




Londinium
Members
-
Joined
-
Last visited
Everything posted by Londinium
-
I'm on 6.11.5, just installed the latest unbalenceD and moved few files across drives (<1Gb), looks OK 👍
-
I have finally decided to revert to version 6.11.5. My drives now remain stopped as they should. I suspect there may be an issue with version 6.12.x. I'll wait for either version 6.12.5 or 6.13.x to try an upgrade again. Anyway, thanks to everyone for trying to help me resolve this issue!
-
A new test conducted this morning without success. I restarted in safe mode with my spin-down delay set to 15 minutes, and I didn't start the array. Despite that, every 15 minutes, the disks stopped and then restarted at the beginning of the next minute after their shutdown. Afterward, I even physically disconnected my server from the network (hence the 'link is down' and following lines in the log), the disks still stopped after 15 minutes and started up again a the begging of the next minute after their shutdown. Oct 9 11:08:50 unRAID emhttpd: spinning down /dev/sdd Oct 9 11:08:50 unRAID emhttpd: spinning down /dev/sdb Oct 9 11:08:50 unRAID emhttpd: spinning down /dev/sdc Oct 9 11:09:05 unRAID emhttpd: read SMART /dev/sdd Oct 9 11:09:14 unRAID emhttpd: read SMART /dev/sdb Oct 9 11:09:21 unRAID emhttpd: read SMART /dev/sdc Oct 9 11:24:03 unRAID emhttpd: spinning down /dev/sdd Oct 9 11:24:07 unRAID emhttpd: spinning down /dev/sdb Oct 9 11:24:16 unRAID emhttpd: spinning down /dev/sdc Oct 9 11:25:06 unRAID emhttpd: read SMART /dev/sdd Oct 9 11:25:14 unRAID emhttpd: read SMART /dev/sdb Oct 9 11:25:22 unRAID emhttpd: read SMART /dev/sdc Oct 9 11:34:19 unRAID kernel: tg3 0000:03:00.0 eth0: Link is down Oct 9 11:34:19 unRAID dhcpcd[1129]: eth0: carrier lost Oct 9 11:34:19 unRAID avahi-daemon[2862]: Withdrawing address record for 192.168.1.6 on eth0. Oct 9 11:34:19 unRAID avahi-daemon[2862]: Leaving mDNS multicast group on interface eth0.IPv4 with address 192.168.1.6. Oct 9 11:34:19 unRAID avahi-daemon[2862]: Interface eth0.IPv4 no longer relevant for mDNS. Oct 9 11:34:19 unRAID dhcpcd[1129]: eth0: deleting route to 192.168.1.0/24 Oct 9 11:34:19 unRAID dhcpcd[1129]: eth0: deleting default route via 192.168.1.1 Oct 9 11:34:21 unRAID monitor: Stop running nchan processes Oct 9 11:34:22 unRAID ntpd[1285]: Deleting interface #1 eth0, 192.168.1.6#123, interface stats: received=37, sent=37, dropped=0, active_time=2436 secs Oct 9 11:34:22 unRAID ntpd[1285]: 162.159.200.123 local addr 192.168.1.6 -> <null> Oct 9 11:40:03 unRAID emhttpd: spinning down /dev/sdd Oct 9 11:40:08 unRAID emhttpd: spinning down /dev/sdb Oct 9 11:40:16 unRAID emhttpd: spinning down /dev/sdc Oct 9 11:41:05 unRAID emhttpd: read SMART /dev/sdd Oct 9 11:41:14 unRAID emhttpd: read SMART /dev/sdb Oct 9 11:41:21 unRAID emhttpd: read SMART /dev/sdc Oct 9 11:56:02 unRAID emhttpd: spinning down /dev/sdd Oct 9 11:56:08 unRAID emhttpd: spinning down /dev/sdb Oct 9 11:56:16 unRAID emhttpd: spinning down /dev/sdc Oct 9 11:56:24 unRAID ntpd[1285]: no peer for too long, server running free now Oct 9 11:57:05 unRAID emhttpd: read SMART /dev/sdd Oct 9 11:57:13 unRAID emhttpd: read SMART /dev/sdb Oct 9 11:57:21 unRAID emhttpd: read SMART /dev/sdc What I understand, and this has been very consistent since the beginning of my tests, is that the disks do indeed stop when they are supposed to stop (based on the spin-down delay). If they stop within the expected time frame, it means that no processes are