

Squazz
-
Posts
137 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by Squazz
-
-
4 hours ago, JorgeB said:
Make sure this has been taken care of:
https://forums.unraid.net/topic/46802-faq-for-unraid-v6/?do=findComment&comment=819173
With these changes, won't my Ryzen CPU then always be at a fixed clock, and consume a lot of electricity under idle?
-
1 hour ago, JorgeB said:
Make sure this has been taken care of:
https://forums.unraid.net/topic/46802-faq-for-unraid-v6/?do=findComment&comment=819173
I found "Power Supply Idle Control" and set it to "typical current idle"
I also disabled "Global C-States" and "AMD Cool N Quiet"
I also changed "Load-Line Calibration (LLC)" from auto to 4 (based on recommendation here: (https://www.reddit.com/r/AMDHelp/comments/pcp4fs/comment/hakelm3/?utm_source=share&utm_medium=web2x&context=3)I know I changed many things at once. But all changes should make the system more stable
-
I've had this problem with several versions unraid, but it's also present here in 6.12.6
Suddenly UnRaid just stops responding.
- Shares are unavailable
- display output is no more
- I lose access to my running containers / they stop responding
Hardware:
MSI X370 SLI PLUS (MS-7A33) , Version 2.0
American Megatrends Inc., Version 3.JR
BIOS dated: Friday, 29-11-2019AMD Ryzen 7 1700 Eight-Core
16 GiB DDR4
I've attached the logs I could find from just after the first boot after the last time it happened.
Every time it happens I run a full parity, finding 0 errors each time
nas-syslog-20231230-1833.zip nas-syslog-20231230-1036.zip nas-diagnostics-20231230-1932.zip
-
On 3/27/2023 at 12:25 PM, binhex said:
running CA backup by any chance?, if so that will terminate running containers.
That could very much be it, thanks! So long since I've set up my unRaid box, totally forgot that CA Backup was a thing
")
-
On 9/28/2022 at 12:19 PM, binhex said:
this indicates something requested that the process exits, probably due to you shutting down the container, if so there is nothing to worry about.
I have this same problem, where the binhex-plexpass container stops with "WARN received SIGTERM indicating exit request" as the message in the log.
But, I haven't asked it to shut down, for some reason it just does that by itself. -
34 minutes ago, JorgeB said:
That is a 1st gen Seagate SMR drive, never had one but remember reading write performance isn't great, 2nd gen Seagate drives like the ST8000AS0002 usually perform well enough with Unraid, the ones I have are about as fast as normal CMR drives for most cases, Toshiba and WD SMR drives (and possibly other Seagate models) don't perform as well, I have an array with Toshiba drives that frequently slows down to 5MB/s for writes.
I was thinking the same thing. But, when looking up excactly that series, I found this reddit post: https://www.reddit.com/r/DataHoarder/comments/2vxboz/comment/cp6umlc/?utm_source=share&utm_medium=web2x&context=3
As soon as sustained writes gets past 30GBs the write speed tanks (people say it flattens out at 27MB/s. Which it always will when it is introduced to Unraid.
So, I am still curious what the actual experience is by the people who are using these Archive drives. And, wonder if anyone has ever replaced an existing drive with a archive drive?
-
So, I've seen that quite a few people are running Seagate Archive drives, and seem to be happy with the drives.
But, that is confusing me. Won't the fact that they are SMR drives be quite a problem when replacing a dead drive, or just introducing them to the array?
Right now I have 40Tb (8x5TB ST5000AS0001) worth of drives sitting on a shelf, as I don't want to introduce them to my UnRaid array if they turn out to be quite a hassle to work with.
I tried to replace a 3Tb WD RED (WD30EFRX) with one of my Archive drives, and it quickly went from acceptable to 10MB/s. For a 5TB drive, 10MB/s is never gonna cut it. At that speed, they are probably never gonna get introduced to the array before another drive dies.
So, in the end my question might be. What am I doing wrong?
If people are happy with their 8Tb Seagate Archive drives, then why does it seem that I am getting speeds as 10MB/s? -
On 5/26/2022 at 3:05 AM, ConnerVT said:
Just read through your build thread. I touched on it in an earlier post, but you'll appreciate the reduction in power.
