




TODDLT
Members
-
Joined
-
Last visited
-
I have not seen those same errors, but I did find the below that appeared to occur during startup. I also see the same failed login errors randomly occurring but not continually. Newly noticed in the log: Any help or insight on the above is appreciated.
-
thanks for the help with this. working fine now.
-
I was hunting on another issue and came across a couple errors in my log file and wanting to know if these would be concerning. Hardware Error - it seems to say it was ECC corrected, but I've never actually seen this happen before. Is this a sign that something is failing? I found multiple instances of a "failed login, spaced throughout the end of the startup routine. There is no specific pattern of a command happening either immediately above or below the timeline of these fails. Typically there is either a Smart read or a disk fan adjustment command above and/or below those login fails, but some are close in time and others are hours apart so that doesnt seem like a pattern. Any way to track down what this is?
-
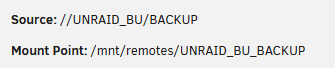
Thanks this is a big help, didn't know that list was there. I see you did it by IP address, but my SMB share is mounted by name. Which of these is correct? They are in order of what I think is most likely correct, but just checking. /usr/local/sbin/rc.unassigned mount //UNRAID_BU/BACKUP or /usr/local/sbin/rc.unassigned mount /mnt/remotes/UNRAID_BU_BACKUP or /usr/local/sbin/rc.unassigned mount //192.168.XX.XX/backup (I don't have anything mounted by IP on UNRAID, just the NAS Name. The IP is how I would find it on a windows machine)