accessing them during that time. However, systematically at the beginning of the next minute (which for me implies it's related to some kind of a scheduled task), all my disks turn on. I'm not sure exactly when this problem started, but I imagine it's recent because I would have definitely noticed it. In the past few weeks, the only significant changes made to my server are: The update to version 6.12.4 from 6.11.5 (I waited a long time to install 6.12, and it was only when I didn't see any more bug fixes for a few weeks after the release of 6.12.4 that I finally decided to install it). The replacement of my CPU (Celeron G1610T > Xeon E3-1265L V2). The replacement of a 4GB ECC RAM module with an 8GB one (followed by several hours of memtest). The replacement of my SATA SSD cache drive with a much faster M.2 drive. Having disabled as many things as possible on my server, having conducted all these tests, and having shown that stopping the cron monitor keeps my disks down, I'm running out of ideas.
-
Thanks for the shortcut! That code snippet should definitely be included somewhere useful for everyone here 👍 Unfortunately, while I was comparing disk1+disk2 Vs. user (witch should trigger the same results) I already tried just in case disk1 Vs. disk2 with no results. I still tried your way but same result, output2.txt is empty, sadly!
-
That's why I've only disabled it for 5 minutes.
-
If you are referring to this... Oct 8 12:32:01 unRAID crond[1304]: exit status 127 from user root /usr/local/emhttp/plugins/dynamix/scripts/monitor &> /dev/null Oct 8 12:33:01 unRAID crond[1304]: exit status 127 from user root /usr/local/emhttp/plugins/dynamix/scripts/monitor &> /dev/null Oct 8 12:34:02 unRAID crond[1304]: exit status 127 from user root /usr/local/emhttp/plugins/dynamix/scripts/monitor &> /dev/null Oct 8 12:35:01 unRAID crond[1304]: exit status 127 from user root /usr/local/emhttp/plugins/dynamix/scripts/monitor &> /dev/null ... then it's not a bug, it's only when I've disabled the monitor by renaming it, the cron couldn't just find the script to run. I deliberately included these lines for context. I know correlation is not causation but with all the tests I've conducted (including disabling docker, rebooting in safe mode and physically disconnecting the server from network), it's the only way my drives have stayed down. So I hope that it helps narrowing down the causes.
-
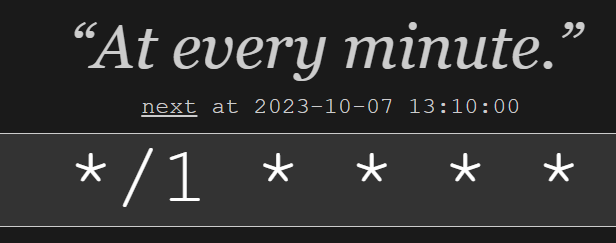
Thank you for your response! I understand that there is a possibility of having a duplicate file. I also understand that it's a delicate situation and it shouldn't happen, and Unraid it normally prevents this from happening. However, based on the tests I conducted earlier, such as disabling my Dockers, starting in safe mode (so with no plugins activated), using the OpenFiles plugin, and physically disconnecting my server from the network, I wonder what process would specifically try to access a duplicate file on one of these 4 shares, which contain only movies, music, family videos, and photos. I acknowledge that it's possible, but I imagine there would be some trace of it in a log somewhere, at least I hope so. I also assume that Unraid should be able to detect such a critical situation. In the meantime, I compared the entire contents of my 4 shares with their respective contents on disk1/disk2. To do this, I used the 'find' command as follows: find /mnt/disk1/music -type f > disk1_music.txt find /mnt/disk2/music -type f > disk2_music.txt find /mnt/user/music -type f > user_music.txt This allowed me to create an exhaustive list of all file paths on my disks and shares instantly. I then imported this into VSCode, combined the disk1/disk2 files, removed any unnecessary beginning of each line, sorted everything alphabetically, and compared disk/user. Unfortunately, I apparently have no duplicates among the 202,982 files in these 4 shares spread across 2 disks. Given the speed (instantaneous) of listing the files, I imagine this could easily be integrated into a script and used in a plugin like Fix Common Problems, I will work on a User Script about this when I'll have some time. In the meantime, I also pursued another lead because I noticed that my disks reactivated very precisely at the beginning of a new minute. For example, if I stop them at 12:31:01, they will only wake up 59 seconds later, at 12:32:00. However, if I stop them at 12:32:45, they will wake up only 15s later, at exactly 12:33:00. I repeated this test several times with only success, and this makes me think it could be a cron job that runs every minute. I listed (using crontab -l) and checked in /etc/cron.d/root, and the only cron job that runs at the beginning of every minute is the one I mentioned earlier : */1 * * * * /usr/local/emhttp/plugins/dynamix/scripts/monitor &> /dev/null So, I investigated further, and temporarily renamed /usr/local/sbin/mover to /usr/local/sbin/mover2. I then manually stop my disks and waited for 5 minutes. They only woke up after I renamed /usr/local/sbin/mover2 back to /usr/local/sbin/mover (and at the beginning of the next minute). And when I say "they only woke up" I mean I physically heard them waking up in my server, which is right next to me. I mention this because I assume that disabling this cron job would make the disk activity display on the main tab inaccurate. Oct 8 12:31:01 unRAID crond[1304]: exit status 127 from user root /usr/local/emhttp/plugins/dynamix/scripts/monitor &> /dev/null Oct 8 12:31:08 unRAID emhttpd: spinning down /dev/sdd Oct 8 12:31:08 unRAID emhttpd: spinning down /dev/sdb Oct 8 12:31:08 unRAID emhttpd: spinning down /dev/sdc Oct 8 12:31:14 unRAID kernel: mdcmd (42): set md_write_method 0 Oct 8 12:32:01 unRAID crond[1304]: exit status 127 from user root /usr/local/emhttp/plugins/dynamix/scripts/monitor &> /dev/null Oct 8 12:33:01 unRAID crond[1304]: exit status 127 from user root /usr/local/emhttp/plugins/dynamix/scripts/monitor &> /dev/null Oct 8 12:34:02 unRAID crond[1304]: exit status 127 from user root /usr/local/emhttp/plugins/dynamix/scripts/monitor &> /dev/null Oct 8 12:35:01 unRAID crond[1304]: exit status 127 from user root /usr/local/emhttp/plugins/dynamix/scripts/monitor &> /dev/null Oct 8 12:36:05 unRAID emhttpd: read SMART /dev/sdd Oct 8 12:36:14 unRAID emhttpd: read SMART /dev/sdb Oct 8 12:36:14 unRAID kernel: mdcmd (43): set md_write_method 1 Oct 8 12:36:21 unRAID emhttpd: read SMART /dev/sdc I still don't know if this cron job is the cause, but I think it's a step forward since it's the first time I've been able to keep my disks powered off. As a side note, I compared the code of the monitor script between version 6.11.5 (the version I was previously on) and version 6.12.4, but aside from a few differences (in addition to the change in the variables access system), nothing caught my eye (but I'm definitely not very familiar with Unraid at that level). Does anyone have any ideas?
