

RevelRob
-
Posts
58 -
Joined
-
Last visited
Content Type
Profiles
Forums
Downloads
Store
Gallery
Bug Reports
Documentation
Landing
Posts posted by RevelRob
-
-
Hi,
I posted this Saturday and thought all was good, but I've been experiencing additional issues that are odd:
I am in the process of preclearing a new replacement disk for the one that is failing. I've turned VMs and Docker off so that there are no additional resources being used elsewhere and to not stress out the parity drive that would e emulating the disabled disk. The problem is, after a period of time, the server becomes unresponsive with no gui loading nor am I ale to SSH in. Even sending an orderly shutdown via IPMI fails. So I have to power cycle via IPMI. It also runs extremely slowly now even after a reboot. I was on an older version (6.12.6) and updated to 6.12.8 to see if that was the issue. I ran a smart test on the new drive to see if it was the issue but it came back no errors. Can anyone tell me idf they see something awry from the diagnostics file I pulled just now after a restart and pre-clear start? It also took the diagnostics almost 20 minutes to generate.
Thanks!
-
Haha. Nice. Too bad I have half a dozen of these to do this with now. Thanks!
-
Hi all. I have a disabled disk and am wondering if it looks like it is going bad or if something else is happening here.
I already purchased a new drive that is pre-clearing in case it is bad but want to know for sure to avoid throwing it out.
Unraid version 6.12.6
Thanks!
-
Thanks, it had already been replaced but I figured I’d see what the preclear plug-in said about it. She gone.
-
On 10/7/2022 at 2:57 PM, trurl said:
Do any of your other disks show SMART warnings on the Dashboard page?
Only the cache pool; however, it is only CRC Error Count issues which I have read could be due to bad sata cables. I ordered replacement ones in which will hopefully help. I am rebuilding the dead drive with a replacement now. I was wrong about the dead drive being a Seagate barracuda by the way. It’s a Seagate ironwolf which should be better quality than a barracuda.
Also, I ran a pre clear on the dead drive for fun and it just finished. Here’s the finished status preview:
#################################################################################################### # Unraid Server Preclear of disk Z730W84C # # Cycle 1 of 1, partition start on sector 64. # # # # Step 1 of 6 - Pre-read verification: [6:27:17 @ 129 MB/s] SUCCESS # # Step 2 of 6 - Erasing the disk: [6:21:54 @ 130 MB/s] SUCCESS # # Step 3 of 6 - Zeroing the disk: [5:48:43 @ 143 MB/s] SUCCESS # # Step 4 of 6 - Writing Unraid's Preclear signature: SUCCESS # # Step 5 of 6 - Verifying Unraid's Preclear signature: SUCCESS # # Step 6 of 6 - Post-Read verification: FAIL # # # # # #################################################################################################### # Cycle elapsed time: 18:38:14 | Total elapsed time: 18:38:14 # #################################################################################################### #################################################################################################### # S.M.A.R.T. Status (device type: default) # # # # ATTRIBUTE INITIAL STATUS # # Reallocated_Sector_Ct 1000 - # # Power_On_Hours 33334 - # # End-to-End_Error 0 - # # Reported_Uncorrect 37 - # # Airflow_Temperature_Cel 36 - ->Failed in Past<- # # Current_Pending_Sector 800 - # # Offline_Uncorrectable 800 - # # UDMA_CRC_Error_Count 0 - # # # #################################################################################################### # # ####################################################################################################In case that is hard to read, here’s a screenshot:
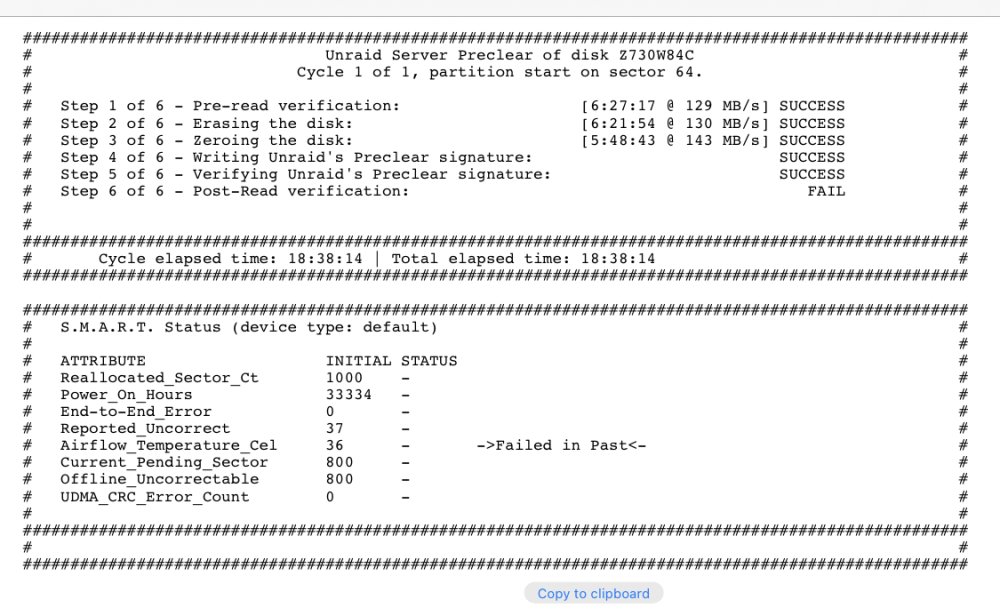
and here are the errors from the log:preclear_disk_Z730W84C_25180.txt
looks like it’s a goner. After only 3 years.