Buying new harddrives just for the reduction in power, seems to not really be worth it. At least here in Denmark
We are talking a payback time of at least a decade, when looking at powerdraw exclusively
It's a nice bonus. But not something I'd buy new drive for
-
23 minutes ago, Frank1940 said:
I am going to be a bit of a contrarian here. It appears that you have 18TB of storage space on your current server. How long did it take you to fill it?
... Do some analysis of so that by the time you get to the point with your current up-sized drives are starting to fail, they aren't half empty.
It might make sense to go with 16TB or it might make sense to with 8 or 10 TB drives.
That's a fair point! Which is also what is making me consider if I should just go with 8Tb 7E8 drives instead.
15 minutes ago, ConnerVT said:The time to run the parity check scales pretty linearly with the size of the parity drive (as it is the largest). My system is similar in processing power to yours (if your siggy is correct)
...
Even if it takes 12 days @ 2 hr/day really doesn't matter, as long as the maintenance task is done.
My signature is updated now
")
Good to hear about your experience, and a fair point about the 2hr/day is also viable, as long as it is done.
-
2 hours ago, ConnerVT said:
No one ever came home after buying a new television and has said "I should have bought the smaller one." 😄
Buy as much storage as you anticipate you will use now, and in the future. Replacing all of those small drives with a few large ones will reduce your power consumption (and noise, and heat...) as well as reduce the number of points of failure.
2 hours ago, Hoopster said:I am a firm believer that fewer larger drives is better than many smaller drives. I have consolidated twice. First it was 3TB to 8TB drives and now I am starting to move from 8TB to 14TB and 16TB drives.
I feel there's beginning to be a consensus.
I'm propably gonna end up with buying 2x Seagate Exos X16 ST16000NM001G 16TB drives, that's where I get most space for the money.
And it also seems that parity checks is not that big of a problem with drives in the sizes of above 10Tb
-
15 minutes ago, itimpi said:
The normal recommendation is to go for as big a drive as you can afford. Large drives tend to perform better, consume less power and be less points of potential failure.
I guess I'll go with the 16Tb drives then
15 minutes ago, itimpi said:Bear in mind, though, that you have to upgrade the parity drive(s) first before you can have large data drives.
I'm considering removing one of my two parity drives, and then just go with a single 16Tb parity drive
17 minutes ago, itimpi said:You can use the Parity Check Tuning plugin to minimise the effect on daily use of parity checks if you have large drives.
Sounds interresting, I'll give it a look
12 minutes ago, DMills said:For me, it kind of depends on the system the drives are on. I know on my previous unRAID "server", I had a number of 8TB drives and it took upwards of 24 hours to finish the monthly parity check, mainly due to the machine being overtaxed by me with lots of containers running, and using the machine during that time. Now on my new server with 16TB drives, and lots more horsepower, I don't even notice the check is running until I go onto the server and see it's either running or finished. The parity check now takes around 26 hours or so, so there is no direct correlation from one size to the next, there are lots of other factors. I checked the prices and found the 16TB drives to be the best $/TB so went with them, parity check times be damned!
Interresting that you only see 26 hours for a parity check on the 16Tb drives.
If one doesn't feel the impact of the parity check, a monthly check might be OK.
@DMills could the reason you don't see an impact be that you have a big cache? Personally I don't have that big a cache as I'm only running SSDs as my cache
-
Hi
I have a bunch of WD Green 3Tb drives. And I'm beginning to run out of space (both physical in the computer case, and on the shares)I'm considering buying new Seagate Exos X16 16 or 14 Tb drives. But, are they gonna be too big?
I'm considering the parity checks. Right now it takes me about 8 hours for my 3Tb drives. If it's gonna tke me 5,5 times as much time with 16Tb drives, we are talking 40+ hours of parity checking. That's almost two days where I will see degraded performance on my shares.
Right now I do parity checks every month. That doesn't seam feasable with a 2 days parity check.What is the experience from other people?
Are 16Tb drives too big?
How often do you do parity checks with so large drives?