-
Thank you for your answer! Before testing with the dupeGuru docker and searching for duplicate files on my 8TB (I imagine it will take some time), I first tried stopping the array, which I assume stops the shares. I also lowered the spin-down delay to 15 minutes, and within 30 minutes, the drives stopped and instantly restarted twice : Oct 7 18:44:37 unRAID emhttpd: spinning down /dev/sdd Oct 7 18:44:37 unRAID emhttpd: spinning down /dev/sdb Oct 7 18:44:37 unRAID emhttpd: spinning down /dev/sdc Oct 7 18:45:05 unRAID emhttpd: read SMART /dev/sdd Oct 7 18:45:14 unRAID emhttpd: read SMART /dev/sdb Oct 7 18:45:21 unRAID emhttpd: read SMART /dev/sdc Oct 7 19:00:02 unRAID emhttpd: spinning down /dev/sdd Oct 7 19:00:07 unRAID emhttpd: spinning down /dev/sdb Oct 7 19:00:16 unRAID emhttpd: spinning down /dev/sdc Oct 7 19:01:05 unRAID emhttpd: read SMART /dev/sdd Oct 7 19:01:14 unRAID emhttpd: read SMART /dev/sdb Oct 7 19:01:21 unRAID emhttpd: read SMART /dev/sdc To be honest, I'm having trouble understanding how a duplicate file on two drives can keep my array running. I imagine it's a bug and not a feature, but if it's a bug do we know the logic behind why it keeps the drives spinning? As for the unBalance plugin, I installed it following the earlier message about some of my shares being on multiple disks, so I'm pretty sure the plugin is not the cause. I had never used this plugin before, and I have never manually moved files from one disk to another. I only use Samba shares from my Windows machine.
-
Good point! I had never thought of that, but it now seems logical. I guess I always assumed that Unraid would handle that automatically for me. Since I'm a bit tight on disk space right now (I only have ~5% free space left, so I'll have to add a disk), I was only able to consolidate a few shares onto a single disk, reducing from 8 to 4 shares on two disks : H--------a shareUseCache="no" # Share exists on disk1, disk2 M-----e shareUseCache="no" # Share exists on disk1, disk2 P----s shareUseCache="no" # Share exists on disk1, disk2 V----s shareUseCache="no" # Share exists on disk1, disk2 Just for your information, I used the unBalance plugin and then modified the "Included disk(s)" value for each of those shares. By the way, I ran a "Docker Safe New Permissions" on all my shares following the error message I received when using unBalance. I imagine that all of this probably has no connection to my issue, as nothing seems to be accessing my shares according to the tests I've conducted before. However, I agree that it would be progress to see only one disk wake up instead of three! In the meantime, the problem still persists. I unplugged my unused SATA SSD just in case, but it didn't change anything. I also monitored the read/write counter on the main screen, and nothing changed in the minutes following the spin down. My list of open files in the OpenFiles plugin is