bsd: Slice Start End Sectors Cylinders Size Type Bsize Cpg Fsize sgi: Device Start End Sectors Cylinders Size Type Id Attrs sun: Device Start End Sectors Cylinders Size Type Id Flags For more details see sfdisk(. Sorry: Device /dev/sdf is busy.: 1
-
Inside SQL, try changing the owncloud user from owncloud@localhost to owncloud@%
I was getting the same type of error you are, and this solved my issue. Using % allows connections from any host.
It's no good setting privileges on localhost as to all intents and purposes it's not running on localhost as it's in a separate docker container. localhost would be suitable if they were both running in the same container.
I change from localhost to IP. I see the newly granted permissions. Still no luck.
I can safely connect to the database using "mysql -u owncloud -p -t owncloud". It prompts for password and I can log in without any issues.
I've to admit though, that once (only once) I got past this stage and got to the 'binlog' issue. I fixed 'my.conf' and got back to redo the step and never got beyond the original issue of database connection. I restarted both DB and OC few times though.
-
Thanks, your reply was helpful.
I had to set the user given access to the owncloud database owncloud@% instead of owncloud@localhost or owncloud@IPADDRESS
2 things possibly..
Try the IP address instead of localhost in the owncloud login.
And depending on the error after that, you could replace 'localhost' during the DB/user creation process with '%' instead.
- NinthWalker
-
Using delugeVPN docker
1)Unraid 6.1.8
2) Intel q9550 processor
3) no
4)
Module Size Used by
xt_nat 1665 10
veth 4401 0
ipt_MASQUERADE 981 11
nf_nat_masquerade_ipv4 1649 1 ipt_MASQUERADE
iptable_nat 1615 1
nf_conntrack_ipv4 5626 2
nf_nat_ipv4 4111 1 iptable_nat
iptable_filter 1280 1
ip_tables 9310 2 iptable_filter,iptable_nat
nf_nat 9789 3 nf_nat_ipv4,xt_nat,nf_nat_masquerade_ipv4
md_mod 30680 6
tun 16465 0
hwmon_vid 2028 0
coretemp 5044 0
r8169 57464 0
mii 3339 1 r8169
ata_piix 24047 6
i2c_i801 8917 0
skge 27834 0
pata_marvell 2843 0
ahci 24107 0
sata_sil 7159 2
libahci 18687 1 ahci
asus_atk0110 6874 0
acpi_cpufreq 6074 0
5) - attached supervisord.log and supervisord.log.1
6) I used deluge under 6.1.7 and it worked.
After looking at supervisord.1.log, which was generated when I installed delugevpn, I saw that the openvpn folder couldn't be accessed. I changed the owner to nobody.users (from root.root) and restarted. supervisord.log is the file generated after restarting.
Edit: Still no webUI access on the LAN
-
Long story short, I had an existing owncloud docker installed and working for the last year or so. Today, I decided to wipe my docker.img file and start fresh.
Using mariadb as a backend.
I created the user and db in mariadb with mysql workbench as follows
CREATE USER 'owncloud'@'localhost' IDENTIFIED BY 'ThePasswordYouWant';
CREATE DATABASE IF NOT EXISTS owncloud;
GRANT ALL PRIVILEGES ON owncloud.* TO 'owncloud'@'localhost' IDENTIFIED BY 'ThePasswordYouWant';
It returns successful and I can see the db and user.
Then I installed owncloud. Owncloud installed fine and I can get to the web page at https://localhost:8000
data folder mapped from /var/www/owncloud/data/ in the container to /mnt/user/OWNCLOUD/data on the array
I select storage and database and select the mysql/mariadb option and enter the database id and credentials I used when setting it up. I enter the admin account info that I want
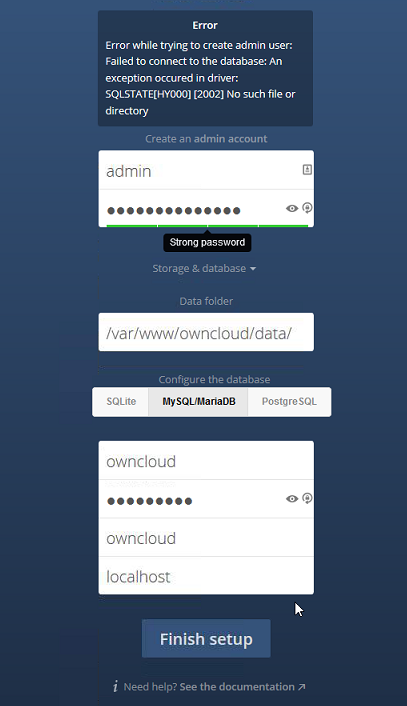
I get this error:
Failed to Connect to the database... SQLSTATE[HY000] [2002] No such file or directory
I read on the owncloud site that this is could be a problem with permissions on the owncloud.db file in the data directory ( /var/www/owncloud/data/), so I chmod'ed it to 777 and then 755.
