Capt.Insano
Community Developer
-
Joined
-
Last visited
-
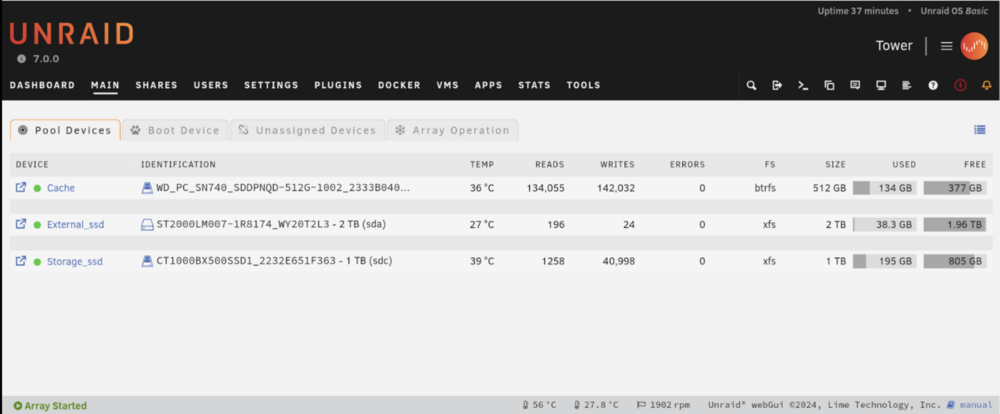
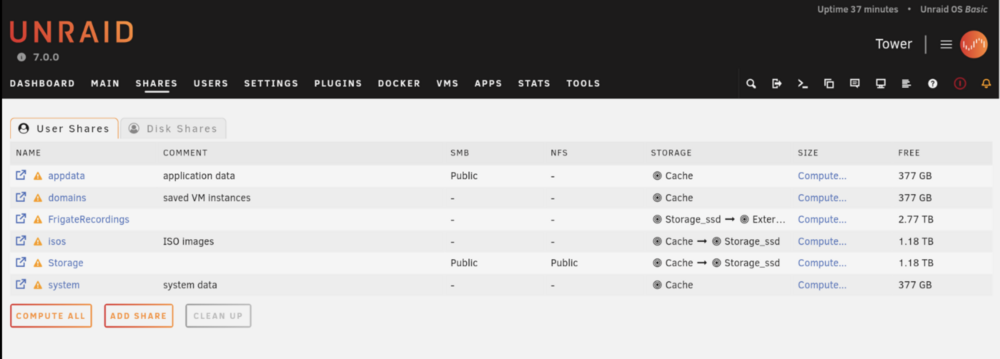
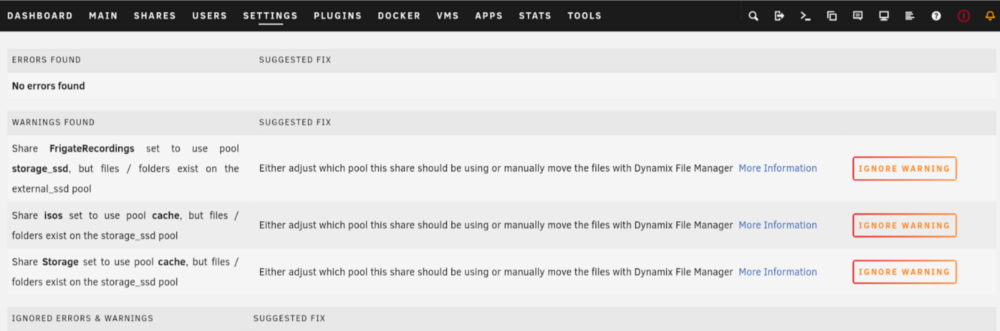
Possible false positive on unRAID 7.0: Share XXXXXXXXXXX set to use pool cache, but files / folders exist on the storage_ssd pool I moved to unRAID 7 this week and I now have an array-free setup on one of my servers. I have 3 pools as below: Cache: internal NVME drive External_ssd: external 2TB drive for archive of Frigate recordings Storage_ssd: internal 1TB SSD Shares set up as below: I get the following warnings in FCP for the shares using more than one pool: I would have thought that this was the desired behavior and not something to be warned about? Files should exist between the primary & secondary storage locations as per the mover settings. shareDisks.txt: appdata shareUseCache="only" # Share exists on cache domains shareUseCache="only" # Share exists on cache F---------------s shareUseCache="yes" # Share exists on storage_ssd, external_ssd isos shareUseCache="yes" # Share exists on storage_ssd S-----e shareUseCache="yes" # Share exists on cache, storage_ssd system shareUseCache="only" # Share exists on cache Full diagnostics attached: Thanks so much for your work for the community @Squid. tower-diagnostics-20250119-1720.zip
-
Thank you so much for this, I had moved to ipvlan as per all the official advice. Confirmed the container is fixed on host settings when changed my Docker settings back to macvlan Is this ipvlan issue new in Unraid 6.12 releases or has it always been an issue? @Dmitry Spikhalskiy Thanks so much for your work on this. Do you think it may be worth noting the issue with ipvlan in the OP or github readme? UPDATE 12 hours later: Just had my first system crash in long long time, I remember why I left macvlan!! I have a few dockers with custom IPs and macvlan causes traces and crashes. I have had to revent to ipvlan again, is there any way of having ipvlan and working zerotier?