still quite small: auto_turbo.php /usr/local/emhttp (working directory) device_list /usr/local/emhttp (working directory) disk_load /usr/local/emhttp (working directory) lsof /usr/local/emhttp (working directory) lsof /usr/local/emhttp (working directory) notify_poller /usr/local/emhttp (working directory) parity_list /usr/local/emhttp (working directory) php-fpm /usr/local/emhttp (working directory) php-fpm /usr/local/emhttp (working directory) php-fpm /usr/local/emhttp (working directory) php-fpm /usr/local/emhttp (working directory) php-fpm /usr/local/emhttp (working directory) php-fpm /usr/local/emhttp (working directory) php-fpm /usr/local/emhttp (working directory) php-fpm /usr/local/emhttp (working directory) php-fpm /usr/local/emhttp (working directory) php-fpm /usr/local/emhttp (working directory) session_check /usr/local/emhttp (working directory) sh /usr/local/emhttp (working directory) sleep /usr/local/emhttp (working directory) unraid-api /usr/local/bin/unraid-api (working directory) update_1 /usr/local/emhttp (working directory) update_2 /usr/local/emhttp (working directory) update_3 /usr/local/emhttp (working directory) wg_poller /usr/local/emhttp (working directory) I also noticed the following line in my /etc/cron.d/root. If I understand correctly, it's a script that runs every minute? */1 * * * * /usr/local/emhttp/plugins/dynamix/scripts/monitor &> /dev/null I've gone through the script's code, and it performs tests on the array's disks, including temperature readings, SMART data, and disk usage. I haven't delved deeper, but could this potentially be related to my issue? unraid-diagnostics-20231007-1316.zip
-
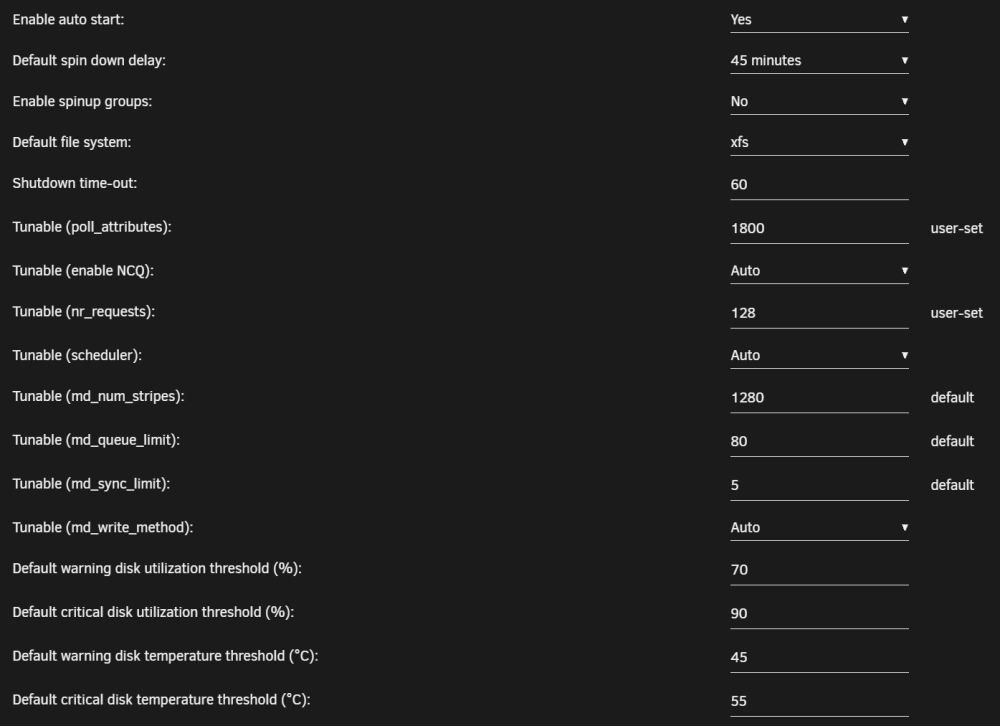
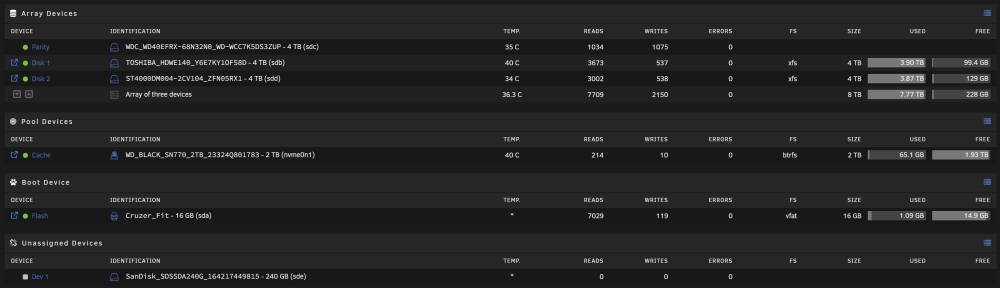
Hello again guys, I see that I have another problem that is probably not related to my previous one, but perhaps it is connected to my hardware upgrade (new CPU and NVMe as cache instead of SSD SATA) or my update to Unraid version 6.12.4 (which I recently updated directly from 6.11.x). For the record I'm on the same Unraid installation since late 2016 (version 6.2) without any major problem. My 3 hard drives never spin down more than a minute. As soon as they spin down (either after the 45min delay or after I manually spin them down), all 3 of them turn back on after a few seconds. I don't often check my Unraid dashboard (let's say once a week), so I can't precisely say when this started happening. Here are my drives : My logs are full of this (every time in the same order, sdd > sdb > sdc), I guess the SMART polling is not in cause and occurs only because drives wake up (?) for any reason : Oct 6 10:50:45 unRAID emhttpd: spinning down /dev/sdd Oct 6 10:50:45 unRAID emhttpd: spinning down /dev/sdb Oct 6 10:50:45 unRAID emhttpd: spinning down /dev/sdc Oct 6 10:51:06 unRAID emhttpd: read SMART /dev/sdd Oct 6 10:51:14 unRAID emhttpd: read SMART /dev/sdb Oct 