




Execut1ve
Members
-
Joined
-
Last visited
-
Hello folks, I am playing around with the pihole container. My current setup has an onboard network connection, plus I have added another NIC as well. I would like to set it up so pihole uses only the second NIC and has its own IP address, while Unraid and my other containers use only the onboard NIC. Is this possible, and is it a good idea? I am using version 6.12.6 if it matters. Thanks!
-
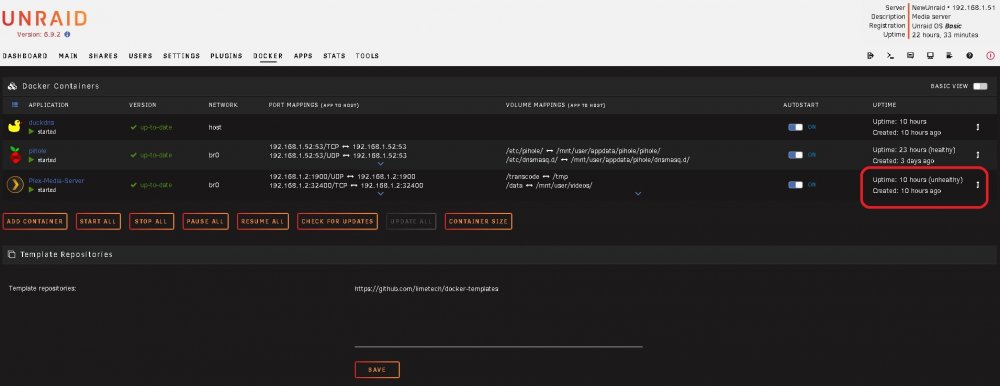
Hello all, recently my Plex server has not been working. I can't access the webui and the container's status in Docker shows "unhealthy." To my knowledge I haven't changed anything in the container's settings or made any recent changes to my server. I have been tinkering with router / DNS stuff, but it seems like that shouldn't be related. Can anyone point me in the right direction? Screenshot and diagnostics attached. Thanks! newunraid-diagnostics-20220522-1911.zip
-
It looks like reseating everything did the trick, VM has been running steady ever since!
-
It seems it was too good to be true... pausing behavior has returned. Based on the syslog, it does seem to be related to an issue with one of the graphics cards: Oct 15 10:12:11 RemoteUnraid kernel: pcieport 0000:00:07.0: AER: Multiple Uncorrected (Fatal) error received: 0000:00:00.0 Oct 15 10:12:11 RemoteUnraid kernel: vfio-pci 0000:06:00.0: AER: PCIe Bus Error: severity=Uncorrected (Fatal), type=Inaccessible, (Unregistered Agent ID) Oct 15 10:12:12 RemoteUnraid kernel: pcieport 0000:00:07.0: AER: Root Port link has been reset Oct 15 10:12:12 RemoteUnraid kernel: pcieport 0000:00:07.0: AER: device recovery successful I'm going to try reseating all the cards and risers and see if that helps any
-
I actually got the VM to work without pausing by adding a USB keyboard and mouse and passing them through to the VM. I have no idea why that would work, but the VM did originally have those items. I had removed them when I physically relocated my server but now the VM is working after re-adding them. I typically access the VM via VNC. I usually don't have any issues with it, except occasionally the disappearing mouse cursor.
-
I just tried extending the vdisk... I was able to add space but the VM still pauses. If I try to force it to resume, I get Execution error internal error: unable to execute QEMU command 'cont': Resetting the Virtual Machine is required
-
Hibernation is turned off, and I believe sleep is as well - however I can't get the VM to run long enough to check before it pauses.
-
My Windows 10 VM has lately started pausing itself for no apparent reason. Diagnostics attached. From some cursory research, it looks like it may be related to drive space, but I have only one drive in my system (aside from the parity drive) and it shows plenty of free space so I'm not sure how to resolve. Any help appreciated! remoteunraid-diagnostics-20211013-1051.zip
-
Is anyone having issues with the latest update of the MobiusNine Folding@Home docker container? After updating, Folding@Home is suddenly not detecting any CUDA or OpenCL and all my slots are showing as disabled.
-
After some informal experimentation, I'm not seeing much difference (if any) in my total PPD between allocating the container 4 cores (with nothing on the HTs) VS allocating 2 cores with their 2 HTs. For reference I'm folding on 4 GPUs: 3 of the Zotac 1060 mining variants and 1 GTX960. They are connected to the mainboard via powered PCIE riser cables. Two of them are in x8 slots and two are in x4 slots. All the PCIE slots are Gen 2. The computer is a PowerEdge R710 server with dual Xeon X5690 processors. I'm averaging 800k-1M total PPD, with each card sitting in the 200k-250k range. I don't notice any substantial difference between the cards on the x4 slots vs the x8 slots. Can anyone else with a hyperthreaded CPU offer any observations?
-
Hm, I wonder if I'd notice a hit to folding performance if I assigned the container 2 cores and 2 hyperthreads instead of 4 cores? Time for some experimentation!
-
I've been using the docker container to fold with 4 GPUs / no CPU. Everything seem to be working well but I've noticed that the container seems to use a CPU core for each GPU slot, and each CPU core it uses is pinned at 100% utilization. Is anyone else getting similar behavior? I realize the GPUs have to be fed data to fold, but it seems like that shouldn't take up 100% of a core. The CPUs are Xeon x5690s, so not exactly new, but not slouches either. Can anyone offer any thoughts? Am I misunderstanding something in how all this works?