-
Any help with this?
-
I THINK what I'm asking for here is a command line to put in a script file to first mount a drive that is visible in unassigned devices, and then after the rest of the script runs, unmount the drive before it ends. The situation: I have an external simple NAS (Synology) that is a complete backup of my unRAID data. There is a user script that is intended to run maybe twice a month to execute a set of rclone commands to complete the backup. The NAS is usually asleep, the script file will wake the NAS fine but unless I manually mount the drive the rclone actions just error out. Once I mount the drive the script runs fine. Then I've noticed twice now, after the script completes over the next few days my log file is filling up with thousands of the same error line (sample below). What I think is happening, is the NAS is going back to sleep and the drive is still mounted so it starts generating errors. The only flaw I can't explain in this logic, is that even after manually umounting the drive the errors continue to generate until I reboot the server to stop them, and then all is quiet again. Unless you see something else in this error message, I'm looking for two command lines for the user script. One to mount the drive after it wakes, and one to unmount the drive after the rclone commands run. EDIT: In the below excerpt there is what might be the unmount command line that came from me clicking the unmount button. Would this work inside the user script file: Unmount cmd: /sbin/umount -t cifs -l '/mnt/remotes/UNRAID_BU_BACKUP' 2>&1 If so then is the Mount command the excact same? Mount cmd: /sbin/mount -t cifs -l '/mnt/remotes/UNRAID_BU_BACKUP' 2>&1 EDIT 2: I tried the above and it didn't work. Thanks in advance for any help. Mar 29 16:20:58 TODD-Svr key.dns_resolver: UNRAID_BU.LOCAL: No address associated with name Mar 29 16:21:09 TODD-Svr key.dns_resolver: UNRAID_BU.LOCAL: No address associated with name Mar 29 16:21:20 TODD-Svr key.dns_resolver: UNRAID_BU.LOCAL: No address associated with name Mar 29 16:21:30 TODD-Svr webGUI: Successful login user root from 192.168.XXX.XXX Mar 29 16:21:31 TODD-Svr key.dns_resolver: UNRAID_BU.LOCAL: No address associated with name Mar 29 16:21:42 TODD-Svr unassigned.devices: Warning: shell_exec(/usr/bin/df '/mnt/remotes/UNRAID_BU_BACKUP' --output=size,used,avail | /bin/grep -v '1K-blocks' 2>/dev/null) took longer than 10.0s! Mar 29 16:21:42 TODD-Svr key.dns_resolver: UNRAID_BU.LOCAL: No address associated with name Mar 29 16:21:53 TODD-Svr unassigned.devices: Unmounting Remote SMB/NFS Share '//UNRAID_BU/BACKUP'... Mar 29 16:21:53 TODD-Svr unassigned.devices: Synching file system on '/mnt/remotes/UNRAID_BU_BACKUP'. Mar 29 16:21:53 TODD-Svr unassigned.devices: Unmount cmd: /sbin/umount -t cifs -l '/mnt/remotes/UNRAID_BU_BACKUP' 2>&1 Mar 29 16:21:53 TODD-Svr key.dns_resolver: UNRAID_BU.LOCAL: No address associated with name Mar 29 16:21:53 TODD-Svr unassigned.devices: Successfully unmounted '//UNRAID_BU.LOCAL/BACKUP' Mar 29 16:22:04 TODD-Svr key.dns_resolver: UNRAID_BU.LOCAL: No address associated with name Mar 29 16:22:16 TODD-Svr key.dns_resolver: UNRAID_BU.LOCAL: No address associated with name Mar 29 16:22:27 TODD-Svr key.dns_resolver: UNRAID_BU.LOCAL: No address associated with name Mar 29 16:22:38 TODD-Svr key.dns_resolver: UNRAID_BU.LOCAL: No address associated with name Mar 29 16:22:49 TODD-Svr key.dns_resolver: UNRAID_BU.LOCAL: No address associated with name Mar 29 16:23:00 TODD-Svr key.dns_resolver: UNRAID_BU.LOCAL: No address associated with name Mar 29 16:23:11 TODD-Svr key.dns_resolver: UNRAID_BU.LOCAL: No address associated with name Mar 29 16:23:22 TODD-Svr key.dns_resolver: UNRAID_BU.LOCAL: No address associated with name Mar 29 16:23:31 TODD-Svr unassigned.devices: Remote server 'UNRAID_BU.LOCAL' port '445' is not open; server appears to be offline. Mar 29 16:23:34 TODD-Svr key.dns_resolver: UNRAID_BU.LOCAL: No address associated with name Mar 29 16:23:45 TODD-Svr key.dns_resolver: UNRAID_BU.LOCAL: No address associated with name Mar 29 16:23:56 TODD-Svr key.dns_resolver: UNRAID_BU.LOCAL: No address associated with name
-
Thanks for the help, much appreciated. Do I actually need the WOL for Services Plugin for etherwake to work? I installed WOL for Services, but not sure its actually needed since etherwake is a separate install.
-
So like this? #!/bin/bash etherwake XXXXX sleep 120 rclone sync '/mnt/user/Backup Items' '/mnt/remotes/UNRAID_BU_BACKUP/Personal Backup' rclone sync '/mnt/user/Media' '/mnt/remotes/UNRAID_BU_BACKUP/Media'
-
OK, got that to work and tested the etherwake command in a terminal screen, worked perfect so TY. Last question: It takes 1-2 mins for the NAS to fully wake up. Do I need to have a "pause" occur in my userscript for the backup between etherwake, and the rclone commands? It will automatically wait for a drive to spin up but not sure Rclone will not just register an error when it hasn't woken up yet. What command would make it pause for 90 seconds between those commands?
-
Thanks for this. I'll do some reading and post further in that thread for help if needed. Much appreciated.
-
I have a separate NAS that is a portable backup (Synology). it's mounted as a drive in UNRAID with unassigned devices. The model I have does support WOL. Is there a command I can add to my userscript for running a backup (uses Rsync) that would trigger the WOL? simply running the script while the synology is asleep does nothing. Thanks in advance for any advice.
-
Does this backplain look like its open enough for cooling?

-
I'm planning a backup rig. Originally I was just going to use a hardware raid case with 4 drives and an eSATA connection and that was driven by size and portability. One of the criteria is the ability to pick it up and walk out of the house easily enough. However after an earlier post in here I decided to just make a separate unRAID rig, stability, flexibility, expandability.. all the reasons everyone here knows. However, that does leave me with more of a challenge to balance, size, portability and of course airflow. I've always been able to keep drives < 40dC and would like to keep that philosophy the backup is to protect data and cooler drives are part of that. I'm more concerned with the balance of size/cooling than it being a little more of a challenging build. I know there is no perfect case out there (though I don't know why ) I've read recent comments here about some of my top options but have missed if anyone actually spoke of drive temp outcomes after the build. Any thoughts are welcome and appreciated: https://www.amazon.com/N2-Aluminum-Support-Integrated-Removable/dp/B0BQJ6BCB7/?th=1 https://www.ebay.com/itm/134692492542 (this one is sold out on Amazon at the moment) https://www.amazon.com/AUDHEID-Compatible-Mini-ITX-Attached-Enclosure/dp/B096FD8WVS/ I like the FD 304, but I thik its nearly 18" deep making the portability more of a thing. Thanks in advance, other suggestings I may have missed are very welcome.
-
Thanks, 1st cycle will finish shortly tonight (3 days). I'm doing 2 and then will do a long self test. The self test took a day last time.
-
Does anyone have any thoughts, particularly on the MB options?


