




RevelRob
Members
-
Joined
-
Last visited
Everything posted by RevelRob
-
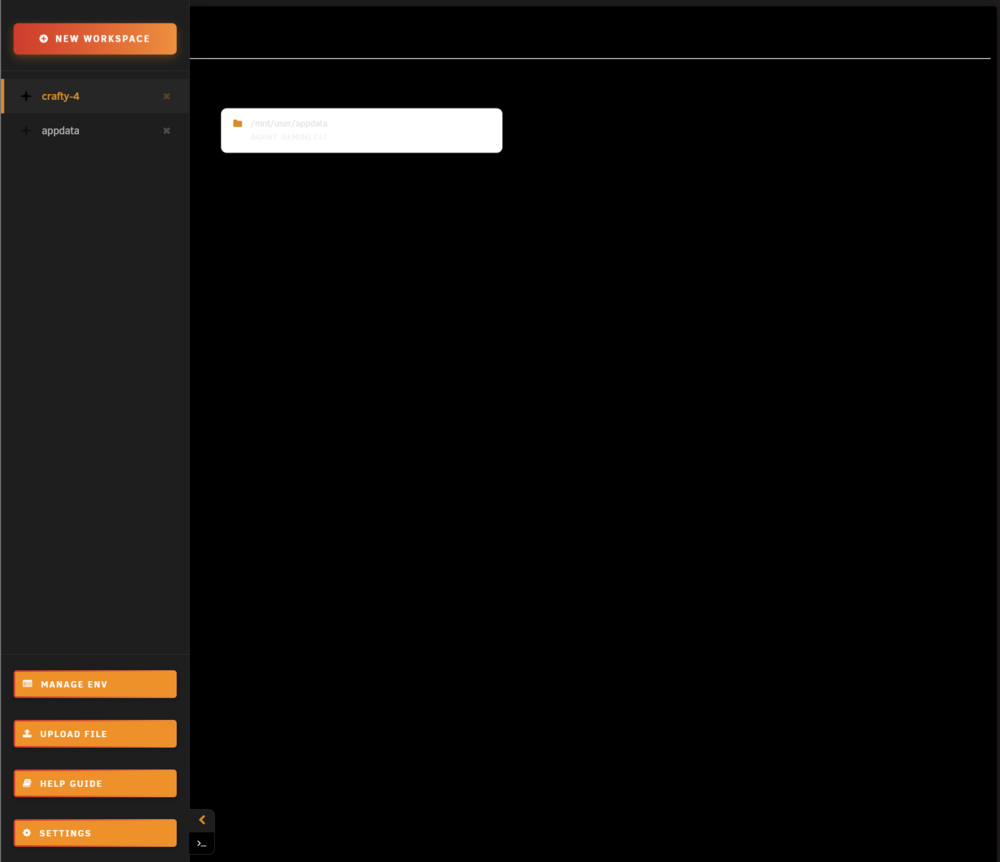
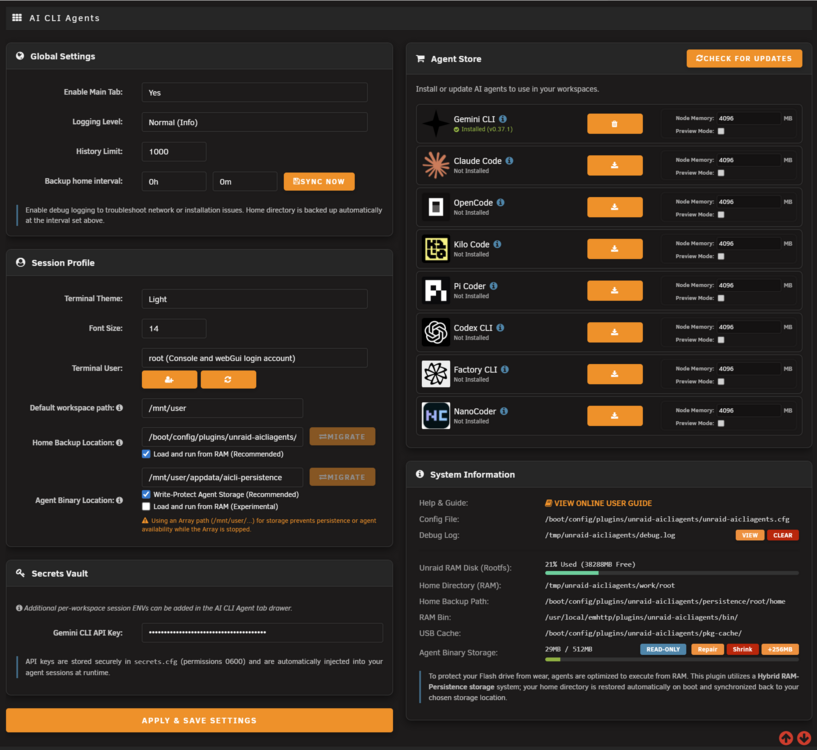
Hi, I'm having trouble with "Failed to mount Home storage for root" errors: [2026-04-11 12:30:58] [INFO] MAINTENANCE: Unlocking Agent storage (RO -> RW)[2026-04-11 12:30:58] [WARN] Mnt Attempt 1 failed: mount: /usr/local/emhttp/plugins/unraid-aicliagents/agents: cannot remount /dev/loop4 read-write, is write-protected. dmesg(1) may have more information after failed mount system call.[2026-04-11 12:30:59] [WARN] Mnt Attempt 2 failed: mount: /usr/local/emhttp/plugins/unraid-aicliagents/agents: cannot remount /dev/loop4 read-write, is write-protected. dmesg(1) may have more information after failed mount system call.[2026-04-11 12:31:00] [WARN] Mnt Attempt 3 failed: mount: /usr/local/emhttp/plugins/unraid-aicliagents/agents: cannot remount /dev/loop4 read-write, is write-protected. dmesg(1) may have more information after failed mount system call.[2026-04-11 12:31:00] [WARN] STALL: Remount RW failed. Triggering robust repair sequence...[2026-04-11 12:31:00] [WARN] Btrfs Rescue: Processing /mnt/user/appdata/aicli-persistence/aicli-agents.img mounted at /usr/local/emhttp/plugins/unraid-aicliagents/agents[2026-04-11 12:31:01] [INFO] Btrfs Rescue: Success for /mnt/user/appdata/aicli-persistence/aicli-agents.img [2026-04-11 12:31:44] [INFO] Mounting Btrfs Home (RAM) for root...[2026-04-11 12:31:44] [ERROR] ERROR: Failed to mount Home storage for root.[2026-04-11 12:31:57] [INFO] startAICliTerminal called: ID=sz9cv0, Agent=gemini-cli, Path=/mnt/user/appdata[2026-04-11 12:31:57] [INFO] Mounting Btrfs Home (RAM) for root...[2026-04-11 12:31:57] [ERROR] ERROR: Failed to mount Home storage for root.