-
Thanks Kilrah. Wondering if the diagnostic files show anything else that may be going on that I can address prior to doing a rebuild.
-
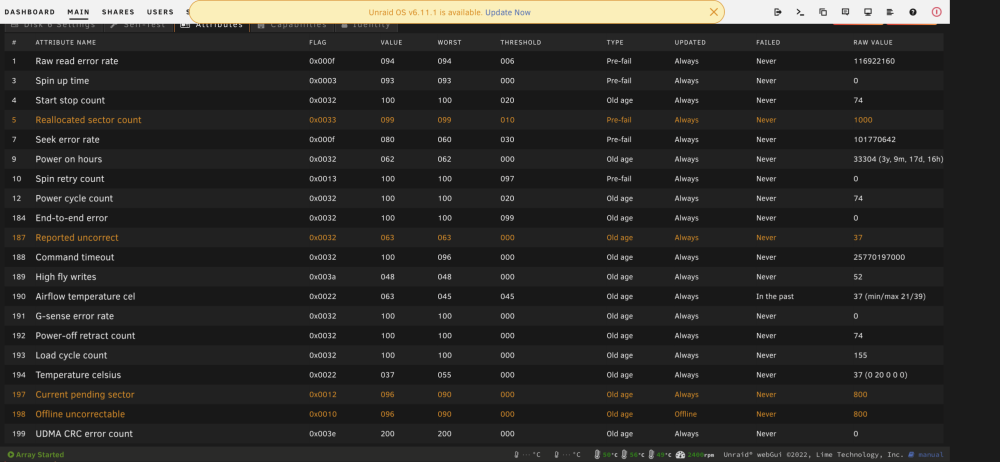
And here are the attributes for the failing drive.
-
I wanted to pull the diagnostics file before updating to 11.1. Here's the one I just pulled after updating. tower-diagnostics-20221007-0725.zip
-
Thanks Truro!
I had no idea you responded until now. I used to get emails for responses and even marked this as follow. Attached is my diagnostics file. I greatly appreciate the help. tower-diagnostics-20221007-0648.zip
-
Hi there,
Apologies for my ignorance.
Is it safe to assume that the attached smart report for a disabled drive is a dead drive that should be replaced?
Also, what part of it should I be looking at to tell that it is a bad drive?
Lastly, I probably bought this drive along with quite a few other of the exact brand and size (Seagate Barracuda 3TB) over the course of maybe 1 year around 3 or 4 years ago and this is the 2nd that I've had issues with. Am I ignorant to assume that they should last longer? I switched to buying 8TB WD Elements/MyBook for the last bunch of drives since they started coming down in price a few years ago. I also believe that they are higher quality WD White drives than the desktop based Barracudas.
Anyways, Thanks in advance for any help with the above questions!
-
On 4/3/2021 at 6:37 AM, cap089 said:
Hi, it seems that in the meanwhile the product ID again changed (?) Because I made these adjustment and he cannot find this ID or rather according the logs its freezes at:
2021-04-03 12:19:08,755 Selected macOS Product: 071-05432How can I find the new ID to download Big Sur?
