




rayray14
Members
-
Joined
-
Last visited
-
Quick update. My server's been running fine since making the changes in my first post. Not sure why it wasn't working away.
-
Will do! Thanks for the help.
-
Here you go: Thanks!
-
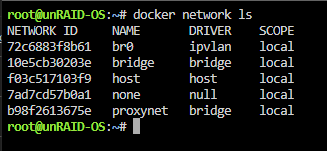
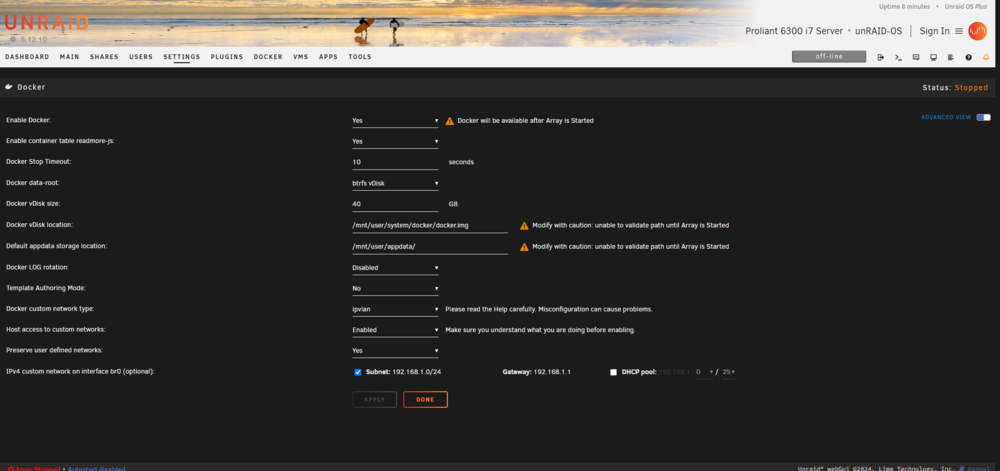
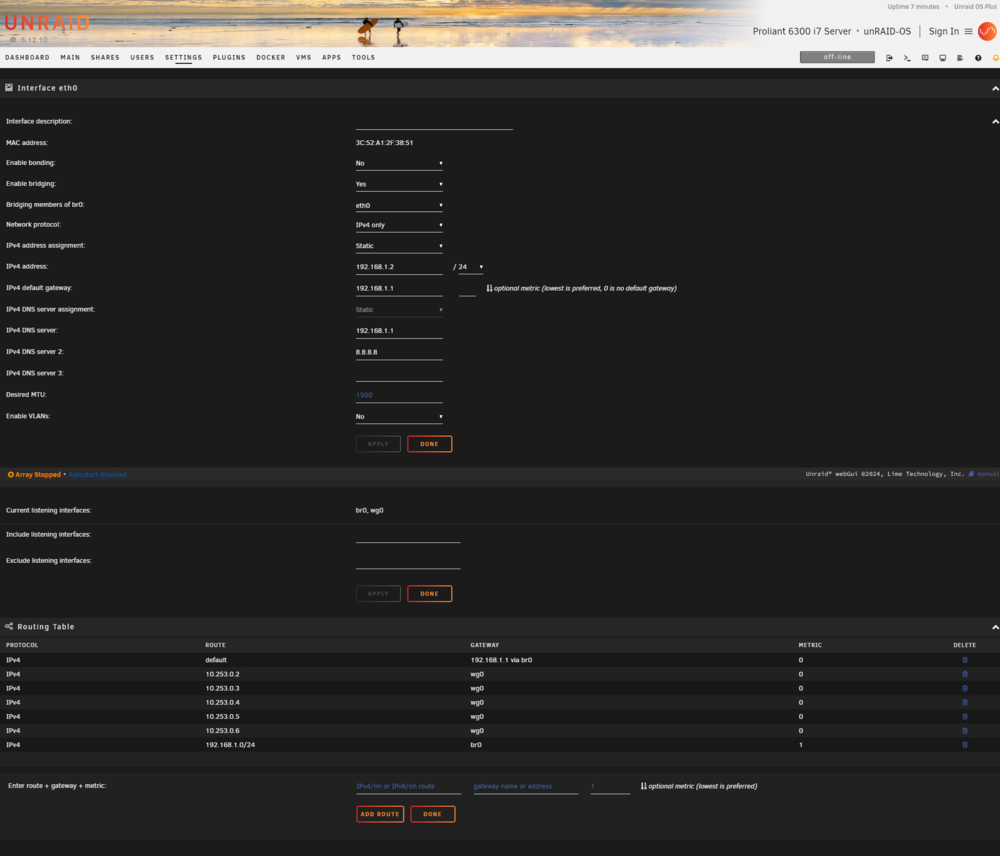
Good afternoon, My USB thumb drive failed and I replaced it with a new one. I used the USB creator tool, and then copied over the config folder from an offsite backup I had. After configuring the array (using an old screenshot), everything came back and it started working on the parity drive. I woke up the server being unresponsive and realized that the restore must not have maintained my old ipvlan docker config. When I checked the settings screen, IPVlan was selected, but the syslog and Fix Common Problems plugins still made mentions of macvlan. At ~10am (my time in the logs), I chose macvlan, hit save, then changed it back to ipvlan, saved, rebooted the system, and restarted the array. Fast forward to an hour ago where the system became unresponsive again. I've attached my syslog and settings screenshots. Note that I have a 10GB PCI card and don't use the onboard NIC. Thanks in advance for any help! syslog
-
Good afternoon, I started getting SSL errors this morning, and the Swag container logs state: Using Let's Encrypt as the cert provider SUBDOMAINS entered, processing Sub-domains processed are: home.robraymond.com E-mail address entered: [email protected] http validation is selected Certificate exists; parameters unchanged; starting nginx The cert is either expired or it expires within the next day. Attempting to renew. This could take up to 10 minutes. <-------------------------------------------------> <-------------------------------------------------> cronjob running on Wed Mar 27 15:41:58 EDT 2024 Running certbot renew - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - Processing /etc/letsencrypt/renewal/home.mydomain.com.conf - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - When I look at the swag\log\letsencrypt\logs.txt, I get more info (actual domain replaced with domain.com) cronjob running on Wed Mar 27 02:08:02 