[2026-04-11 12:32:01] [INFO] startAICliTerminal called: ID=temp-terminal, Agent=terminal, Path=/mnt/user/appdata[2026-04-11 12:32:01] [INFO] Mounting Btrfs Home (RAM) for root...[2026-04-11 12:32:01] [ERROR] ERROR: Failed to mount Home storage for root.[2026-04-11 12:32:08] [INFO] startAICliTerminal called: ID=temp-terminal, Agent=terminal, Path=/mnt/user/appdata[2026-04-11 12:32:08] [INFO] Mounting Btrfs Home (RAM) for root...[2026-04-11 12:32:08] [ERROR] ERROR: Failed to mount Home storage for root.[2026-04-11 12:35:21] [INFO] startAICliTerminal called: ID=sz9cv0, Agent=gemini-cli, Path=/mnt/user/appdata[2026-04-11 12:35:21] [INFO] Mounting Btrfs Home (RAM) for root...[2026-04-11 12:35:21] [ERROR] ERROR: Failed to mount Home storage for root.[2026-04-11 12:35:32] [INFO] startAICliTerminal called: ID=sfrv5k, Agent=gemini-cli, Path=/mnt/user/appdata/crafty-4[2026-04-11 12:35:32] [INFO] Mounting Btrfs Home (RAM) for root...[2026-04-11 12:35:32] [ERROR] ERROR: Failed to mount Home storage for root.[2026-04-11 12:36:26] [INFO] startAICliTerminal called: ID=temp-terminal, Agent=terminal, Path=/mnt/user/appdata/crafty-4[2026-04-11 12:36:26] [INFO] Mounting Btrfs Home (RAM) for root...[2026-04-11 12:36:26] [ERROR] ERROR: Failed to mount Home storage for root.[2026-04-11 12:43:04] [INFO] startAICliTerminal called: ID=sfrv5k, Agent=gemini-cli, Path=/mnt/user/appdata/crafty-4[2026-04-11 12:43:04] [INFO] Mounting Btrfs Home (RAM) for root...[2026-04-11 12:43:04] [ERROR] ERROR: Failed to mount Home storage for root. The plugin page looks like this: I'm using Gemini if that matters. Here's my settings page: Any help would be amazing. Thanks!
-