6 10:51:22 unRAID emhttpd: read SMART /dev/sdc Oct 6 10:52:48 unRAID emhttpd: spinning down /dev/sdd Oct 6 10:52:48 unRAID emhttpd: spinning down /dev/sdb Oct 6 10:52:48 unRAID emhttpd: spinning down /dev/sdc Oct 6 10:53:06 unRAID emhttpd: read SMART /dev/sdd Oct 6 10:53:14 unRAID emhttpd: read SMART /dev/sdb Oct 6 10:53:22 unRAID emhttpd: read SMART /dev/sdc Oct 6 10:59:24 unRAID emhttpd: spinning down /dev/sdd Oct 6 10:59:24 unRAID emhttpd: spinning down /dev/sdb Oct 6 10:59:24 unRAID emhttpd: spinning down /dev/sdc Oct 6 11:00:05 unRAID emhttpd: read SMART /dev/sdd Oct 6 11:00:14 unRAID emhttpd: read SMART /dev/sdb Oct 6 11:00:21 unRAID emhttpd: read SMART /dev/sdc I have conducted the following tests: I stopped all my Dockers and disabled Docker : no change I deleted my Samba network drives on my Windows machine, just in case : no change I removed the Disk Location plugin : no change I restarted in safe mode (no plugins) and after starting the array : no change I set the spin-down delay to 15min, unplugged my server network cable for 45min and when I plugged it back saw that the problem occurred twice : no change I also have read lots of topics here on the forum and on r/unRAID, I saw few people having problems since the 6.12 but nearly every time with ZFS arrays which I don't have. I installed the Open Files plugin, and the only open files don't seem to be problematic (here with Docker disabled) : auto_turbo.php /usr/local/emhttp (working directory) device_list /usr/local/emhttp (working directory) disk_load /usr/local/emhttp (working directory) file_manager /usr/local/emhttp (working directory) lsof /usr/local/emhttp (working directory) lsof /usr/local/emhttp (working directory) notify_poller /usr/local/emhttp (working directory) parity_list /usr/local/emhttp (working directory) php-fpm /usr/local/emhttp (working directory) php-fpm /usr/local/emhttp (working directory) php-fpm /usr/local/emhttp (working directory) php-fpm /usr/local/emhttp (working directory) php-fpm /usr/local/emhttp (working directory) run_cmd /usr/local/emhttp (working directory) session_check /usr/local/emhttp (working directory) sh /usr/local/emhttp (working directory) sleep /usr/local/emhttp (working directory) tail /usr/local/emhttp (working directory) ttyd /usr/local/emhttp (working directory) ttyd /usr/local/emhttp (working directory) unraid-api /usr/local/bin/unraid-api (working directory) update_1 /usr/local/emhttp (working directory) update_2 /usr/local/emhttp (working directory) update_3 /usr/local/emhttp (working directory) wg_poller /usr/local/emhttp (working directory) Here are my general disk settings : Any ideas? unraid-diagnostics-20231006-1855.zip
-
Thank you! By deleting the directory on /mnt/disk1, the issue was instantly resolved, and my /appdata immediately switched to 'exclusive access: Yes.'. I restarted Docker and everything is working fine, many thanks!