-
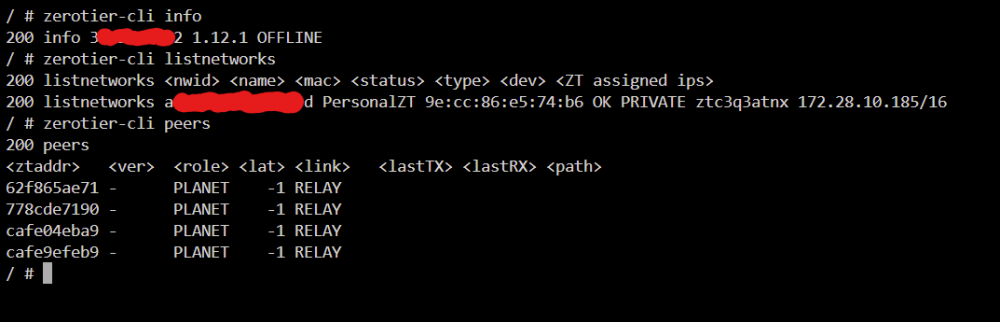
Did you find a solution to this? I came here with the same issue. Zerotier is not working in "host mode", seems to work fine in bridged or Custom:bond0 when trying to debug but that is useless to me as I cannot access unraid itself. Getting the following when trying to debug via the container console: have the recommended settings for unraid 6.12 under Network settings: Any help would be greatly appreciated.
-
I ended up moving to the "MariaDB Official" containers, I migrated using HeidiSQL and am now using a seperate container for each database and it has so far been rock solid. I was previously having lock-ups with Nextcloud. This has now gone away!
-
Sorry to post again but I am chasing a possible issue with Nextcloud and trying to make sure the issues is not mariadb related. Is it normal that mariadb logs to a .err file even if running normally?
-
Thanks for the reply, that is a pity! Hopefully newer kernels will add support, in the meanwhile @ich777: funky behavior aside, did you ever get a chance to look at a plugin to add the custom drivers for full support? Thanks again all
-
Came here to ask a similar question to others. I have not had any issues with my MariaDB install that I know of but I happened to check the log and noticed the following about a .err file: ------------------------------------- _ () | | ___ _ __ | | / __| | | / \ | | \__ \ | | | () | |_| |___/ |_| \__/ Brought to you by linuxserver.io ------------------------------------- To support LSIO projects visit: https://www.linuxserver.io/donate/ ------------------------------------- GID/UID ------------------------------------- User uid: 99 User gid: 100 ------------------------------------- [custom-init] no custom files found exiting... [ls.io-init] done. 220711 15:54:26 mysqld_safe Logging to '/config/databases/26dcfea28ad2.err'. 220711 15:54:26 mysqld_safe Starting mariadbd daemon with databases from /config/databases The .err file contains the following: 220711 15:54:26 mysqld_safe Starting mariadbd daemon with databases from /config/databases 2022-07-11 15:54:26 0 [Note] /usr/bin/mariadbd (mysqld 10.5.16-MariaDB-log) starting as process 315 ... 2022-07-11 15:54:26 0 [Note] InnoDB: Uses event mutexes 2022-07-11 15:54:26 0 [Note] InnoDB: Compressed tables use zlib 1.2.12 2022-07-11 15:54:26 0 [Note] InnoDB: Number of pools: 1 2022-07-11 15:54:26 0 [Note] InnoDB: Using crc32 + pclmulqdq instructions 2022-07-11 15:54:26 0 [Note] InnoDB: Using Linux native AIO 2022-07-11 15:54:26 0 [Note] InnoDB: Initializing buffer pool, total size = 268435456, chunk size = 134217728 2022-07-11 15:54:26 0 [Note] InnoDB: Completed initialization of buffer pool 2022-07-11 15:54:26 0 [Note] InnoDB: 128 rollback segments are active. 2022-07-11 15:54:26 0 [Note] InnoDB: Creating shared tablespace for temporary tables 2022-07-11 15:54:26 0 [Note] InnoDB: Setting file './ibtmp1' size to 12 MB. Physically writing the file full; Please wait ... 2022-07-11 15:54:26 0 [Note] InnoDB: File './ibtmp1' size is now 12 MB. 2022-07-11 15:54:26 0 [Note] InnoDB: 10.5.16 started; log sequence number 261866318704; transaction id 208867832 2022-07-11 15:54:26 0 [Note] Plugin 'FEEDBACK' is disabled. 2022-07-11 15:54:26 0 [Note] InnoDB: Loading buffer pool(s) from /config/databases/ib_buffer_pool 2022-07-11 15:54:27 0 [Note] Server socket created on IP: '::'. 2022-07-11 15:54:27 0 [Note] Reading of all Master_info entries succeeded 2022-07-11 15:54:27 0 [Note] Added new Master_info '' to hash table 2022-07-11 15:54:27 0 [Note] /usr/bin/mariadbd: ready for connections. Version: '10.5.16-MariaDB-log' socket: '/run/mysqld/mysqld.sock' port: 3306 MariaDB Server 2022-07-11 15:54:27 0 [Note] InnoDB: Buffer pool(s) load completed at 220711 15:54:27 2022-07-11 15:54:30 4 [Warning] IP address '172.17.0.1' could not be resolved: Name does not resolve 2022-07-11 15:54:33 6 [Warning] IP address '192.168.1.100' could not be resolved: Name does not resolve I can not see any errors there that are concerning, am I missing something or is it normal that MariaDB logs to a .err file even if there are no issues? Thanks for any advice.