Hi, Last week (03-30) I had an error where Docker failed to start. I have attached the diagnostics from that date. I tried to fix it myself and decided I would delete the docker.img file and add them all back via the Community Apps Previous Apps feature which was a huge pain since I had a ton of containers installed. Today, I decided to reboot he server and when it came up, it shows "No Docker containers installed". So I first increased the image size and when that didn't work, I pulled the diagnostics and pasted it here. Can anyone tell what is happening? I'm hoping to not have to install everything again and even if I do have to, I am worried there is a bigger issue that is causingthis to happen. Thanks! tower-diagnostics-20260330-1203.zip tower-diagnostics-20260402-1644.zip
-
So by chance, I rebooted, and everything came up. Weird. Here is the new diagnostics in case there's anything wrong that is making this happen. Thanks again! tower-diagnostics-20250525-1114.zip
-
Hi All, I updated my machine from 6.12.1 to 7.1.2 yesterday (was holding off due to issues with nfs shares that appear to be fixed now). Everything was working until today when I noticed the gui would hang a lot. I performed a reboot from the gui and it came back up; however, it has been up for 35 minutes and the Arrays is still trying to start. My diagnostics zip is attached and any help would be greatly appreciated. Thanks! tower-diagnostics-20250525-1048.zip
-
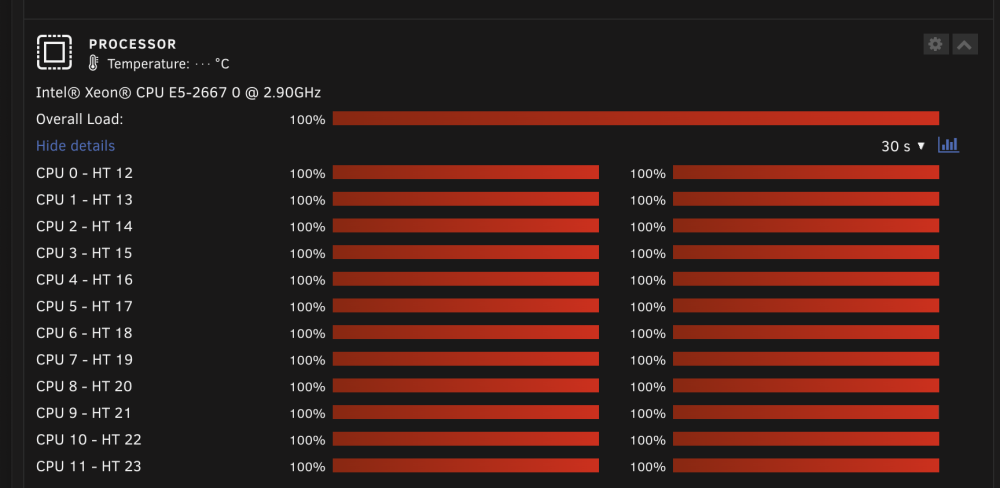
Thanks for the quick reply! Ah, that's unfortunate. I'm going to try to reseat them all to see if that helps. I also have more RAM than I need for this machine so I could remove any that have failed. Also, the CPU utilization is screaming at 100% even though VMs and Docker is disabled for now.