How long does it take to take to do parity checks of drives of this size?
My main fear is data degradation through bitrot or the like.-
 1
1
-
-
2 minutes ago, ChatNoir said:
You'll probably have a better chance to know what happened if you provide your diagnostics.
Noted, hereby uploaded
-
I have 2 5Tb disks as parity, and duing a parity-sync they both ended in an error-state.
I've attached SMART reports for both.
On of the drives I understand if is dying/dead. It seems it has some errors, and they are probably worsening.
The other drive on the other hand, I don't understand why ended in an error-state.I'm hoping someone can help me figure out why my drives ended in an error state. Crossing fingers that I'll be better to read the reports after I've gotten some help on this event.
-
19 minutes ago, craigjl77 said:
I run my Windows10 VM's this way, on my 1050Ti, and it works flawlessly; up to you whether you wish to try it
")
Oh, I'm gonna try it out

I was just wondering why the official recommendations said not to use that setup, if that is the most stable setup
-
24 minutes ago, Turnspit said:
As a first step of troubleshooting without having seen any details:
Have you tried removing all passed-through devices from the VM and tested if it starts up correctly?
Yup, tried that. When first the VM gets in the "wont boot" state, nothing can save it.
-
1 hour ago, craigjl77 said:
For GPU pass thru on Windoze I use Q35-5.1 as Machine Type and a BIOS set to SeaBios. Know this to be a recommendation of SpaceInvader1 and it works well for my VM's. Suggest that you give it a try 🙂
Interresting, can you find a concrete place where this is recommended?
As far as I know it's only recommended for Linux & MacOS? -
For the past 3 years, I've been daily driving a Windows VM (see link for topic around my setup)
I've had some problems here and there, but this week everything just went heywire.
I've started to get currupted boots, every, single, time.
After tinkering with it for the past week, i've tried setting up a bunch of new VMs today. Fethcing the latest ISO for Windows, and basing my VMs on that.After install all of the updates, and rebooting, the problems starts. Sometimes the system just halst after trying to start up windows for half and hour. Other times it goes strait to the blue screen, telling me that bootup is corrupted, and needs to be repaired (which I'm never able to do).
I'm trying to set up the machine with
CPU Mode: Host passthrough
10 logical CPUs pinned (and isolated)
Initial Memory: 30720
Max Memory: 30720
i440fx-5.1
OVMF
USB 2.0
Primary vDisk Location: auto: /mnt/user/domains/Windows 10/vdisk1.img
Primary vDisk Size: 110Gb
Primary vDisk Type: Raw
Primary vDisk Bus: VirtIO
Passing through:
- 1070ti
- 1070it soundcard
- onboard soundcard
- Stubbed USB 3.0 controller: AMD Family 17h (Models 00h-0fh) USB 3.0 Host Controller | USB controller (30:00.3)
The share "Domains" is set to "Prefer : Cache"
My Cache pool is a single 500Gb Sata SSD: Samsung_SSD_860_EVO_500GB_S4XBNF1MA02769A - 500 GB (sdb)
unRaid version: 6.9.2
I'm running the latest BIOS version for my motherboard
My Hardware
CPU: Ryzen 7 1700 (65W)
Motherboard: MSI MS-7A33 motherboard
Ram: 16GB (2x 8GB 2400Mhz) + 32Gb (2x 16GB 2400Mhz)Raid drive: LSI 9201-8i
GPU: 1070ti
What can I provide of information to help you help me? I'm kinda stuck, I don't know what to do from here.
Right now, I'm unable to use unRaid to host Windows VMs
-
Can it be true that I cannot create read-only users?
I created users in unRaid and set the description as needed. But even though they are set as only having read-access to a given share, they still have write access?
-
@Josh.5 unfortunately I don't really play games anymore. It's primarily work and video-consumption that's done on my computer.
I've been trying to play some CS:GO, but it seems that FPS caps at 100FPS, and I too have experienced micro-sutters from time to time. In the end CS:GO competitive was a no-go though a VM for me. So I have a bare-metal machine for that.
Passing though the entire SSD, and the entire USB controller seems to give the best results too.