Edit: Okay do not know which I have done different but after I tried it again it actually fetched the correct BaseSystem.img and now I can install Big Sur.
macOS Big Sur 11.2.3 is 071-14766. Bear in mind, it does take awhile to download though. check the logs in:
mnt/user/appdata/macinabox/macinabox/macinabox_BigSur.log -
Hi. I am not sure what is happening here.
I upgraded through the gui and rebooted. Monitor shows kernel panic. I can boot in safe mode but I'm not sure what's going on here.
Diagnostics attached.
Thanks so much for your help in advance!
-
1 hour ago, RevelRob said:
This is great!
Is it possible to create a client who has remote tunnel access to the internet but no LAN access?
ie. Same public IP?
So I kind of figured it out. Under "Local tunnel firewall" I entered my lan subnet and "Deny".
The only problem is that my UnRAID server is in that subnet and I still have access to it. Even if I put the UnRAID IP in there, it still allows it through. Obviously because that's the tunnel address. I assume there's a way to do this that I'm just not seeing.
Any help would be greatly appreciated.
(I'm trying to provide my family with a remote PiHole but don't want them to have access to my UnRAID IP).
Thanks!
-
This is great!
Is it possible to create a client who has remote tunnel access to the internet but no LAN access?
ie. Same public IP?
-
On 4/8/2020 at 5:41 PM, wesman said:
Changed the time on my bios, got me past that error to:
cp: cannot stat ‘/boot/custom/docker-shell’ no such file or directory
still stuck
Ever figure this out? I'm in the same situation right now.
-
Yup, flash disk is definitely corrupt. Took it out and put it in a separate machine and it gives me errors when trying to copy over certain files.
Also checked some of the xml files that the ui complained was corrupted against an older backup and it looks like they are:
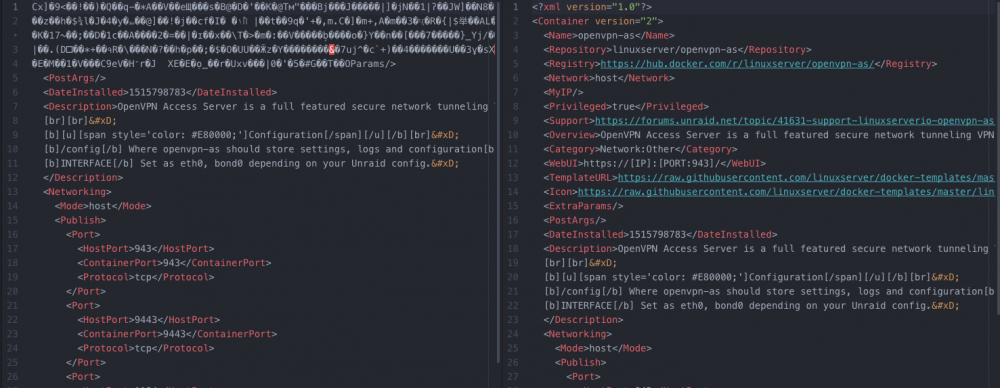
I went ahead and made an order for a new flash drive but in the meantime, I plan to format the corrupted one I'm using and try it again until I receive the new one (to keep uptime and to avoid the "changing flash drives too often" UnRAID rule).
Would there be any issue with using a backup from June 28?
Unfortunately, I only backed up the "config" directory.
If no issue with an old backup of only config, am I correct in saying that I only need to re-make the usb, replace the new config directory with my old one, execute the proper "make_bootable" file (mac), then insert and boot?
Thanks again.
-
Yes, I noticed that too. Something about IPMI. May just disable the sensors.
Thanks again!
-
1 minute ago, johnnie.black said:
It appears you're already using an USB 2.0 port, can still try a different one, if the same happens it's likely the flash drive.
Yes, it's the port on the motherboard. I'll try to put it on an external port and see if that helps.
Besides that, is there anything else that may be causing issues that you may have noticed in my diagnostics?
Thanks!
-
Hi,
I am having an issue with my instance of UnRAID.
I'm running 6.7.0.
Firstly, I haven't really had time recently to play with it (UnRAID, not my peter
") ) so I've been sitting on 6.7.0. I hope to update soon when nobody is using the server.
) so I've been sitting on 6.7.0. I hope to update soon when nobody is using the server.