-
@dmacias Firstly, thanks so much for your work on this! Secondly (cheekily!), any chance of an update to this plugin? A new official release of NUT has been released (v2.8.0) and among other things, it happens to include a fix an issue with my UPS!! https://github.com/networkupstools/nut/releases/tag/v2.8.0 Thanks again!
-
@ich777 What is the current recommended solution for this? I am running unRAID 6.10.3 on a Gigabyte C246-WU4 motherboard. I have not added acpi_enforce_resources=lax to my syslinux config. I have a sensor with ID 0x8688 not being detected. My results of sensors-detect are as follows: root@Tower:/# sensors-detect # sensors-detect version 3.6.0 # System: Gigabyte Technology Co., Ltd. C246-WU4 [Default string] # Board: Gigabyte Technology Co., Ltd. C246-WU4-CF # Kernel: 5.15.46-Unraid x86_64 # Processor: Intel(R) Core(TM) i9-9900 CPU @ 3.10GHz (6/158/13) This program will help you determine which kernel modules you need to load to use lm_sensors most effectively. It is generally safe and recommended to accept the default answers to all questions, unless you know what you're doing. Some south bridges, CPUs or memory controllers contain embedded sensors. Do you want to scan for them? This is totally safe. (YES/no): Silicon Integrated Systems SIS5595... No VIA VT82C686 Integrated Sensors... No VIA VT8231 Integrated Sensors... No AMD K8 thermal sensors... No AMD Family 10h thermal sensors... No AMD Family 11h thermal sensors... No AMD Family 12h and 14h thermal sensors... No AMD Family 15h thermal sensors... No AMD Family 16h thermal sensors... No AMD Family 17h thermal sensors... No AMD Family 15h power sensors... No AMD Family 16h power sensors... No Hygon Family 18h thermal sensors... No Intel digital thermal sensor... Success! (driver `coretemp') Intel AMB FB-DIMM thermal sensor... No Intel 5500/5520/X58 thermal sensor... No VIA C7 thermal sensor... No VIA Nano thermal sensor... No Some Super I/O chips contain embedded sensors. We have to write to standard I/O ports to probe them. This is usually safe. Do you want to scan for Super I/O sensors? (YES/no): Probing for Super-I/O at 0x2e/0x2f Trying family `National Semiconductor/ITE'... No Trying family `SMSC'... No Trying family `VIA/Winbond/Nuvoton/Fintek'... No Trying family `ITE'... Yes Found unknown chip with ID 0x8688 Probing for Super-I/O at 0x4e/0x4f Trying family `National Semiconductor/ITE'... No Trying family `SMSC'... No Trying family `VIA/Winbond/Nuvoton/Fintek'... No Trying family `ITE'... Yes Found `ITE IT8792E Super IO Sensors' Success! (address 0xa60, driver `it87') Some systems (mainly servers) implement IPMI, a set of common interfaces through which system health data may be retrieved, amongst other things. We first try to get the information from SMBIOS. If we don't find it there, we have to read from arbitrary I/O ports to probe for such interfaces. This is normally safe. Do you want to scan for IPMI interfaces? (YES/no): Probing for `IPMI BMC KCS' at 0xca0... No Probing for `IPMI BMC SMIC' at 0xca8... No Some hardware monitoring chips are accessible through the ISA I/O ports. We have to write to arbitrary I/O ports to probe them. This is usually safe though. Yes, you do have ISA I/O ports even if you do not have any ISA slots! Do you want to scan the ISA I/O ports? (yes/NO): Lastly, we can probe the I2C/SMBus adapters for connected hardware monitoring devices. This is the most risky part, and while it works reasonably well on most