-
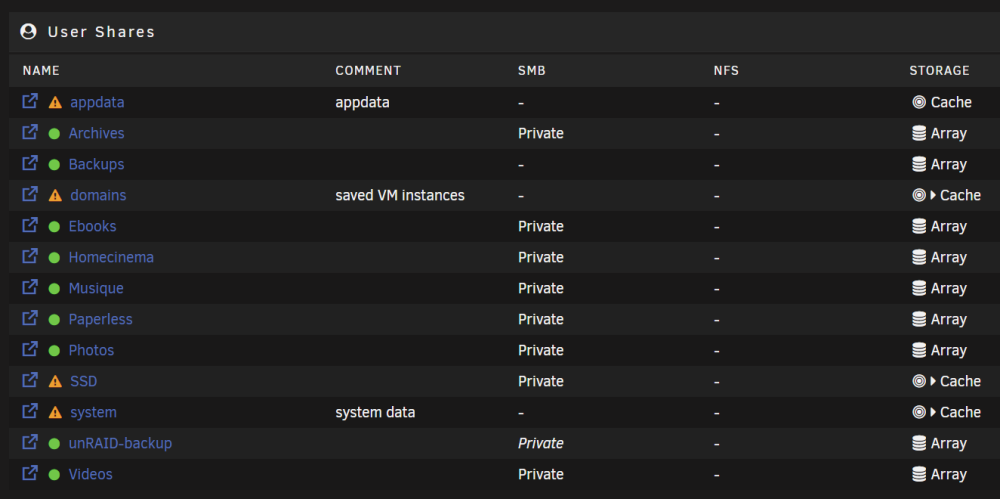
Hello everyone! Today, I made some upgrades to my HP MicroServer Gen 8 (RAM/CPU/NVMe), which has been running the same Unraid installation since late 2016 (what a long and stable way since 6.2, a big thank you to the whole team btw). I had planned to install a new 2TB NVMe SSD for cache/Docker appdata in place of my 256GB SATA SSD. I followed the documentation to the letter, but I'm encountering a strange issue with my /appdata. I believe I have a very similar problem to this one because I'm getting the same error message: "Fix Common Problems: Warning: Share appdata set to cache-only, but files / folders exist on the array." The difference from the topic above is that my /appdata directory at the root of my array is not empty, and the changes I make inside it are instantly reflected on my NVMe SSD (and vice versa). I enabled the exclusive access property a few days ago (following an update from 6.11.x to 6.12.4), which is working on my other three shares on my NVMe SSD, and I can see the symlinks there : I've temporarily disabled Docker. Since I'm afraid to delete this directory, I tried renaming it aggressively : mv /mnt/user/appdata/ /mnt/user/appdata2/ But it didn't change anything except the directory was also renamed on the NVMe SSD (I renamed it back to /appdata). Could someone point me in the right direction? Thank you! unraid-diagnostics-20231004-2351.zip
-
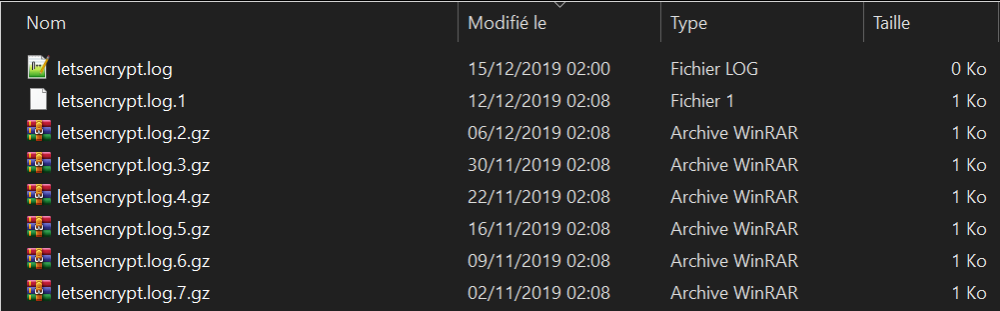
Hi, I've now received twice the "Let's Encrypt certificate expiration notice for domain" email and my certificate will now expire in 10 days. I've been using this Let's Encrypt container for two years without a single problem (btw : thanks a lot!) but it seems something went wrong few weeks ago. When going to my \appdata\letsencrypt\log\letsencrypt folder, no log have been written since the 15th of december : (ordered by last modification date) I don't recall modifying any config on my Unraid server in this timeframe, except upgrading to the final 6.8.0 (directly from the last 6.7.x version) and installing Wireguard (which is working fine). I don't know how to check the exact date I've installed Unraid 6.8.0 but it was quickly after its release. What I've tried without any success : restarting the docker restarting the server updating to Unraid 6.8.1 Looking for the the following informations : Logs are well written in the parent directories \log\fail2ban, \log\nginx and \log\php so I guess it's not a file permission issue. I see the following alert/error in the docker logs but from what I've found in this thread it's no big deal : nginx: [alert] detected a LuaJIT version which is not OpenResty's; many optimizations will be disabled and performance will be compromised (see https://github.com/openresty/luajit2 for OpenResty's LuaJIT