The UI has gone a bit crazy and is showing me this, which is different than the usual dark mode:
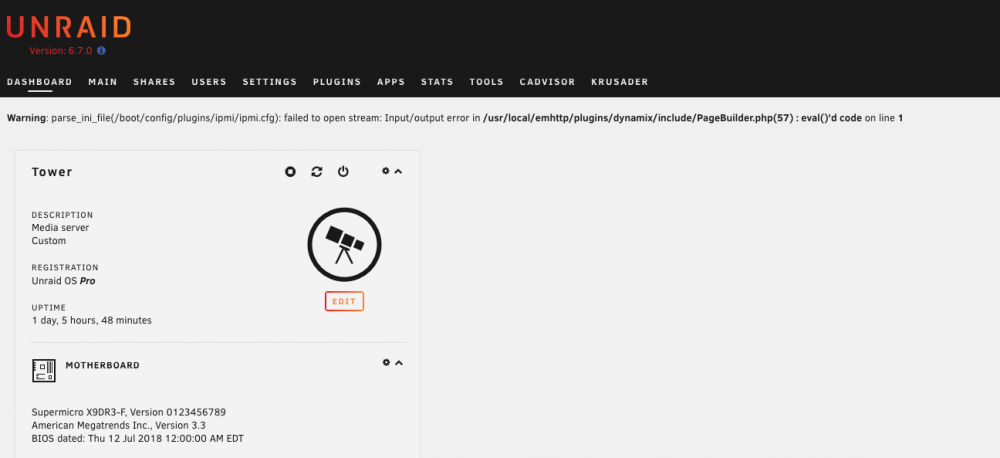
I assume it has to do with this:

Which is also leading to this?:


Also, it says that VM and Docker is down but my containers and VMs are working fine (as far as I can tell).
Just wondering if my fix is to buy a new USB stick or is there something else in the diagnostics file that says otherwise?
tower-diagnostics-20190725-1402.zip
If USB is it, I hear this one is great: https://www.amazon.ca/dp/B006W8U2WU/ref=cm_sw_em_r_mt_dp_U_8UBoDbETEF34F
Further info:
- My SATA controller is a Marvell 88SE9215 which I hear is not the worst offender of Marvells.
- I have been seeing crc error counts every once in awhile. Since I can't read diagnostics files well, I was wondering if it looks like that problems have been resolved (I think my SATA cable was just loose the last time I saw it. Around the end of June.)
Thanks so much for the support here everyone. Probably the best community for getting incredible and friendly help when you're tech savvy enough to want to play around with this cool software/hardware but not savvy enough to understand the inner workings. It is truly appreciated.
-
5 minutes ago, itimpi said:
That error message suggests that the BIOS has lost its setting for which is the bootable drive? I assume that you subsequently managed to boot OK to be able to get diagnostics. Did you have to do anything specific to achieve that?
I put the USB in my workstation and downloaded the diagnostics file.
You may be right though as I invoked the boot menu and unraid booted up fine.
Weird because in the bios, the first option is the USB.
1 minute ago, johnnie.black said:Unrelated to the boot problem (or maybe related since some bios change boot order when a device is added or removed) but one of your cache SSD devices dropped offline, causing the docker image to corrupt:
Jun 20 14:56:13 Tower kernel: ata8: reset failed, giving up Jun 20 14:56:13 Tower kernel: ata8.00: disabledCheck cable but it it's on a Marvell controller which are known to drop devices, also see here for better pool monitoring.
It is on a Marvell controller but supposedly, it's chipset is not one with the issues? It's 88SE9215. https://www.amazon.ca/gp/product/B00AZ9T3OU/ref=ppx_yo_dt_b_search_asin_title?ie=UTF8&psc=1
On boot, I see a "crc error count is 8" on the SSD connected to the Marvell controller so I will try to re connect the cables just in case.
-
Hi,
I was away on vacation and noticed my server went down.
Now, I get "this is not a bootable disk please insert a bootable floppy and try again" when I try to boot.
I had an issue at the end of May where this also happened after an unclean shutdown so I have a feeling that my USB drive might be the issue.
It's a 16GB USB 3.0 drive (I know, 2.0 is best).
The diagnostics are attached:
tower-diagnostics-20190620-1956.zip
Thanks!
-
21 hours ago, mfwade said:
I used the following however, I am unable to provide the Time Machine screenshot as I did not configure my VPN to allow discovery.