Same error.
I've tried creating and using different databases and users with the same result.
The owncloud.log file in the data directory is empty. I attached an image of the web page after the connection fails.
Does anyone have any suggestions?
Thank you!
-
It's an ASUS RT-AC68U with asuswrt-merlin firmware. There aren't any issues with my windows clients getting their reservation when they reboot, but it could be something specific to linux based operating systems. Removing the reservation from the router is a good idea. I'll give it a shot when I get home tonight.
-
When I had that particular problem I had another machine with the same ip as well I had another instance like that when I had two unRAID servers that some how had tower as their names too. lol
It's a static IP. The IP is reserved in DCHP, so there aren't any conflicts there. There are no other computers on the LAN with the same IP or name, either. The server always gets the same IP.
edit: to clarify
LAN is 192.168.xx. /24 & the Dynamic IP range between 10 and 40 and the static IPs are outside that range.
-
I just replaced the existing cable with a brand new cat6 cable for a 2nd time and connected to a different port on my router. Still the same issue.
I'm fairly certain it's not related to the router, cable, or NIC card. I get the same behavior with the on board and the PCI NIC.
Oddly enough, I seem to get an IP on the 7th reboot fairly consistently. Once it has an IP, it hangs on to it and operates normally.
The only common denominator that connects with the PCI and onboard NIC is the motherboard. I have another motherboard of the same type. I may have to swap it to eliminate that possibility.
-
Yes, my router is a few months old, and I put a new cat5e cable from the unraid box to the router within the last month. I still get the same error with a new router and cable. It wouldn't hurt to try a third cable, though.
-
Short history - Up until 6 months ago I used the onboard NIC on my motherboard and started getting issues with the network interface not acquiring an IP address. It would take multiple reboots for the interface to finally get an IP. Thinking that it might be an issue with the onboard NIC, I purchased a DLINK PCI NIC and put it in the server. I disabled the onboard nic in the BIOS, of course.
The new NIC didn't solve the issue. I still have issues with the interface acquiring an IP address whenever I reboot. Once an IP address is finally acquired, the server runs fine and there are no drops or network issues. I only have an issue on reboot.
I've grabbed the section of the system log that relates to this and included it below.
Signs are pointing to either a motherboard issue or an issue with how unraid is querying the interface. I'm leaning towards the former.
Has anyone else experienced something similar?
Feb 9 16:29:38 Tower dhcpcd[1270]: dhcpcd-6.8.1 starting
Feb 9 16:29:38 Tower dhcpcd[1270]: eth0: executing `/lib/dhcpcd/dhcpcd-run-hooks' PREINIT
Feb 9 16:29:38 Tower dhcpcd[1270]: eth0: executing `/lib/dhcpcd/dhcpcd-run-hooks' NOCARRIER
Feb 9 16:29:38 Tower dhcpcd[1270]: eth0: waiting for carrier
Feb 9 16:29:38 Tower kernel: r8169 0000:04:01.0 eth0: link down
Feb 9 16:29:38 Tower kernel: r8169 0000:04:01.0 eth0: link down
Feb 9 16:29:41 Tower dhcpcd[1270]: eth0: carrier acquired
Feb 9 16:29:41 Tower kernel: r8169 0000:04:01.0 eth0: link up
Feb 9 16:29:41 Tower dhcpcd[1270]: eth0: executing `/lib/dhcpcd/dhcpcd-run-hooks' CARRIER
Feb 9 16:29:41 Tower dhcpcd[1270]: eth0: delaying IPv4 for 0.1 seconds
Feb 9 16:29:41 Tower dhcpcd[1270]: eth0: using ClientID 01:c4:a8:1d:f8:fc:69
Feb 9 16:29:41 Tower dhcpcd[1270]: eth0: soliciting a DHCP lease
Feb 9 16:29:41 Tower dhcpcd[1270]: eth0: sending DISCOVER (xid 0xa41e6cf), next in 4.7 seconds
Feb 9 16:29:46 Tower dhcpcd[1270]: eth0: sending DISCOVER (xid 0xa41e6cf), next in 8.2 seconds
Feb 9 16:29:54 Tower dhcpcd[1270]: eth0: sending DISCOVER (xid 0xa41e6cf), next in 16.5 seconds
Feb 9 16:30:10 Tower dhcpcd[1270]: eth0: sending DISCOVER (xid 0xa41e6cf), next in 32.3 seconds
Feb 9 16:30:38 Tower dhcpcd[1270]: received SIGTERM, stopping
Feb 9 16:30:38 Tower dhcpcd[1270]: eth0: removing interface
Feb 9 16:30:38 Tower dhcpcd[1270]: eth0: executing `/lib/dhcpcd/dhcpcd-run-hooks' STOP
Feb 9 16:30:38 Tower dhcpcd[1270]: eth0: executing `/lib/dhcpcd/dhcpcd-run-hooks' STOPPED
Feb 9 16:30:38 Tower dhcpcd[1270]: dhcpcd exited
Feb 9 16:30:38 Tower logger: /etc/rc.d/rc.inet1: /sbin/dhcpcd -b -t 10 -h Tower -d -L eth0
Feb 9 16:30:38 Tower dhcpcd[1300]: dhcpcd-6.8.1 starting
Feb 9 16:30:38 Tower dhcpcd[1300]: forking to background
Feb 9 16:30:38 Tower dhcpcd[1303]: eth0: executing `/lib/dhcpcd/dhcpcd-run-hooks' PREINIT
Feb 9 16:30:38 Tower dhcpcd[1300]: forked to background, child pid 1303
Feb 9 16:30:38 Tower dhcpcd[1303]: eth0: executing `/lib/dhcpcd/dhcpcd-run-hooks' CARRIER
Feb 9 16:30:38 Tower dhcpcd[1303]: eth0: delaying IPv4 for 0.3 seconds
-
Weird update experience for me, but all sorted now. Might try to replicate on my lab server out of curiosity. Or possibly actually search the forum...