or, even better, consider using the OpenResty releases from https://openresty.org/en/download.html) nginx: [error] lua_load_resty_core failed to load the resty.core module from https://github.com/openresty/lua-resty-core; ensure you are using an OpenResty release from https://openresty.org/en/download.html (rc: 2, reason: module 'resty.core' not found: no field package.preload['resty.core'] no file './resty/core.lua' no file '/usr/share/luajit-2.1.0-beta3/resty/core.lua' no file '/usr/local/share/lua/5.1/resty/core.lua' no file '/usr/local/share/lua/5.1/resty/core/init.lua' no file '/usr/share/lua/5.1/resty/core.lua' no file '/usr/share/lua/5.1/resty/core/init.lua' no file '/usr/share/lua/common/resty/core.lua' no file '/usr/share/lua/common/resty/core/init.lua' no file './resty/core.so' no file '/usr/local/lib/lua/5.1/resty/core.so' no file '/usr/lib/lua/5.1/resty/core.so' no file '/usr/local/lib/lua/5.1/loadall.so' no file './resty.so' no file '/usr/local/lib/lua/5.1/resty.so' no file '/usr/lib/lua/5.1/resty.so' no file '/usr/local/lib/lua/5.1/loadall.so') The docker container doesn't stop. I've double checked my ports forwarding : and tested with success both my 80 and 443 ports with https://www.canyouseeme.org because I had issue with my ports forwarding two years ago when installing this docker. Any help would be greatly appreciated 😅 Thanks! (my Unraid diagnostics are in attachment) Edit : Except for this issue, I have no problem accessing my services (e.g. : AirSonic / Ubooquity) from outside my network using my https url. Londinium unraid-diagnostics-20200113-1716.zip


-
Same here, solved by forwarding port 80 to 81 on my router (check the http port in Letsencrypt docker configuration). The 401 unauthorized I was getting previously was probably coming from unRAID web UI Thanks!
-
Hi! I have the same exact problem as MrChunky. Letsencrypt docker stopped working very recently. I have already : set the HTTPVAL variable to true uncommented the port 80 server section in my default nginx file opened the port 80 on my router restarted Letsencrypt docker And I get a 401 unauthorized in the docker log file : Failed authorization procedure. foobar.duckdns.org (http-01): urn:acme:error:unauthorized :: The client lacks sufficient authorization :: Invalid response from http://foobar.duckdns.org/.well-known/acme-challenge/xxx [xx.xxx.xx.xxx]: 401 IMPORTANT NOTES: - The following errors were reported by the server: Domain: foobar.duckdns.org Type: unauthorized Detail: Invalid response from http://foobar.duckdns.org/.well-known/acme-challenge/UzrREGhzZemotfGsM076gy9aQdCi--8H_2OcGBMM-T4 [xx.xxx.xx.xxx]: 401 Anyone else got this ? Could it be linked to the tls-sni challenge problem ? FYI, this docker has been working fine for the last 2 months (thanks by the way!) Londinium