EDT 2024 Running certbot renew Saving debug log to /var/log/letsencrypt/letsencrypt.log - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - Processing /etc/letsencrypt/renewal/home.mydomain.com.conf - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - Failed to renew certificate home.mydomain.com with error: Missing command line flag or config entry for this setting: Please choose an account Choices: ['124eb8e48d2d@2024-02-28T19:41:02Z (c60d)', '9fba956a9707@2021-04-17T23:28:02Z (9ef6)'] - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - All renewals failed. The following certificates could not be renewed: /etc/letsencrypt/live/home.mydomain.com/fullchain.pem (failure) - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - 1 renew failure(s), 0 parse failure(s) Ask for help or search for solutions at https://community.letsencrypt.org. See the logfile /var/log/letsencrypt/letsencrypt.log or re-run Certbot with -v for more details. When I tried to run "certbot renew --account 124eb8e48d2d@2024-02-28T19:41:02Z" manually from the container's console, I get: Failed to renew certificate home.mydomain.com with error: Account at /etc/letsencrypt/accounts/acme-v01.api.letsencrypt.org/directory/124eb8e48d2d@2024-02-28T19:41:02Z does not exist - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - All renewals failed. The following certificates could not be renewed: /etc/letsencrypt/live/home.mydomain.com/fullchain.pem (failure) - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - 1 renew failure(s), 0 parse failure(s) Ask for help or search for solutions at https://community.letsencrypt.org. See the logfile /var/log/letsencrypt/letsencrypt.log or re-run Certbot with -v for more details. Any thoughts?
-
I had the same issues. I had to force a version when configuring my repostory. I'm watching the repo and will just use the latest once I've seen references to it being addressed:

-
Revering back to 1.29.1 fixed it for me as well. Thanks!
-
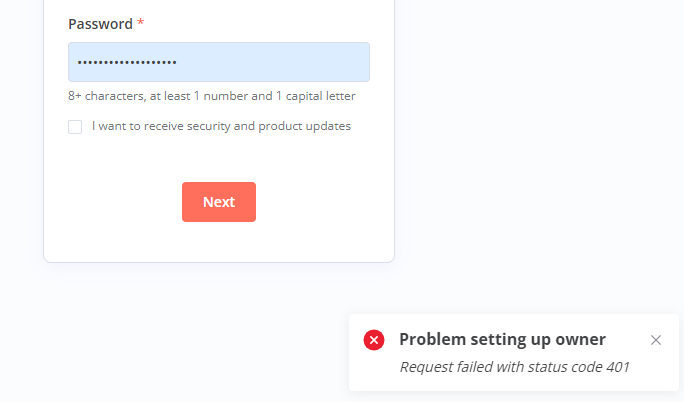
Good morning, I installed the container from CA, had the same issues as above, but the chown command worked and got me to the user setup page. Unfortunately, I get the following error: I appreciate any help!