systems, it has been reported to cause trouble on some systems. Do you want to probe the I2C/SMBus adapters now? (YES/no): Using driver `i2c-i801' for device 0000:00:1f.4: Cannon Lake-H (PCH) Module i2c-dev loaded successfully. Next adapter: SMBus I801 adapter at efa0 (i2c-0) Do you want to scan it? (yes/NO/selectively): Next adapter: i915 gmbus dpb (i2c-1) Do you want to scan it? (yes/NO/selectively): Next adapter: i915 gmbus dpc (i2c-2) Do you want to scan it? (yes/NO/selectively): Next adapter: i915 gmbus misc (i2c-3) Do you want to scan it? (yes/NO/selectively): Next adapter: i915 gmbus dpd (i2c-4) Do you want to scan it? (yes/NO/selectively): Next adapter: AUX C/DDI C/PHY C (i2c-5) Do you want to scan it? (yes/NO/selectively): Next adapter: AUX D/DDI D/PHY D (i2c-6) Do you want to scan it? (yes/NO/selectively): Now follows a summary of the probes I have just done. Just press ENTER to continue: Driver `coretemp': * Chip `Intel digital thermal sensor' (confidence: 9) Driver `it87': * ISA bus, address 0xa60 Chip `ITE IT8792E Super IO Sensors' (confidence: 9) Do you want to overwrite /etc/sysconfig/lm_sensors? (YES/no): Copy prog/init/lm_sensors.init to /etc/init.d/lm_sensors for initialization at boot time. You should now start the lm_sensors service to load the required kernel modules. Unloading i2c-dev... OK results of sensors command: root@Tower:/# sensors coretemp-isa-0000 Adapter: ISA adapter Package id 0: +65.0°C (high = +86.0°C, crit = +100.0°C) Core 0: +58.0°C (high = +86.0°C, crit = +100.0°C) Core 1: +65.0°C (high = +86.0°C, crit = +100.0°C) Core 2: +57.0°C (high = +86.0°C, crit = +100.0°C) Core 3: +57.0°C (high = +86.0°C, crit = +100.0°C) Core 4: +59.0°C (high = +86.0°C, crit = +100.0°C) Core 5: +57.0°C (high = +86.0°C, crit = +100.0°C) Core 6: +58.0°C (high = +86.0°C, crit = +100.0°C) Core 7: +58.0°C (high = +86.0°C, crit = +100.0°C) nvme-pci-0300 Adapter: PCI adapter Composite: +41.9°C (low = -0.1°C, high = +69.8°C) (crit = +84.8°C) acpitz-acpi-0 Adapter: ACPI interface MB Temp: +27.8°C (crit = +119.0°C) it8792-isa-0a60 Adapter: ISA adapter in0: 1.26 V (min = +0.00 V, max = +2.78 V) in1: 589.00 mV (min = +0.00 V, max = +2.78 V) in2: 1.04 V (min = +0.00 V, max = +2.78 V) +3.3V: 1.67 V (min = +0.00 V, max = +2.78 V) in4: 937.00 mV (min = +0.00 V, max = +2.78 V) in5: 1.50 V (min = +0.00 V, max = +2.78 V) in6: 2.78 V (min = +0.00 V, max = +2.78 V) ALARM 3VSB: 1.66 V (min = +0.00 V, max = +2.78 V) Vbat: 1.61 V Array Fan: 714 RPM (min = 0 RPM) CPU Temp: +41.0°C (low = +127.0°C, high = +127.0°C) sensor = thermistor temp2: -55.0°C (low = +127.0°C, high = +127.0°C) sensor = thermistor temp3: +44.0°C (low = +127.0°C, high = +127.0°C) sensor = thermistor intrusion0: ALARM nvme-pci-0900 Adapter: PCI adapter Composite: +39.9°C (low = -0.1°C, high = +69.8°C) (crit = +84.8°C) pch_cannonlake-virtual-0 Adapter: Virtual device temp1: +61.0°C What is the current recommended solution? Thank for any help!
-
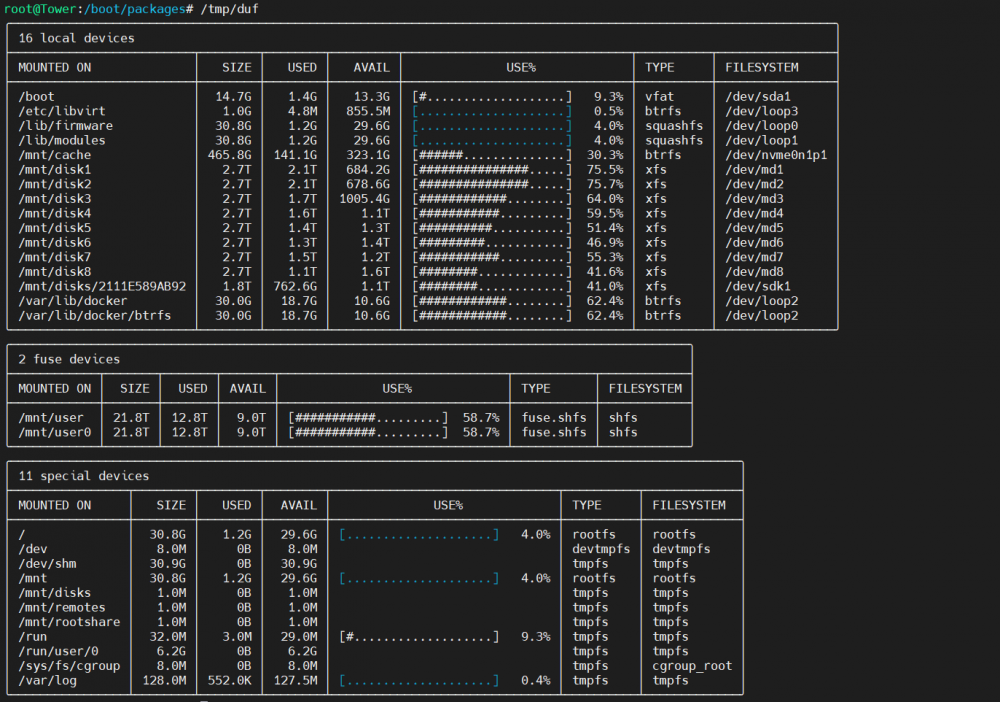
Would it be possible at all to add duf to NerdPack?: It is a much nicer alternative for the "df" tool with brilliant layout for watching disc use & free stage for an OS based on storage: https://github.com/muesli/duf The releases page include a amd64 binary that runs on unRAID without any other dependencies but it not packaged as a .txz: https://github.com/muesli/duf/releases/download/v0.8.1/duf_0.8.1_linux_x86_64.tar.gz I feel it would be a great addition! Thanks so much for all your work!