Regarding my XML, I see no harm in you getting my XML :)
<?xml version='1.0' encoding='UTF-8'?> <domain type='kvm' id='3'> <name>Windows 10</name> <uuid>d0e0e6a6-d9cc-b96a-68d7-ff7c5952ade1</uuid> <metadata> <vmtemplate xmlns="unraid" name="Windows 10" icon="windows.png" os="windows10"/> </metadata> <memory unit='KiB'>12582912</memory> <currentMemory unit='KiB'>12582912</currentMemory> <memoryBacking> <nosharepages/> </memoryBacking> <vcpu placement='static'>10</vcpu> <cputune> <vcpupin vcpu='0' cpuset='3'/> <vcpupin vcpu='1' cpuset='11'/> <vcpupin vcpu='2' cpuset='4'/> <vcpupin vcpu='3' cpuset='12'/> <vcpupin vcpu='4' cpuset='5'/> <vcpupin vcpu='5' cpuset='13'/> <vcpupin vcpu='6' cpuset='6'/> <vcpupin vcpu='7' cpuset='14'/> <vcpupin vcpu='8' cpuset='7'/> <vcpupin vcpu='9' cpuset='15'/> </cputune> <resource> <partition>/machine</partition> </resource> <os> <type arch='x86_64' machine='pc-q35-4.2'>hvm</type> <loader readonly='yes' type='pflash'>/usr/share/qemu/ovmf-x64/OVMF_CODE-pure-efi.fd</loader> <nvram>/etc/libvirt/qemu/nvram/d0e0e6a6-d9cc-b96a-68d7-ff7c5952ade1_VARS-pure-efi.fd</nvram> </os> <features> <acpi/> <apic/> <hyperv> <relaxed state='on'/> <vapic state='on'/> <spinlocks state='on' retries='8191'/> <vendor_id state='on' value='none'/> </hyperv> </features> <cpu mode='host-passthrough' check='none'> <topology sockets='1' cores='10' threads='1'/> </cpu> <clock offset='localtime'> <timer name='hypervclock' present='yes'/> <timer name='hpet' present='no'/> </clock> <on_poweroff>destroy</on_poweroff> <on_reboot>restart</on_reboot> <on_crash>restart</on_crash> <devices> <emulator>/usr/local/sbin/qemu</emulator> <disk type='block' device='disk'> <driver name='qemu' type='raw' cache='writeback'/> <source dev='/dev/disk/by-id/ata-Samsung_SSD_840_EVO_120GB_S1D5NSBF425061E' index='2'/> <backingStore/> <target dev='hdc' bus='sata'/> <boot order='1'/> <alias name='sata0-0-2'/> <address type='drive' controller='0' bus='0' target='0' unit='2'/> </disk> <disk type='file' device='disk'> <driver name='qemu' type='raw' cache='writeback'/> <source file='/mnt/user/Kasper/vdisk1.img' index='1'/> <backingStore/> <target dev='hdd' bus='virtio'/> <alias name='virtio-disk3'/> <address type='pci' domain='0x0000' bus='0x03' slot='0x00' function='0x0'/> </disk> <controller type='pci' index='0' model='pcie-root'> <alias name='pcie.0'/> </controller> <controller type='pci' index='1' model='pcie-root-port'> <model name='pcie-root-port'/> <target chassis='1' port='0x8'/> <alias name='pci.1'/> <address type='pci' domain='0x0000' bus='0x00' slot='0x01' function='0x0' multifunction='on'/> </controller> <controller type='pci' index='2' model='pcie-root-port'> <model name='pcie-root-port'/> <target chassis='2' port='0x9'/> <alias name='pci.2'/> <address type='pci' domain='0x0000' bus='0x00' slot='0x01' function='0x1'/> </controller> <controller type='pci' index='3' model='pcie-root-port'> <model name='pcie-root-port'/> <target chassis='3' port='0xa'/> <alias name='pci.3'/> <address type='pci' domain='0x0000' bus='0x00' slot='0x01' function='0x2'/> </controller> <controller type='pci' index='4' model='pcie-root-port'> <model name='pcie-root-port'/> <target chassis='4' port='0xb'/> <alias name='pci.4'/> <address type='pci' domain='0x0000' bus='0x00' slot='0x01' function='0x3'/> </controller> <controller type='pci' index='5' model='pcie-root-port'> <model name='pcie-root-port'/> <target chassis='5' port='0xc'/> <alias name='pci.5'/> <address