-
Hi, I posted this Saturday and thought all was good, but I've been experiencing additional issues that are odd: I am in the process of preclearing a new replacement disk for the one that is failing. I've turned VMs and Docker off so that there are no additional resources being used elsewhere and to not stress out the parity drive that would e emulating the disabled disk. The problem is, after a period of time, the server becomes unresponsive with no gui loading nor am I ale to SSH in. Even sending an orderly shutdown via IPMI fails. So I have to power cycle via IPMI. It also runs extremely slowly now even after a reboot. I was on an older version (6.12.6) and updated to 6.12.8 to see if that was the issue. I ran a smart test on the new drive to see if it was the issue but it came back no errors. Can anyone tell me idf they see something awry from the diagnostics file I pulled just now after a restart and pre-clear start? It also took the diagnostics almost 20 minutes to generate. Thanks! tower-diagnostics-20240311-1035.zip
-
Haha. Nice. Too bad I have half a dozen of these to do this with now. Thanks!
-
Hi all. I have a disabled disk and am wondering if it looks like it is going bad or if something else is happening here. I already purchased a new drive that is pre-clearing in case it is bad but want to know for sure to avoid throwing it out. Unraid version 6.12.6 Thanks! tower-diagnostics-20240309-1403.zip
-
Thanks, it had already been replaced but I figured I’d see what the preclear plug-in said about it. She gone.
-
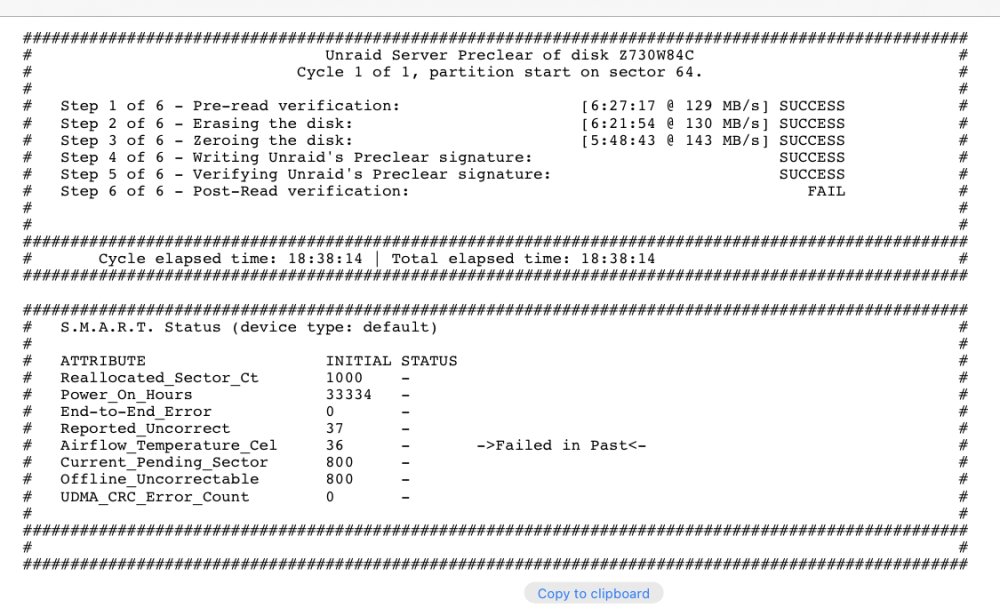
Only the cache pool; however, it is only CRC Error Count issues which I have read could be due to bad sata cables. I ordered replacement ones in which will hopefully help. I am rebuilding the dead drive with a replacement now. I was wrong about the dead drive being a Seagate barracuda by the way. It’s a Seagate ironwolf which should be better quality than a barracuda. Also, I ran a pre clear on the dead drive for fun and it just finished. Here’s the finished status preview: #################################################################################################### # Unraid Server Preclear of disk Z730W84C # # Cycle 1 of 1, partition start on sector 64. # # # # Step 1 of 6 - Pre-read verification: [6:27:17 @ 129 MB/s] SUCCESS # # Step 2 of 6 - Erasing the disk: [6:21:54 @ 130 MB/s] SUCCESS # # Step 3 of 6 - Zeroing the disk: [5:48:43 @ 143 MB/s] SUCCESS # # Step 4 of 6 - Writing Unraid's Preclear signature: SUCCESS # # Step 5 of 6 - Verifying Unraid's Preclear signature: SUCCESS # # Step 6 of 6 - Post-Read verification: FAIL # # # # # #################################################################################################### # Cycle elapsed time: 18:38:14 | Total elapsed time: 18:38:14 # #################################################################################################### #################################################################################################### # S.M.A.R.T. Status (device type: default) # # # # ATTRIBUTE INITIAL STATUS # # Reallocated_Sector_Ct 1000 - # # Power_On_Hours 33334 - # # End-to-End_Error 0 - # # Reported_Uncorrect 37 - # # Airflow_Temperature_Cel 36 - ->Failed in Past<- # # Current_Pending_Sector 800 - # # Offline_Uncorrectable 800 - # # UDMA_CRC_Error_Count 0 - # # # #################################################################################################### # # #################################################################################################### In case that is hard to read, here’s a screenshot: and here are the errors from the log: preclear_disk_Z730W84C_25180.txt looks like it’s a goner. After only 3 years.
-
Thanks Kilrah. Wondering if the diagnostic files show anything else that may be going on that I can address prior to doing a rebuild.
-
And here are the attributes for the failing drive.
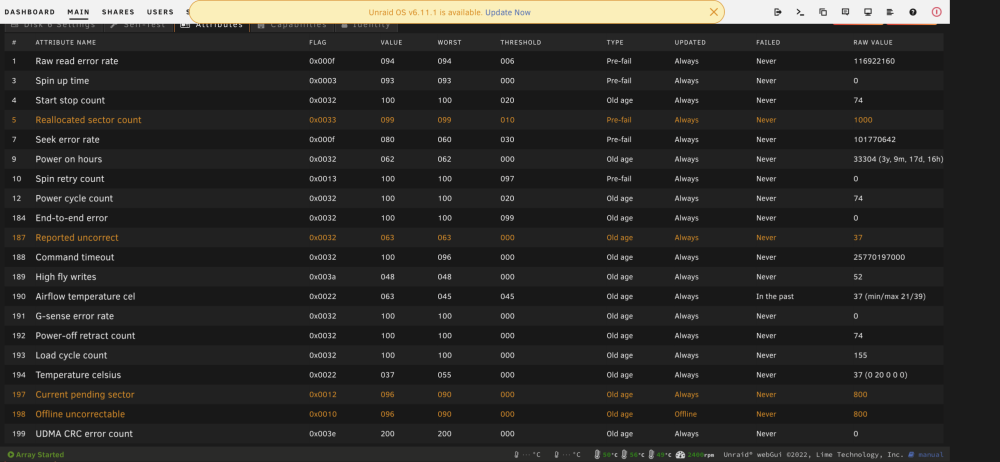
-
I wanted to pull the diagnostics file before updating to 11.1. Here's the one I just pulled after updating. tower-diagnostics-20221007-0725.zip
-
Thanks Truro! I had no idea you responded until now. I used to get emails for responses and even marked this as follow. Attached is my diagnostics file. I greatly appreciate the help. tower-diagnostics-20221007-0648.zip
-
Hi there, Apologies for my ignorance. Is it safe to assume that the attached smart report for a disabled drive is a dead drive that should be replaced? Also, what part of it should I be looking at to tell that it is a bad drive? Lastly, I probably bought this drive along with quite a few other of the exact brand and size (Seagate Barracuda 3TB) over the course of maybe 1 year around 3 or 4 years ago and this is the 2nd that I've had issues with. Am I ignorant to assume that they should last longer? I switched to buying 8TB WD Elements/MyBook for the last bunch of drives since they started coming down in price a few years ago. I also believe that they are higher quality WD White drives than the desktop based Barracudas. Anyways, Thanks in advance for any help with the above questions! tower-smart-20221004-0900.zip
-