-
@Martsmac Did you ever get this sorted? I am looking for a USB 3.2 PCI-E card to passthrough to a Windows 10 VM in order to try and use my server for VR. @pinion Did you ever get your card working in unRAID?
-
Sorry to resurrect old thread but this worked for me. Thanks
-
Seems you may be right! 😭 Booted the same unraid hardware with a Windows 10 drive and also got Code 43 errors after driver installation. What a balls! GPUs are just so expensive at the moment. Thanks for your advice
-
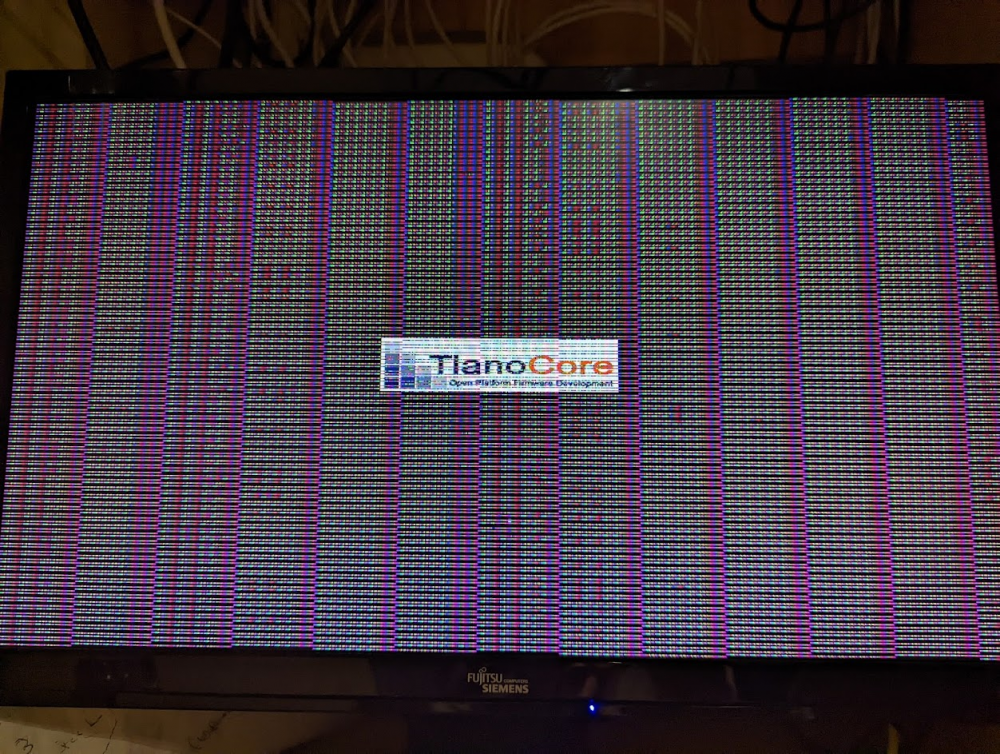
Firstly: Happy New Year unRAID community I would HUGELY appreciate any help that could be offered here: I have been reading all the AMD passthrough threads that I could find but I have gotten incredibly confused by conflicting information and information that is possibly no longer valid as per versions 6.9+. I am swapping the GPU on a Win10 VM from a Nvidia 1050Ti to an AMD RX580 (Gigabyte Aorus RX580 8GB). I am having a lot of difficulty in getting the RX580 reliably passed through: I can get it to boot in the VM with a 800x600 resolution and green/blue artifacts on the screen and I am sometimes get the AMD drivers (latest from AMD website) to correctly install but it inevitably crashes and then reboots to show an "Error Code 43" in the device manager for the card. I have tried completely removing all driver components with DDU in safe mode between attempts but still struggling greatly. I recently had it working but then after a reboot of the server it reverted to Code 43 again! Artifacts disappear in safemode so I am fairly confident they are related to drivers/passthrough. Card is known working as was removed from eGPU enclosure. My Setup: M/B: Gigabyte Technology Co., Ltd. C246-WU4-CF Version x.x - s/n: Default string BIOS: American Megatrends Inc. Version F6g. Dated: 09/16/2020 CPU: Intel® Core™ i9-9900 CPU @ 3.10GHz HVM: Enabled IOMMU: Enabled Cache: 512 KiB, 2 MB, 16 MB Memory: 64 GiB DDR4 (max. installable capacity 64 GiB) Network: bond0: fault-tolerance (active-backup), mtu 1500 eth0: 1000 Mbps, full duplex, mtu 1500 eth1: 1000 Mbps, full duplex, mtu 1500 Kernel: Linux 5.14.15-Unraid x86_64 I have CSM disabled in BIOS as per some posts I read here. I have the AMD Vendor Reset Plugin from @ich777 installed: My System VM Manager Settings are as follows: I have the following VFIO bindings: VM Log: -boot strict=on \ -device pcie-root-port,port=0x8,chassis=1,id=pci.1,bus=pcie.0,multifunction=on,addr=0x1 \ -device pcie-root-port,port=0x9,chassis=2,id=pci.2,bus=pcie.0,addr=0x1.0x1 \ -device pcie-root-port,port=0xa,chassis=3,id=pci.3,bus=pcie.0,addr=0x1.0x2 \ -device pcie-root-port,port=0xb,chassis=4,id=pci.4,bus=pcie.0,addr=0x1.0x3 \ -device pcie-root-port,port=0xc,chassis=5,id=pci.5,bus=pcie.0,addr=0x1.0x4 \ -device pcie-root-port,port=0xd,chassis=6,id=pci.6,bus=pcie.0,addr=0x1.0x5 \ -device pcie-root-port,port=0xe,chassis=7,id=pci.7,bus=pcie.0,addr=0x1.0x6 \ -device pcie-root-port,port=0xf,chassis=8,id=pci.8,bus=pcie.0,addr=0x1.0x7 \ -device pcie-pci-bridge,id=pci.9,bus=pci.1,addr=0x0 \ -device ich9-usb-ehci1,id=usb,bus=pcie.0,addr=0x7.0x7 \ -device ich9-usb-uhci1,masterbus=usb.0,firstport=0,bus=pcie.0,multifunction=on,addr=0x7 \ -device ich9-usb-uhci2,masterbus=usb.0,firstport=2,bus=pcie.0,addr=0x7.0x1 \ -device ich9-usb-uhci3,masterbus=usb.0,firstport=4,bus=pcie.0,addr=0x7.0x2 \ -device virtio-serial-pci,id=virtio-serial0,bus=pci.2,addr=0x0 \ -blockdev '{"driver":"file","filename":"/mnt/disks/CT2000MX500SSD1_2111E589AB92/domains/Windows 10 (BI)/vdisk_new.img","node-name":"libvirt-2-storage","cache":{"direct":false,"no-flush":false},"auto-read-only":true,"discard":"unmap"}' \ -blockdev '{"node-name":"libvirt-2-format","read-only":false,"cache":{"direct":false,"no-flush":false},"driver":"qcow2","file":"libvirt-2-storage","backing":null}' \ -device virtio-blk-pci,bus=pci.4,addr=0x0,drive=libvirt-2-format,id=virtio-disk2,bootindex=1,write-cache=on \ -blockdev '{"driver":"host_device","filename":"/dev/disk/by-id/ata-WDC_WD20PURZ-85AKKY0_WD-WX42D609RS31","node-name":"libvirt-1-storage","cache":{"direct":false,"no-flush":false},"auto-read-only":true,"discard":"unmap"}' \ -blockdev '{"node-name":"libvirt-1-format","read-only":false,"cache":{"direct":false,"no-flush":false},"driver":"raw","file":"libvirt-1-storage"}' \ -device virtio-blk-pci,bus=pci.5,addr=0x0,drive=libvirt-1-format,id=virtio-disk3,write-cache=on \ -netdev tap,fd=39,id=hostnet0 \ -device virtio-net,netdev=hostnet0,id=net0,mac=30:11:d2:80:23:6a,bus=pci.3,addr=0x0 \ -chardev pty,id=charserial0 \ -device isa-serial,chardev=charserial0,id=serial0 \ -chardev socket,id=charchannel0,fd=40,server=on,wait=off \ -device virtserialport,bus=virtio-serial0.0,nr=1,chardev=charchannel0,id=channel0,name=org.qemu.guest_agent.0 \ -device usb-tablet,id=input0,bus=usb.0,port=3 \ -audiodev id=audio1,driver=none \ -device vfio-pci,host=0000:01:00.0,id=hostdev0,bus=pci.6,multifunction=on,addr=0x0,romfile=/mnt/user/Files/VMs/vbios/RX580.Fast.rom \ -device vfio-pci,host=0000:01:00.1,id=hostdev1,bus=pci.6,addr=0x0.0x1 \ -device usb-host,hostdevice=/dev/bus/usb/001/006,id=hostdev2,bus=usb.0,port=1 \ -device usb-host,hostdevice=/dev/bus/usb/001/003,id=hostdev3,bus=usb.0,port=2 \ -sandbox on,obsolete=deny,elevateprivileges=deny,spawn=deny,resourcecontrol=deny \ -msg timestamp=on char device redirected to /dev/pts/2 (label charserial0) 2022-01-01T23:52:10.162457Z qemu-system-x86_64: vfio: Cannot reset device 0000:01:00.1, no available reset mechanism. 2022-01-01T23:52:10.167466Z qemu-system-x86_64: vfio: Cannot reset device 0000:01:00.1, no available reset mechanism. 2022-01-01T23:59:38.988500Z qemu-system-x86_64: vfio: Cannot reset device 0000:01:00.1, no available reset mechanism. 2022-01-01T23:59:38.994580Z qemu-system-x86_64: vfio: Cannot reset device 0000:01:00.1, no available reset mechanism. VM XML: <?xml version='1.0' encoding='UTF-8'?> <domain type='kvm'> <name>Windows 10 BI XML_Edits</name> <uuid>33eb8092-98b7-7fb8-c0c4-219f958f4b13</uuid> <metadata> <vmtemplate xmlns="unraid" name="Windows 10" icon="windows.png" os="windows10"/> </metadata> <memory unit='KiB'>16777216</memory> <currentMemory unit='KiB'>16777216</currentMemory> <memoryBacking> <nosharepages/> </memoryBacking> <vcpu placement='static'>6</vcpu> <cputune> <vcpupin vcpu='0' cpuset='5'/> <vcpupin vcpu='1' cpuset='13'/> <vcpupin vcpu='2' cpuset='6'/> <vcpupin vcpu='3' cpuset='14'/> <vcpupin vcpu='4' cpuset='7'/> <vcpupin vcpu='5' cpuset='15'/> </cputune> <os> <type arch='x86_64' machine='pc-q35-6.1'>hvm</type> <loader