type='pci' domain='0x0000' bus='0x00' slot='0x01' function='0x4'/> </controller> <controller type='pci' index='6' model='pcie-root-port'> <model name='pcie-root-port'/> <target chassis='6' port='0xd'/> <alias name='pci.6'/> <address type='pci' domain='0x0000' bus='0x00' slot='0x01' function='0x5'/> </controller> <controller type='pci' index='7' model='pcie-root-port'> <model name='pcie-root-port'/> <target chassis='7' port='0xe'/> <alias name='pci.7'/> <address type='pci' domain='0x0000' bus='0x00' slot='0x01' function='0x6'/> </controller> <controller type='virtio-serial' index='0'> <alias name='virtio-serial0'/> <address type='pci' domain='0x0000' bus='0x02' slot='0x00' function='0x0'/> </controller> <controller type='sata' index='0'> <alias name='ide'/> <address type='pci' domain='0x0000' bus='0x00' slot='0x1f' function='0x2'/> </controller> <controller type='usb' index='0' model='qemu-xhci' ports='15'> <alias name='usb'/> <address type='pci' domain='0x0000' bus='0x00' slot='0x07' function='0x0'/> </controller> <interface type='bridge'> <mac address='52:54:00:d3:d6:26'/> <source bridge='br0'/> <target dev='vnet0'/> <model type='virtio'/> <alias name='net0'/> <address type='pci' domain='0x0000' bus='0x01' slot='0x00' function='0x0'/> </interface> <serial type='pty'> <source path='/dev/pts/0'/> <target type='isa-serial' port='0'> <model name='isa-serial'/> </target> <alias name='serial0'/> </serial> <console type='pty' tty='/dev/pts/0'> <source path='/dev/pts/0'/> <target type='serial' port='0'/> <alias name='serial0'/> </console> <channel type='unix'> <source mode='bind' path='/var/lib/libvirt/qemu/channel/target/domain-3-Windows 10/org.qemu.guest_agent.0'/> <target type='virtio' name='org.qemu.guest_agent.0' state='disconnected'/> <alias name='channel0'/> <address type='virtio-serial' controller='0' bus='0' port='1'/> </channel> <input type='mouse' bus='ps2'> <alias name='input0'/> </input> <input type='keyboard' bus='ps2'> <alias name='input1'/> </input> <hostdev mode='subsystem' type='pci' managed='yes'> <driver name='vfio'/> <source> <address domain='0x0000' bus='0x2f' slot='0x00' function='0x0'/> </source> <alias name='hostdev0'/> <address type='pci' domain='0x0000' bus='0x04' slot='0x00' function='0x0'/> </hostdev> <hostdev mode='subsystem' type='pci' managed='yes'> <driver name='vfio'/> <source> <address domain='0x0000' bus='0x2f' slot='0x00' function='0x1'/> </source> <alias name='hostdev1'/> <address type='pci' domain='0x0000' bus='0x05' slot='0x00' function='0x0'/> </hostdev> <hostdev mode='subsystem' type='pci' managed='yes'> <driver name='vfio'/> <source> <address domain='0x0000' bus='0x31' slot='0x00' function='0x3'/> </source> <alias name='hostdev2'/> <address type='pci' domain='0x0000' bus='0x06' slot='0x00' function='0x0'/> </hostdev> <hostdev mode='subsystem' type='pci' managed='yes'> <driver name='vfio'/> <source> <address domain='0x0000' bus='0x30' slot='0x00' function='0x3'/> </source> <alias name='hostdev3'/> <address type='pci' domain='0x0000' bus='0x07' slot='0x00' function='0x0'/> </hostdev> <hostdev mode='subsystem' type='usb' managed='no'> <source> <vendor id='0x08e4'/> <product id='0x017a'/> <address bus='1' device='3'/> </source> <alias name='hostdev4'/> <address type='usb' bus='0' port='1'/> </hostdev> <memballoon model='none'/> </devices> <seclabel type='dynamic' model='dac' relabel='yes'> <label>+0:+100</label> <imagelabel>+0:+100</imagelabel> </seclabel> </domain>
-
Is it possible to move lancache cache-data from one disk to another?