-
Hello, Just curious if anyone knows of a docker container that would act like a VNC client, to connect to VNC servers? I'm basically looking to replicate what the Dynamix pluging does for VMs on Unraid, but to connect to other hosts on my LAN through a web browser.
-
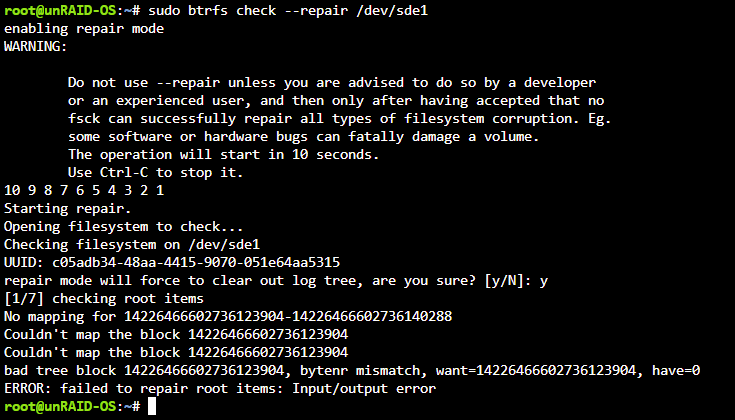
Ok, I just tried the repair and got this error: Looks like recreating the pool is the way to go.
-
Hello, I woke up to an email from my Unraid server with the subject: "cron for user root /sbin/fstrim -a -v | logger &> /dev/null" and body: fstrim: /etc/libvirt: FITRIM ioctl failed: Input/output error I did a "btrfs check --readonly" on my SSD cache drive and gave me the attached output (btrfs check status (read only).txt) In preparation for a "btrfs checking --repair", I ran the following to create a disk image of the drive in case I ever need to revert back: "sudo dd if=/dev/sde of=/mnt/disk1/ssdimage.img bs=4M status=progress" Before I attempt that repair, is there anything else I should do? btrfs check status (read only).txt
-
Thank you, that did the trick. I've been using unRaid for 5+ years and didn't know that was an option (probably because it's been rock solid and never had to think about it )
-
My SATA slots are full and I'd have to use an existing one. How should I proceed? I did confirm it does still mount and my data is intact in a prior step.
-
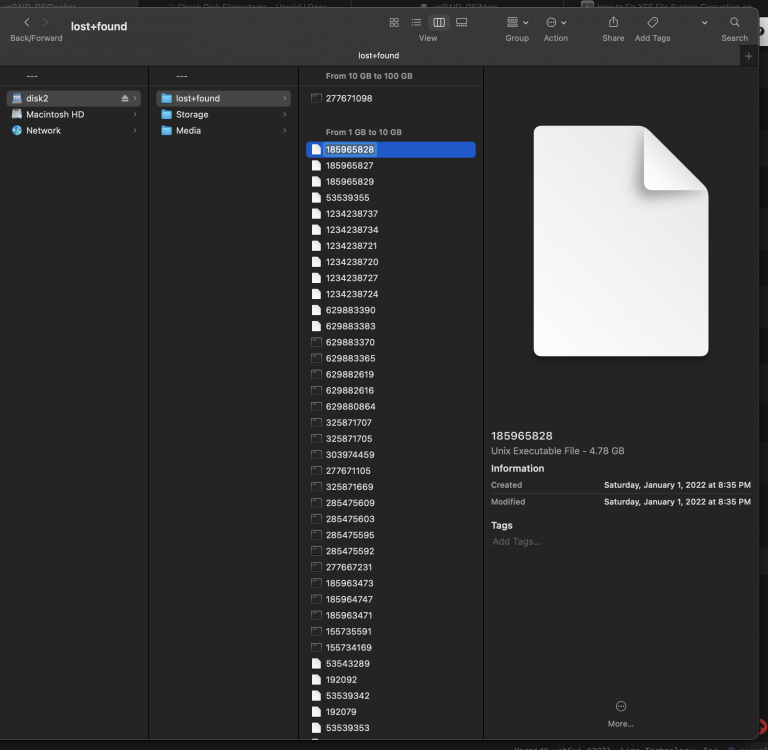
Thanks Trurl, that brought everything back to a running state, but I'm missing A LOT of data: What's the best way to go back to my old drive from this point, get to a working array, and then do the swap to the new 8TB disk? Disk2 Filesystem FIX.txt
-
Without understanding everything, this looks pretty bad. Safe to assume I should re-run it without the -n flag? Disk2 Filesystem Check.txt