readonly='yes' type='pflash'>/usr/share/qemu/ovmf-x64/OVMF_CODE-pure-efi.fd</loader> <nvram>/etc/libvirt/qemu/nvram/33eb8092-98b7-7fb8-c0c4-219f958f4b13_VARS-pure-efi.fd</nvram> </os> <features> <acpi/> <apic/> <hyperv> <relaxed state='on'/> <vapic state='on'/> <spinlocks state='on' retries='8191'/> <vendor_id state='on' value='none'/> </hyperv> </features> <cpu mode='host-passthrough' check='none' migratable='on'> <topology sockets='1' dies='1' cores='3' threads='2'/> <cache mode='passthrough'/> </cpu> <clock offset='localtime'> <timer name='hypervclock' present='yes'/> <timer name='hpet' present='no'/> </clock> <on_poweroff>destroy</on_poweroff> <on_reboot>restart</on_reboot> <on_crash>restart</on_crash> <devices> <emulator>/usr/local/sbin/qemu</emulator> <disk type='file' device='disk'> <driver name='qemu' type='qcow2' cache='writeback'/> <source file='/mnt/disks/CT2000MX500SSD1_2111E589AB92/domains/Windows 10 (BI)/vdisk_new.img'/> <target dev='hdc' bus='virtio'/> <boot order='1'/> <address type='pci' domain='0x0000' bus='0x04' slot='0x00' function='0x0'/> </disk> <disk type='block' device='disk'> <driver name='qemu' type='raw' cache='writeback'/> <source dev='/dev/disk/by-id/ata-WDC_WD20PURZ-85AKKY0_WD-WX42D609RS31'/> <target dev='hdd' bus='virtio'/> <address type='pci' domain='0x0000' bus='0x05' slot='0x00' function='0x0'/> </disk> <controller type='usb' index='0' model='ich9-ehci1'> <address type='pci' domain='0x0000' bus='0x00' slot='0x07' function='0x7'/> </controller> <controller type='usb' index='0' model='ich9-uhci1'> <master startport='0'/> <address type='pci' domain='0x0000' bus='0x00' slot='0x07' function='0x0' multifunction='on'/> </controller> <controller type='usb' index='0' model='ich9-uhci2'> <master startport='2'/> <address type='pci' domain='0x0000' bus='0x00' slot='0x07' function='0x1'/> </controller> <controller type='usb' index='0' model='ich9-uhci3'> <master startport='4'/> <address type='pci' domain='0x0000' bus='0x00' slot='0x07' function='0x2'/> </controller> <controller type='pci' index='0' model='pcie-root'/> <controller type='pci' index='1' model='pcie-root-port'> <model name='pcie-root-port'/> <target chassis='1' port='0x8'/> <address type='pci' domain='0x0000' bus='0x00' slot='0x01' function='0x0' multifunction='on'/> </controller> <controller type='pci' index='2' model='pcie-root-port'> <model name='pcie-root-port'/> <target chassis='2' port='0x9'/> <address type='pci' domain='0x0000' bus='0x00' slot='0x01' function='0x1'/> </controller> <controller type='pci' index='3' model='pcie-root-port'> <model name='pcie-root-port'/> <target chassis='3' port='0xa'/> <address type='pci' domain='0x0000' bus='0x00' slot='0x01' function='0x2'/> </controller> <controller type='pci' index='4' model='pcie-root-port'> <model name='pcie-root-port'/> <target chassis='4' port='0xb'/> <address type='pci' domain='0x0000' bus='0x00' slot='0x01' function='0x3'/> </controller> <controller type='pci' index='5' model='pcie-root-port'> <model name='pcie-root-port'/> <target chassis='5' port='0xc'/> <address type='pci' domain='0x0000' bus='0x00' slot='0x01' function='0x4'/> </controller> <controller type='pci' index='6' model='pcie-root-port'> <model name='pcie-root-port'/> <target chassis='6' port='0xd'/> <address type='pci' domain='0x0000' bus='0x00' slot='0x01' function='0x5'/> </controller> <controller type='pci' index='7' model='pcie-root-port'> <model name='pcie-root-port'/> <target