Trying to do it with krusader tells me that I can't access the cache-folders -
56 minutes ago, rix said:
Havent tried that, but if you can reproduce this issue, it sounds like its on googles end
Ok, I'll play a little with it, and then hope Google fixes it
-
On 1/5/2020 at 5:36 PM, rix said:
Its working completely fine on my part.
Just to be sure, did you try setting up a new instance from scratch, or did you log into an existing? Logging into an existing instance works for me, but new ones can't be created

-
I'm trying to get the Google Play Music Manager docker working.
Installing the image and logging in the first time works like a charm.
But after logging in, I get the following message:
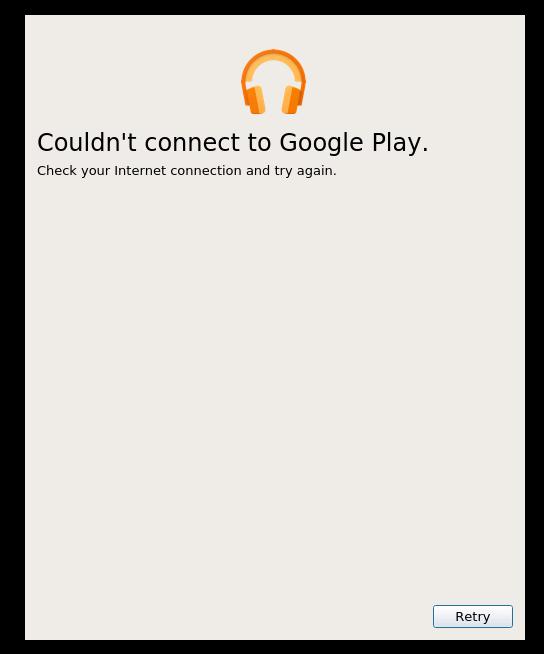
When looking in the log, I see the following:
Looking in the log it says: 2019-12-27 11:43:03,245 +0100 ERROR TId 0x14b62f5df740 Error: Domain (1) code (400) label (Bad Request) url (https://accounts.google.com/o/oauth2/[email protected]) [ExtendedWebPage.cpp:48 ExtendedWebPage::extension()]
If I navigate to the URL, I get the following message.
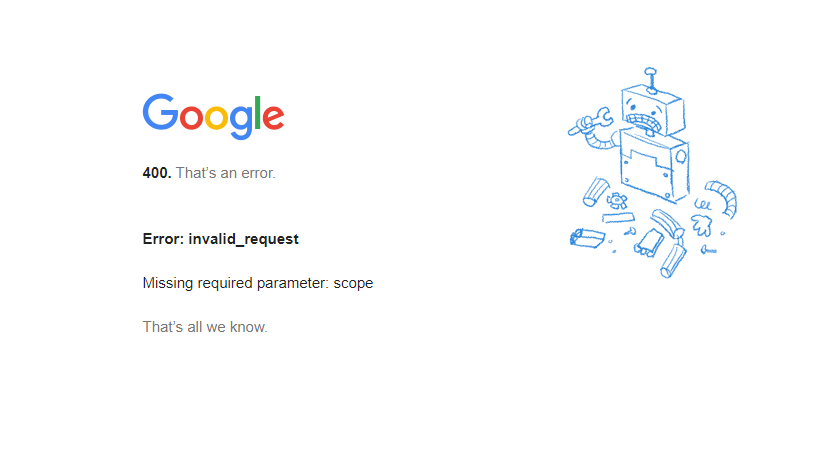
Can somebody else verify that the docker image is still functioning?
Am I doing something wrong?



Unraid suddenly just stops responding
in General Support
Posted
Ok, I guess I'll try enabling C-states again then")