-MW

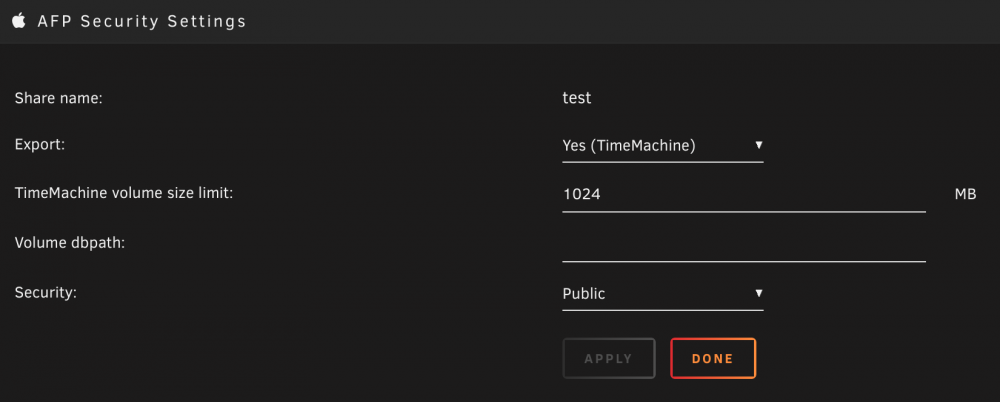
1024 MB is only 1 GB.
5 hours ago, mfwade said:So, not sure if we should continue on with this thread or open a new one. Moderators, please advise.
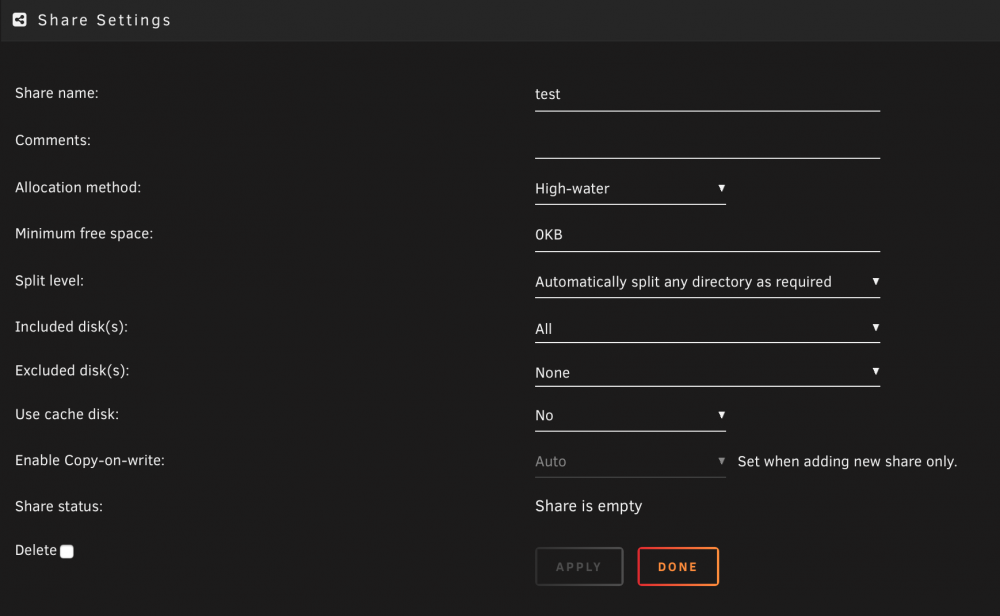
I tried once again this morning to get the Time Machine (via SMB) to work with 2 Mac computers. 1 running Mojave and the other running High Sierra, both with the same results. I create a share called 'Time Machine' or 'test-1', etc,. Assigned the following SMB attributes (export: yes/time machine, volume size: 60000 for 6TB, and security: private). When looking in either Mac's Time Machine properties, and attempting to add a new disk, the new share is not visible. However, if I mount the SMB share via Finder, Go, Connect to Server, then I am able to see and use the disk in Time Machine.
I have also tested using AFP. When creating the same type share via AFP, the following settings were used (export: yes/time machine, volume size: 60000 for 6TB, volume dbpath: empty, and security: private). When I go to browse for the share in Time Machine, I am able to see it. The issue comes when I try to mount it in the Time Machine settings. It takes in upwards of almost 20 or so seconds to 'connect' to the drive. When it does finally connect, I am prompted for my credentials, and then it errors out. Unfortunately, I did not capture any screen shots of the errors this morning. I will take care of that when ai get home this evening and post them.