macOS Big Sur 11.2.3 is 071-14766. Bear in mind, it does take awhile to download though. check the logs in: mnt/user/appdata/macinabox/macinabox/macinabox_BigSur.log
-
So I kind of figured it out. Under "Local tunnel firewall" I entered my lan subnet and "Deny". The only problem is that my UnRAID server is in that subnet and I still have access to it. Even if I put the UnRAID IP in there, it still allows it through. Obviously because that's the tunnel address. I assume there's a way to do this that I'm just not seeing. Any help would be greatly appreciated. (I'm trying to provide my family with a remote PiHole but don't want them to have access to my UnRAID IP). Thanks!
-
This is great! Is it possible to create a client who has remote tunnel access to the internet but no LAN access? ie. Same public IP?
-
I'm still on 6.6.5 and was looking to update to 6.7.0. Figure I'd read through this thread first. Although I have a SAS2008 card for my HDDs, I am using a Marvell 88SE9215 card for my SSD Cache Pool... that I just bought too due to lack of SATAIII ports on my motherboard (and some issues I read about re: TRIM on SSDs on a SAS controller). This is what I see under Tools > System Devices. Can't tell if it's one of the problematic cards or not: `IOMMU group 18:[1b4b:9215] 06:00.0 SATA controller: Marvell Technology Group Ltd. Device 9215 (rev 11)` Would anyone know if this may cause me issues? Does anyone who has this card upgrade with/out problems? Would prefer to get feedback before trying to upgrade. Also, if there are problems with this card (or if I *should* eventually replace it), what card would be recommended for SSDs? Thanks for the awesome work Limetech team!
-
Ok thank you. I'll have to peruse through RDP Calibre to see what's up. I'm still curious as to how Heimdall can grow to now 9gb. I went through every setting and don't see anywhere where anything could be saved besides what's in /config. My log files are >100mb as well. Edit: I mean <100mb
-
Thank you for the quick reply. So is going to the respective folders through samba and checking that the files there match what are showing via the container console (navigate to those directories and `ls`) enough? If so, they all show the same file structure. ie. /mnt/user/eBooks/calibre library in samba shows the same files as opening container console, `cd /library`, `ls`. The RDP-Calibre one may be a bit more difficult to figure out; however, with only 1 path mapped in Heimdall (and the contents of /mnt/user/appdata/heimdall via samba matching /config in console... and showing up to date logs), I feel like I'm missing something. Apologies if I'm just not "getting it".