Step-by-step recap in case anyone is curious or easily amused:
[*]Upgraded to 6.1.2 from 6.0 via the plugin, rebooted as usual, and ... nothing! Trusty old server.local wouldn't respond! No web interface! No ping! Gaah!
[*]Plugged in display, greeted by normal Linux console prompt and correct version of unRAID. So far so good. But why can't I reach it over the network?
[*]Logged in as root locally. No password required. Unexpected. Got a bad feeling about this...
.....
- Server boots just fine.
Honestly, I've seen MANY reports similar to this and it's why I've stuck with 6.0.1 for the time being...
@Limetech, have you guys looked into reports such as this?
I had the same issue. In my case, I was unable to boot from the usb key after the upgrade to 6.1.2. Inspection of the usb key on a different computer showed all the config was wiped out, along with all plugins. I ended up starting fresh on a new usb key just in case if was a corruption issue on the drive itself.
I will be much more careful with upgrades moving forward, particularly after reading other reports of this happening to other people.
- Server boots just fine.
-
So I've run into an issue with this upgrade. All of my settings seem to have disappeared. All my drives are blank in the web gui, and no config backup. I'd rebooted multiple times trying to get an IP, so no helpful syslog.
Best way to restore?
edit: also looks like the whole usb key was wiped.
edit: created new usb key. found older screenshot of disk config. disk shares created automatically. will check to make sure they're set properly. was able to mount docker.img and have my dockers start with no issues. relatively painless.
-
Since upgrading to RC2, I can't access my cache drive directly via file explorer. ie) \\tower\cache
My docker applications work, so the OS is able to access it without an issue. I'm also able to copy to user shares that specify cache disk only.
IS this expected behavior with the new release?
-
Thanks for the info. The ds380 case looks ideal. I will also chexk the forums for the cooling issues before taking the plunge.
-
I'll be re-using the drives from the old array, but that's it. I'll want to go new on everything else.
Hot swappable/tool less would be nice, but it's not a big deal if it's not.
-
I've moved and my two lovely HAF X cases are now too big for the space I'm in. That and the HAF X are overkill for my 8 drive system.
I'm hoping for some assistance finding a small form factor case that will support 8 drives. I'd like to go haswell, either xeon or i5, for the power savings as well. I primarily use my system for running a handful of dockers, including plex, and some fiddling about with virtualization so the case would need to have the space for that as well.
Thanks!
-
Having a hot spare that automatically replaces a drive when it fails would be as/slightly more appealing to me than immediately implementing Raid 6. Of course, both would be even better.
In the event of a drive failure it all boils down to time. The sooner you get a replacement disk in place the better off you are. If you're off site, that extra hour of travel could be responsible for data loss.
-
I've lost my disk configuration after upgrading to the RC1 and the disk slots are all showing up as unassigned.
Of course I didn't make a backup or screenshot my disk config before doing the upgrade. Bad me.
I've checked the backup folders for beta15 and the config files aren't there.
How can I get my disk config back properly?
EDIT: I changed the number of disk slots to 7 and the disks are now showing up. Configuration is showing as valid now as well. Going to start the array and see how it goes.
-
I just tried updating via the plugin update system. It's been about 20 mins since I rebooted and the unraid server still hasn't come online.
Looks like I have some work to do when I get home.
-
I had a similar issue. I ended up replacing the NIC on the server and my speeds were back up to normal. Might be some thing to investigate if trying new network cables isn't having a positive effect.


OpenVPN Client:32 and 64-bit: Your Private and Secure Path to the Internet
in 6.0 (Unverified)
Posted
Typically I connect to my vpn through my router. This can complicate certain things for members of my household when on steam. This is why I was testing the client and why I monitored it while it was active to see what kind of footprint was being exposed. Quite large, obviously.
I'll check out bixhex's offerings to see if they'll work for me. If not, I'll put a second router on my network for unraid to use for VPN.