So in summary, If I am not following the proper procedures when using an SMB share with Time Machine, please let me know. I am under the assumption that it will simply appear much like an AFP share. If others have been able to get this to work, please share your settings for not only creating the share but also how it is exported.
I am attaching my diagnostics file. Maybe it will be of use to someone in the hopes of figuring this out.
Thank you to everyone in advance for reading and providing commentary. The support you provide is sincerely appreciated.
-MW
unraid-1-diagnostics-20190514-1050.zip 223.93 kB · 1 download
Not sure if it's a typo but 60000 MB is only about 58.6 GB.
-
3 hours ago, limetech said:
For those suffering Marvell-Dropped-Drives-Syndrome, please try this test:
I'm still on 6.6.5 and was looking to update to 6.7.0. Figure I'd read through this thread first.
Although I have a SAS2008 card for my HDDs, I am using a Marvell 88SE9215 card for my SSD Cache Pool... that I just bought too due to lack of SATAIII ports on my motherboard
 (and some issues I read about re: TRIM on SSDs on a SAS controller).
(and some issues I read about re: TRIM on SSDs on a SAS controller).
This is what I see under Tools > System Devices. Can't tell if it's one of the problematic cards or not:
`IOMMU group 18:[1b4b:9215] 06:00.0 SATA controller: Marvell Technology Group Ltd. Device 9215 (rev 11)`
Would anyone know if this may cause me issues? Does anyone who has this card upgrade with/out problems?
Would prefer to get feedback before trying to upgrade.
Also, if there are problems with this card (or if I *should* eventually replace it), what card would be recommended for SSDs?
Thanks for the awesome work Limetech team! -
On 12/1/2018 at 4:27 PM, John_M said:
Using a network share as a Time Machine destination is problematic, even using Apple's own Time Capsule. An external hard disk plugged into the USB port of your Mac is much faster and much more reliable. The weakness is in the use of the sparse bundle disk image. A sparse bundle consists of a containing folder, a few database files, a plist that stores the current state of the image and nested subfolders containing many many thousands of small (8 MiB) 'band' files. An image file has to be used in order to recreate the necessary HPFS+J file system that Time Machine requires to support hard linked folders on network storage, while using many small files to create the image rather than one huge monolithic file allows updates to be made at a usable speed. But sparse bundles have shown themselves to be fragile and often Time Machine will detect a problem, spend a long time checking the image for consistency and then give up, prompting the user that it needs to start over from scratch, losing all the previous backups. Because there's a disk image on a file server a double mount is involved. First the Mac has to mount the network share, then it has to mount the sparse bundle disk image. Once that is done it treats the disk image exactly as it would a locally connected hard disk that you have dedicated to Time Machine use. Sparse bundles grow by writing more band files so you have the opportunity to specify the maximum size of the image. If you don't it will eventually grow until it fills up all the space available on the share.
If you still want to do it, here's what I'd do.
First create a user on your Unraid server that's only going to be used for Time Machine. Let's call that user 'tm'. Set a password. Now enable user shares, disable disk shares and create a new user share. Let's call it 'TMBackups'. Include just one disk and set Use cache disk to No. You can set Minimum Free Space quite low (e.g. 10 MB) since the largest files in the share will be the 8 MiB band files. Allocation method and split level are irrelevant if your user share is restricted to a single disk.
Under SMB Security Settings for the share, turn Export off. Under NFS Security Settings, confirm that Export is off.
Under AFP Security Settings, turn Export on. If you want to restrict the size occupied by your Time Machine backups do so here. Even if you want it to be able to use all the disk it's worth setting a limit so that it doesn't become totally full. I fill up my Unraid disks but I like to leave about 10 GB free. Set Security to Private and give your new user 'tm' exclusive read/write access. Consider moving the Volume dbpath away from its default location (the root of the share) to somewhere faster, where it's less likely to get damaged. The Volume database is the .AppleDB folder that can be found in the root of an AFP share. It too is fragile and benefits from fast storage. I moved mine onto my cache pool by entering the path /mnt/user/system/AppleDB (i.e. a subfolder of the pre-existing Unraid 'system' share, which by default is of type cache:prefer). This will improve both the speed and reliability of AFP shares, so do it to any other user shares you have that are exported via AFP. The system will automatically create a sub-folder named for the share, so in this example the .AppleDB folder gets moved from the root of the share and placed in a folder called /mnt/user/system/AppleDB/TMBackups.