-
Anyone know why I would be getting this: My Volume Mapping seems to be correct. It reflects what's in the respective folder: Even though it's semi off topic, that RDP-Calibre is the only other container with an abnormal size. Looks like the mappings there are correct too:
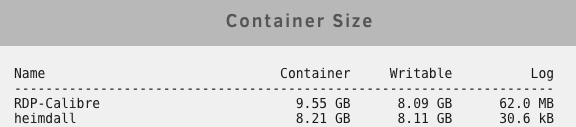

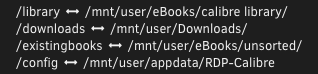
-
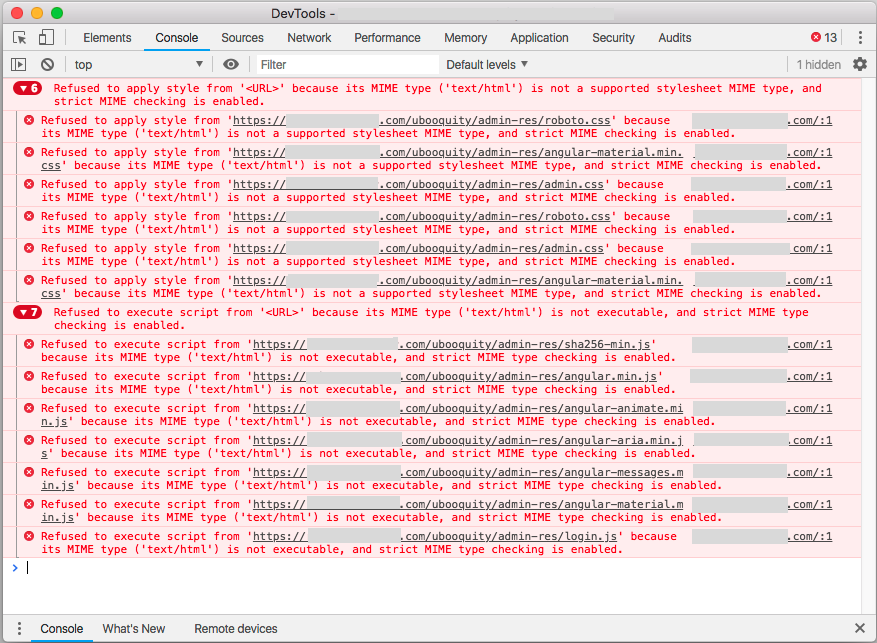
Hi, I'm having trouble with reverse proxy-ing the admin page. Is this possible? The following works to access the library: location /ubooquity { proxy_pass http://IPADDRESS:2202/ubooquity; How would I access the admin page? I know that the port is 2203; however, it's the same base url ("reverse proxy prefix"), so I'm not sure what the location block and/or proxy pass should be. I've tried the following variations with no luck. Location: location /ubooquity/admin { location /ubooquity/admin/ { location /ubooquity-admin { location /ubooquity-admin/ { location /admin { location /admin/ { Proxy Pass: proxy_pass http://IPADDRESS:2203 proxy_pass http://IPADDRESS:2203/ proxy_pass http://IPADDRESS:2203/ubooquity; proxy_pass http://IPADDRESS:2203/ubooquity/; proxy_pass http://IPADDRESS:2203/ubooquity/admin; proxy_pass http://IPADDRESS:2203/ubooquity/admin/; Some of them give me this: instead of this: And in the Chrome Console, I get the following: Thanks for any help!
-
Any way to make this an option? pretty please? So I'm having a situation: Can't open /mnt/cache/appdata/myVPNserver/easy-rsa/easyrsa3/pki/index.txt.attr for reading, No such file or directory 23225341101888:error:02001002:system library:fopen:No such file or directory:crypto/bio/bss_file.c:74:fopen('/mnt/cache/appdata/myVPNserver/easy-rsa/easyrsa3/pki/index.txt.attr','r') 23225341101888:error:2006D080:BIO routines:BIO_new_file:no such file:crypto/bio/bss_file.c:81: Check that the request matches the signature Signature ok The Subject's Distinguished Name is as follows commonName :ASN.1 12:'server' Certificate is to be certified until Oct 22 03:00:00 2021 GMT (1080 days) ... stty: 'standard input': Inappropriate ioctl for device I'm using easy-rsa v3.0.6 Funny thing is I can connect to the server with my iPhone and changing the DNS works, but I can't ping any of my LAN IPs when on a data connection. If I connect to a separate remote Wifi network, everything works as planned.
-
Any way to make this an option? pretty please?