chassis='7' port='0xe'/> <address type='pci' domain='0x0000' bus='0x00' slot='0x01' function='0x6'/> </controller> <controller type='pci' index='8' model='pcie-root-port'> <model name='pcie-root-port'/> <target chassis='8' port='0xf'/> <address type='pci' domain='0x0000' bus='0x00' slot='0x01' function='0x7'/> </controller> <controller type='pci' index='9' model='pcie-to-pci-bridge'> <model name='pcie-pci-bridge'/> <address type='pci' domain='0x0000' bus='0x01' slot='0x00' function='0x0'/> </controller> <controller type='virtio-serial' index='0'> <address type='pci' domain='0x0000' bus='0x02' slot='0x00' function='0x0'/> </controller> <controller type='sata' index='0'> <address type='pci' domain='0x0000' bus='0x00' slot='0x1f' function='0x2'/> </controller> <interface type='bridge'> <mac address='30:11:d2:80:23:6a'/> <source bridge='br0'/> <model type='virtio-net'/> <address type='pci' domain='0x0000' bus='0x03' slot='0x00' function='0x0'/> </interface> <serial type='pty'> <target type='isa-serial' port='0'> <model name='isa-serial'/> </target> </serial> <console type='pty'> <target type='serial' port='0'/> </console> <channel type='unix'> <target type='virtio' name='org.qemu.guest_agent.0'/> <address type='virtio-serial' controller='0' bus='0' port='1'/> </channel> <input type='tablet' bus='usb'> <address type='usb' bus='0' port='3'/> </input> <input type='mouse' bus='ps2'/> <input type='keyboard' bus='ps2'/> <audio id='1' type='none'/> <hostdev mode='subsystem' type='pci' managed='yes'> <driver name='vfio'/> <source> <address domain='0x0000' bus='0x01' slot='0x00' function='0x0'/> </source> <rom file='/mnt/user/Files/VMs/vbios/RX580.Fast.rom'/> <address type='pci' domain='0x0000' bus='0x06' slot='0x00' function='0x0' multifunction='on'/> </hostdev> <hostdev mode='subsystem' type='pci' managed='yes'> <driver name='vfio'/> <source> <address domain='0x0000' bus='0x01' slot='0x00' function='0x1'/> </source> <address type='pci' domain='0x0000' bus='0x06' slot='0x00' function='0x1'/> </hostdev> <hostdev mode='subsystem' type='usb' managed='no'> <source> <vendor id='0x413c'/> <product id='0x2003'/> </source> <address type='usb' bus='0' port='1'/> </hostdev> <hostdev mode='subsystem' type='usb' managed='no'> <source> <vendor id='0x413c'/> <product id='0x3012'/> </source> <address type='usb' bus='0' port='2'/> </hostdev> <memballoon model='none'/> </devices> </domain> NOTE: I have tried it both with and without vbios files as I have read conflicting reports of their importance for AMD cards. I have ran a vbios file that I dumped myself via @SpaceInvaderOne script and have ran ones downloaded from techpowerup.com There has been no difference in success either way. I have nothing special in my syslinux.cfg: kernel /bzimage append isolcpus=5-7,13-15 pcie_acs_override=downstream initrd=/bzroot Diagnostics attached also: Thanks so much for any advice! tower-diagnostics-20220102-0013.zip


-
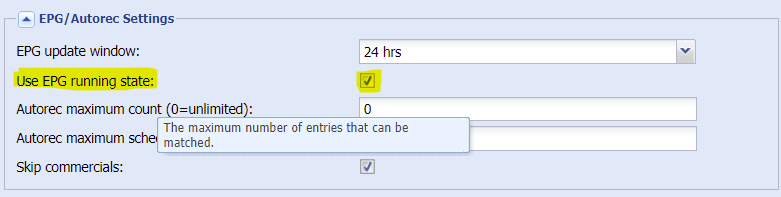
Update to this issue incase anyone else faces a similar issue: Took me longer than it should have to figure this out. The recording issue was based on EIT (programme runtime) setting in recorder: This should be set to DISABLED in my case, there is some issue in getting this EPG data. Disabling "Use EPG running state" fixes it in my case. Thanks to all devs