Now that the user share is set up, go to your Mac. Open a Finder window and in the left-hand pane under Shared, find Tower-AFP and click it. In the right hand pane make sure you connect as user 'tm', not as your regular macOS user and not as Guest. You'll need to enter the password associated with tm's account on your server. Check the box to store the credentials on your keyring. The TMBackups share should be displayed in the Finder window. Mount it. Now open Time Machine Preferences and click "Add or remove backup disk". Under Available Disks you will see "TMBackups on Tower-AFP.local". Choose it. If Time Machine ever asks you to provide credentials then enter those for the 'tm' user, not your regular macOS user. Enter a name for the disk image (say, "Unraid TM Backups") and do not choose the encryption option, and let Time Machine create the sparse bundle image, mount it and write out the initial full backup, which will take a long time. Once it has completed, Time Machine should unmount the Unraid TM Backups image but it will probably leave the TMBackups share mounted, since you mounted it manually in the first place. You can unmount it manually or leave it until you reboot your Mac. From then on, each time Time Machine runs it will automatically mount the user share (keeping it hidden), automatically mount the sparse bundle image, perform the backup and tidy up after itself, then it will unmount the image then unmount the share, all without your interaction.
The use of a dedicated 'tm' account offers a degree of security but if you want your backups to be encrypted then use unRAID's encrypted whole disk file system, not the encryption option offered by Time Machine.
This is great! Thanks John for the easy write up.
My Time Machine External HD just crashed at 12:01 on April 1. I guess it was trying to tell me it wasn't an April Fools joke:
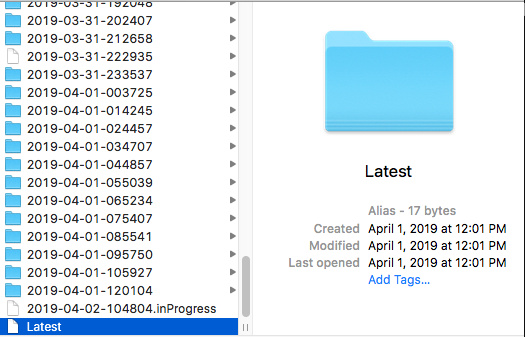
Anyways, I set it up the way you wrote it up with a few changes and have my backup running right now. Fingers crossed.
The only thing I did differently was leave Minimum Free Space to 0 and am using all disks for now until I buy some dedicated TM drives. Not enough space unfortunately.
Also, although I didn't do it, wouldn't setting Use Cache Disk to Yes be beneficial once the initial backup is done? For speed? Maybe even for the initial backup with a bunch of manual Mover invoking? Not sure if I'm over thinking that.
On a separate note, I was looking at Carbon Copy Cloner for some time and just bit the bullet and bought it. I know that it's best used when cloning to an external HD/SSD; however, I was hoping to make CCC backups of only my Hackintosh 250 GB SSD to my UnRAID server; and in the case of a failure, be able to just buy another SSD, put the CCC backup on it and replace the old one.
I've been reading about sparse bundles, sparseimages, and other CCC & UnRAID related stuff here and on the CCC help pages, but I'm confused.
Would it be best to make an SMB User Share with Enhanced OSX Operability or should I make another AFP share and export without the Time Machine option?
And once that's done, what's the best way to set CCC to perform the backups? Sparse Bundle? Sparse Image?
Lastly, my Hackintosh is currently running El Capitan but I am planning to do an update as soon as I can get a good CCC cloned drive and the Nvidia drivers are updated for Mojave (or I buy a compatible gpu). I remember reading that pre Sierra machines may not work well with SMB in this use case? Not sure.
Thanks for the help!
On 12/1/2018 at 4:27 PM, John_M said:An external hard disk plugged into the USB port of your Mac is much faster and much more reliable.
P.S. OSX offers an option to back up to multiple locations with disk rotation. When I went to select the UnRAID share, it asked if I wanted to replace the disk or backup to both. Could be a good option.











Server running very slow and becomes unresponsive soon after pre-clearing start
in General Support
Posted
Thanks for the quick reply!
Ah, that's unfortunate. I'm going to try to reseat them all to see if that helps. I also have more RAM than I need for this machine so I could remove any that have failed.
Also, the CPU utilization is screaming at 100% even though VMs and Docker is disabled for now.