




quinnjudge
Members
-
Joined
-
Last visited
-
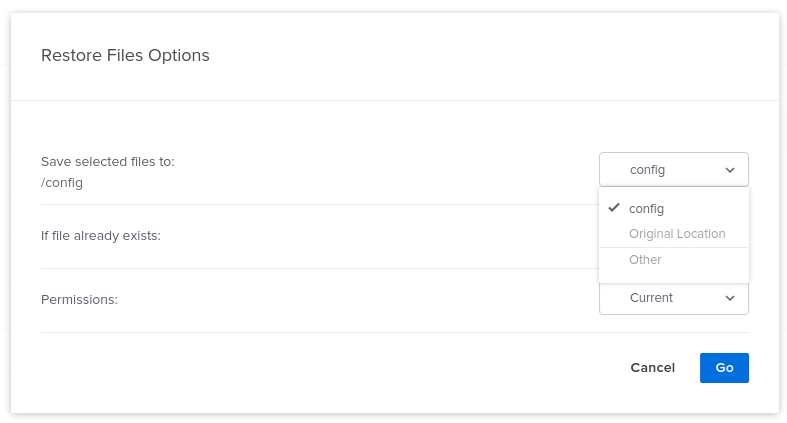
I recently went in to CrashPlan to do a test restore, but noticed when I try and change the restore destination from /config to my restore location, the container crashes and I need to restart it. I searched and found some similar crashes from a few years ago, but they all look like the issue was resolved...can anyone confirm if there is a new issue with picking the restore location causing a crash? To reproduce: Choose 'Other'; instant crash
-
I removed the bandwidth limit in CBB, and the backup job was successful; no errors on the files like before - thanks!!! So, is this an issue with CBB or with BackBlaze B2?
-
Yes; my thought was to ensure a backup does not interfere with web conferencing software (I'm still working full-time from my home office)...I have the limit for cloud storage set to approx. 80% of available upload bandwidth.
-
Hello, hoping to get a little direction... I've been using this container for a few months to back up to BackBlaze B2, and it has been terrific! Recently a couple of files have been giving me trouble, and I'm not sure where to start as far as troubleshooting. When I try and back up files generated from CA Appdata Backup / Restore v2, get the following message in CBB: SSL_write() returned SYSCALL, errno = 32 and the backup job fails. When I remove these files from the backup job it runs successfully, but adding the files back in to the backup job will cause the error again. Any idea where the problem may lie, or who to start the right conversation with? Thanks in advance!
